Apache ZooKeeper — Internal Architecture
A developer's guide to how ZooKeeper actually works under the hood: the ensemble and quorums, the znode data model, the ZAB consensus protocol, the write and read paths, sessions and watches, and how it persists and recovers state.
Apache ZooKeeper is a small, strongly-consistent coordination service — the kernel that other distributed systems build on for the hard problems they would rather not solve themselves: leader election, configuration, distributed locking, group membership, and service discovery. It deliberately does very little. It exposes a tiny filesystem-like API over a tree of small data nodes, guarantees that every server in the cluster sees updates in the same total order, and lets clients put watches on nodes to be notified of change. Everything else — locks, queues, barriers, leader election — is a recipe built on those primitives. Understanding ZooKeeper means understanding two things: the data model clients see, and the ZAB protocol that keeps every replica's copy of that data in agreement.
Contents
1. Design Goals and Core Ideas
ZooKeeper's design is shaped by a refusal to be a general-purpose database. It is a coordination kernel, and every decision serves that narrow goal. Keeping these in mind makes the rest predictable.
| Goal | How ZooKeeper achieves it |
|---|---|
| Strong consistency | All writes go through a single leader and are committed in a strict total order (the zxid sequence). Every server applies them in the same order. |
| Small, simple API | A hierarchical namespace of znodes with a handful of operations (create, delete, setData, getData, getChildren, exists) plus one-shot watches. |
| High read throughput | Reads are served entirely from each server's in-memory copy of the tree — no quorum, no disk. The whole dataset is kept in RAM. |
| High availability | A replicated ensemble. As long as a majority of servers are up, the service stays available and survives a minority of failures. |
| Liveness primitives | Ephemeral znodes tied to client sessions make it trivial to detect when a participant has gone away — the foundation of locks and membership. |
ZooKeeper is a CP system in CAP terms: it favors consistency and partition tolerance. If a server cannot reach a quorum, it stops serving writes rather than risk divergence. It is built for small amounts of critical metadata read and watched by many clients — not for bulk data.
2. Architecture: The Ensemble
A ZooKeeper deployment is a small cluster called an ensemble (typically 3, 5, or 7 servers). Unlike a fully peer-to-peer system, the ensemble has roles. At any moment exactly one server is the leader; the rest are followers. The leader is the single serialization point for all writes; followers replicate the leader's stream and serve reads locally. An optional third role, the observer, replicates state and serves reads but does not vote — letting you scale read capacity without enlarging the quorum.
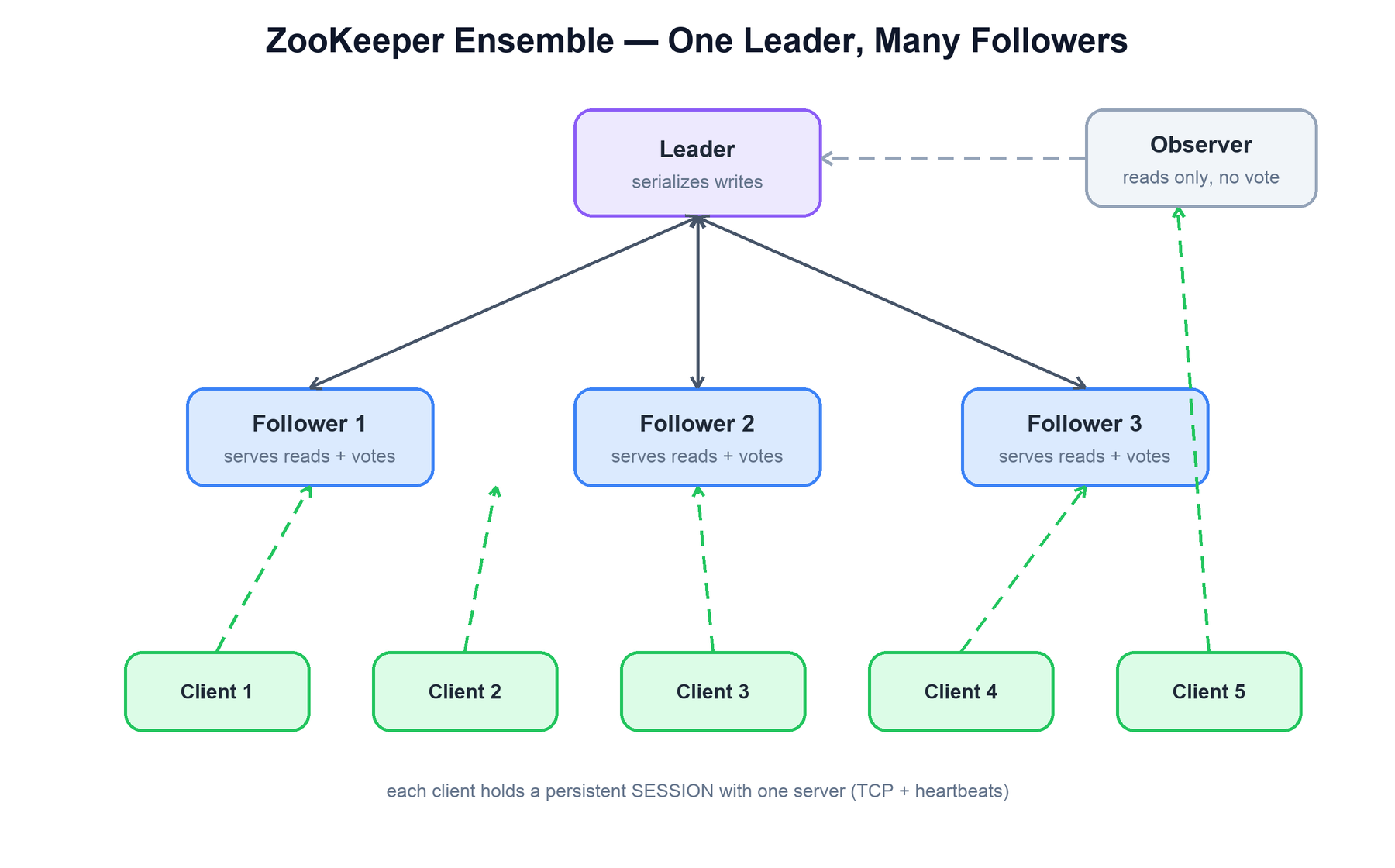
The pieces that make this work:
- Leader: elected by the ensemble. It assigns every write a globally ordered transaction id (
zxid), proposes it to followers, and commits it once a quorum acknowledges. There is exactly one leader at a time. - Followers: replicate the leader's transaction stream, vote in elections and on proposals, and answer client reads from their local in-memory tree. A follower forwards any write it receives to the leader.
- Observers: like followers but non-voting. They hear committed transactions and serve reads, so adding them increases read throughput without slowing down the quorum (a larger voting set means more acks per write).
- Sessions: a client connects to one server and establishes a stateful session over TCP, kept alive by periodic heartbeats. The session — not the connection — is the unit of identity; it can survive reconnection to a different server.
3. Quorums and Why Odd Numbers
ZooKeeper's consistency rests on the quorum: a write is only committed once a majority of voting servers have logged it. Because any two majorities of the same set must overlap on at least one server, no two conflicting decisions can ever both reach quorum. This is what guarantees a single, agreed-upon history even across leader changes.
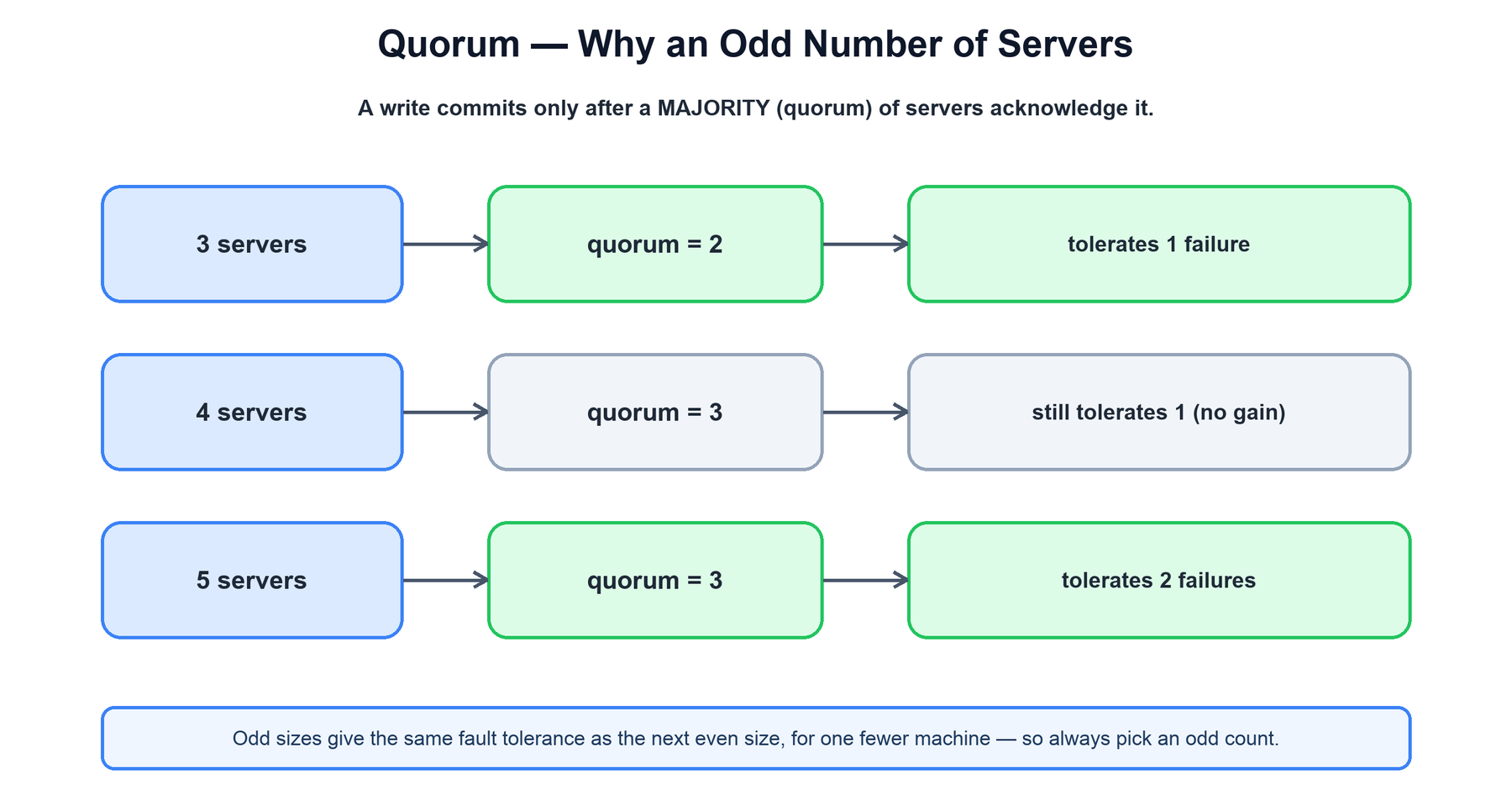
An ensemble of 2f + 1 servers tolerates f failures, because f + 1 survivors still form a majority. The reason for odd sizes is purely about efficiency: a 4-node ensemble needs a quorum of 3 and tolerates only 1 failure — exactly the same fault tolerance as a 3-node ensemble, but at a higher cost and with a larger quorum to coordinate on every write. Worse, an even split is more exposed to a network partition cutting the cluster into two equal halves, neither of which can form a majority. Odd numbers avoid all of this.
4. Data Model: znodes and the Namespace
ZooKeeper presents data as a hierarchical namespace very much like a filesystem. Every node in the tree is called a znode and is addressed by an absolute, slash-separated path such as /app/servers/host-A. The crucial difference from a real filesystem is that every znode can hold both data and children — there is no distinction between files and directories.
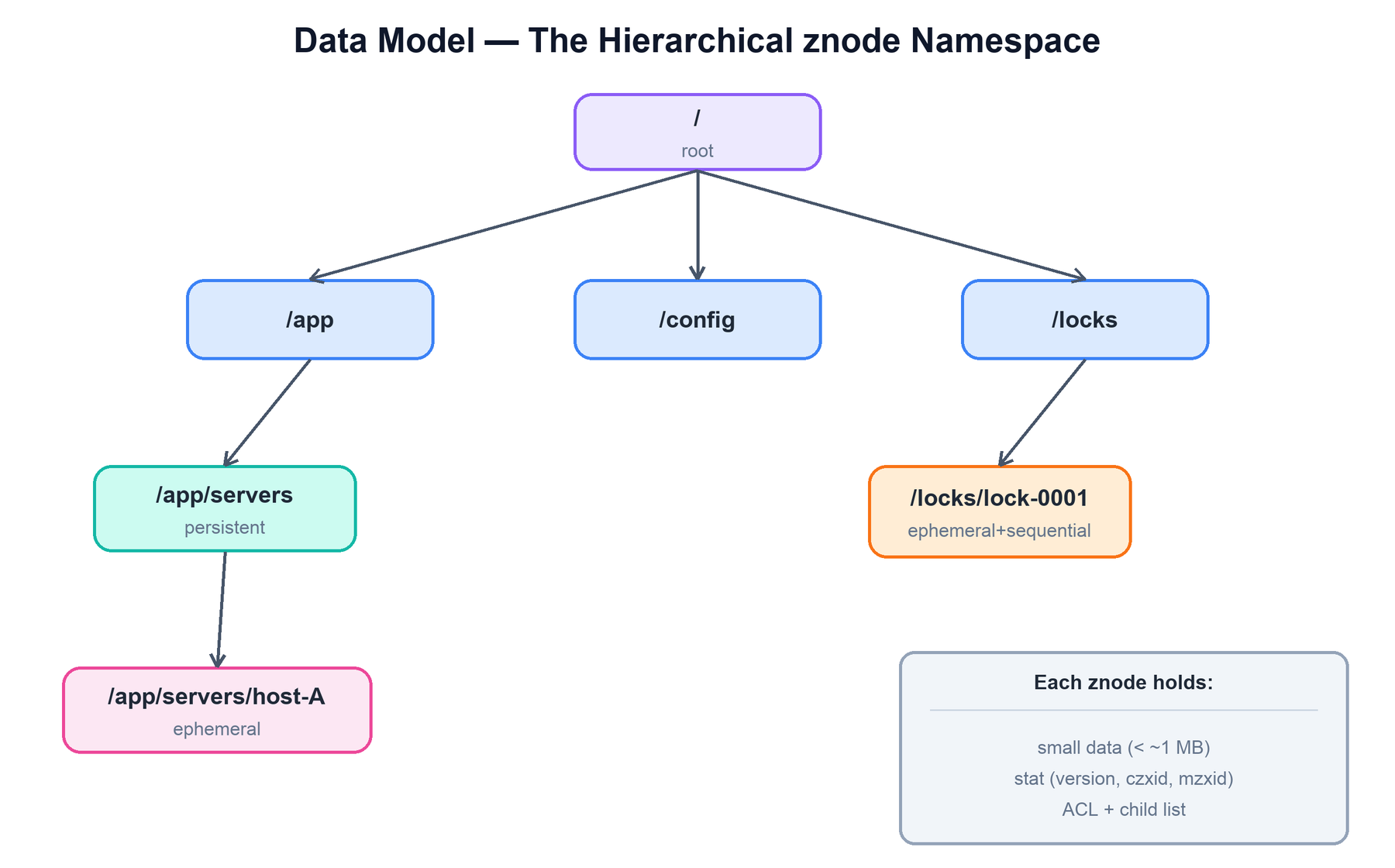
Two properties of the model matter for how you use it:
- Small data. Each znode stores a small byte payload — by default capped at roughly 1 MB, but in practice you store a few hundred bytes (a hostname, a config value, a lock holder's id). ZooKeeper is metadata, not bulk storage; the entire tree lives in memory on every server.
- Rich stat metadata. Every znode carries a stat structure: data and child version numbers, ACLs, timestamps, and the zxids of its creation (
czxid) and last modification (mzxid). The version number powers optimistic concurrency — asetDatacan require an expected version and fail if another client changed the node first.
5. znode Types and Watches
znodes come in flavors, set at creation time, and these flavors are what make coordination recipes possible.
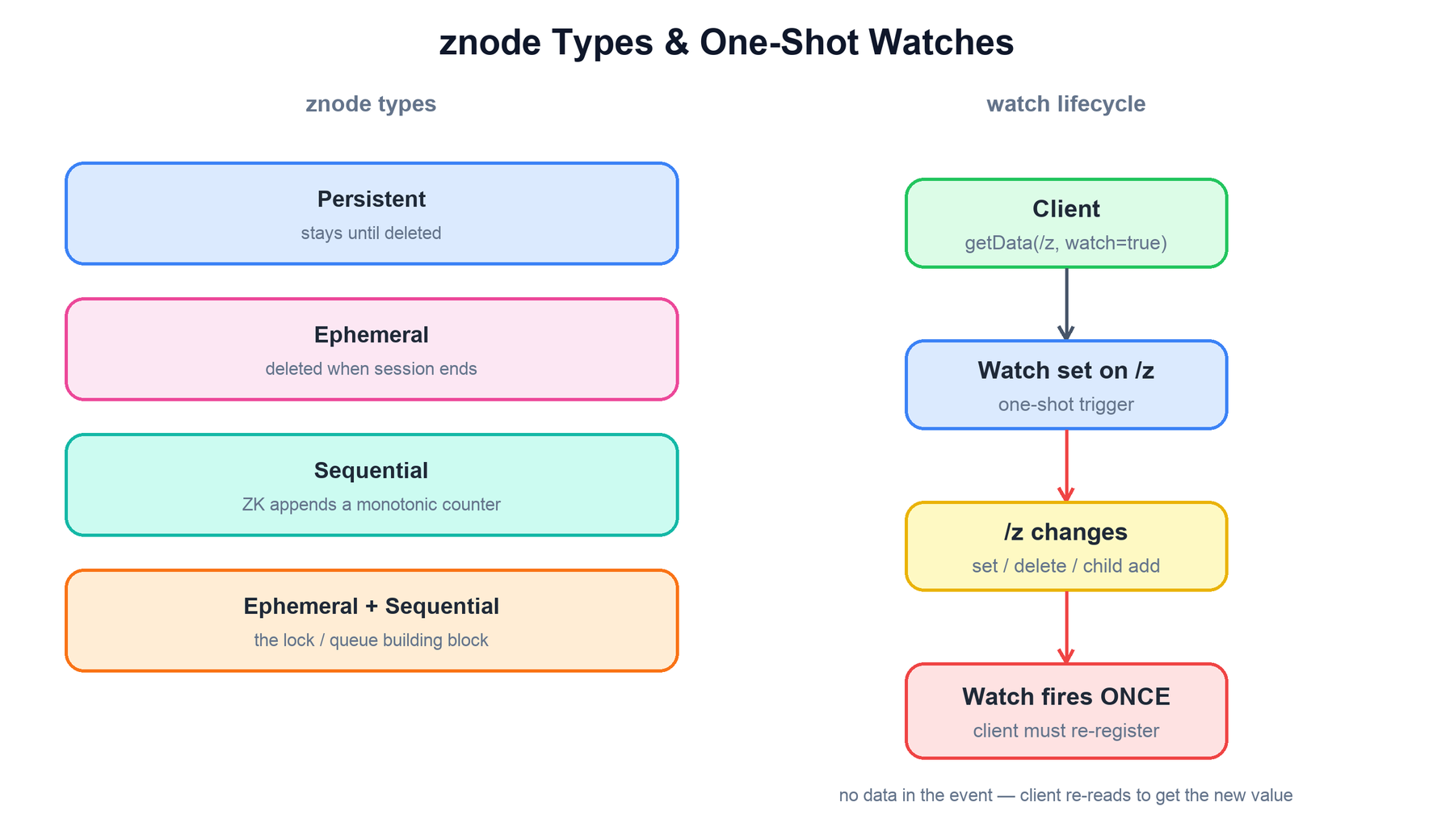
| Type | Lifetime / behavior |
|---|---|
| Persistent | Exists until explicitly deleted. The default. Used for config and durable structure. |
| Ephemeral | Tied to the creating client's session. ZooKeeper deletes it automatically when that session ends (clean close or expiry). Cannot have children. |
| Sequential | ZooKeeper appends a monotonically increasing 10-digit counter to the name on creation, e.g. lock-0000000007. The counter is per-parent and never reused. |
| Ephemeral + Sequential | The combination that powers locks, queues, and leader election: each participant creates one, the ordering is the sequence number, and liveness is the ephemerality. |
A watch is a one-time subscription to a change on a znode. A client sets a watch by passing a flag on a read operation (getData, exists, getChildren). When the watched znode is changed — its data is set, it is deleted, or its child list changes — ZooKeeper sends the client a single notification, then the watch is gone. There are three things to internalize:
- One-shot. A watch fires at most once. To keep watching, the client must re-register a new watch, usually inside the handler for the previous one.
- No payload. The notification says what kind of change happened and on which path, but not the new value. The client re-reads the znode to learn the current state (and re-arm the watch in the same call).
- Ordering guarantee. A client sees the watch event for a change before it sees the new data of any later change, so it can never act on stale data without first being told it is stale.
6. The ZAB Protocol
The engine that keeps every replica's copy of the tree identical is ZAB — the ZooKeeper Atomic Broadcast protocol. ZAB is not Paxos, though it solves a related problem; it is a primary-backup atomic broadcast designed specifically so that a recovered ensemble re-applies exactly the same prefix of transactions in exactly the same order. It runs in two modes that alternate: leader election / recovery, and broadcast.
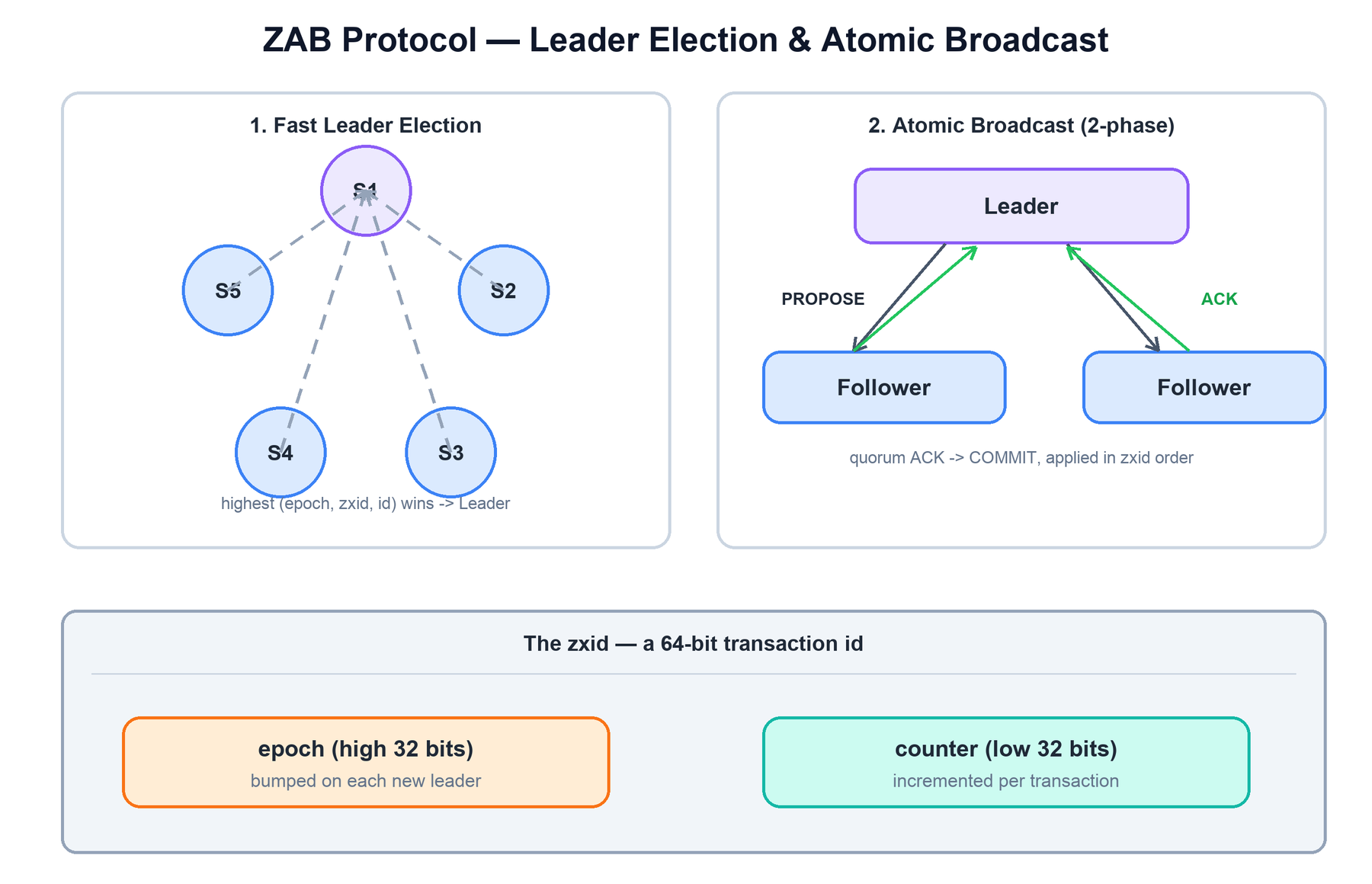
The zxid
Everything in ZAB is ordered by the zxid (ZooKeeper transaction id), a 64-bit number split into two halves. The high 32 bits are the epoch — incremented every time a new leader is elected. The low 32 bits are a counter that the leader increments for each transaction it proposes within its epoch. Comparing zxids is just comparing 64-bit integers: a higher epoch always wins, and within an epoch the higher counter wins. This single number is how servers decide who has the most recent state and how they re-apply history deterministically.
Leader election (Fast Leader Election)
When a server starts, or loses contact with the current leader, the ensemble runs Fast Leader Election. Each server votes for a candidate and broadcasts that vote; servers update their own vote toward whoever has the most up-to-date history. The comparison key is (epoch, last-zxid, server-id) — the server with the highest last-committed zxid wins, because choosing the most current server guarantees no committed transaction is lost. Once a server sees a quorum agree on the same candidate, that candidate becomes leader.
Recovery and atomic broadcast
Before serving writes, a new leader synchronizes followers up to its own history (the recovery phase), establishing a clean starting point in a new epoch. Then it enters broadcast mode, where every write is a two-phase commit:
- The leader assigns the write the next zxid and sends a PROPOSE to all followers.
- Each follower writes the proposal to its transaction log (with an fsync) and replies ACK.
- Once a quorum has acked, the leader broadcasts COMMIT, and every server applies the change to its in-memory tree in zxid order.
# Leader broadcast loop (simplified)
function broadcast(txn):
zxid = (current_epoch << 32) | (++counter) # total order
proposal = (zxid, txn)
log.append(proposal); fsync() # leader logs first
for f in followers:
send(f, PROPOSE, proposal)
wait until acks >= quorum # majority of voters
for f in followers:
send(f, COMMIT, zxid)
apply_to_memory(txn) # in zxid order, on every server7. Write Path
Because there is exactly one leader, the write path always converges on it. A client may be connected to any server, but only the leader can originate a transaction, so a write received by a follower is forwarded.
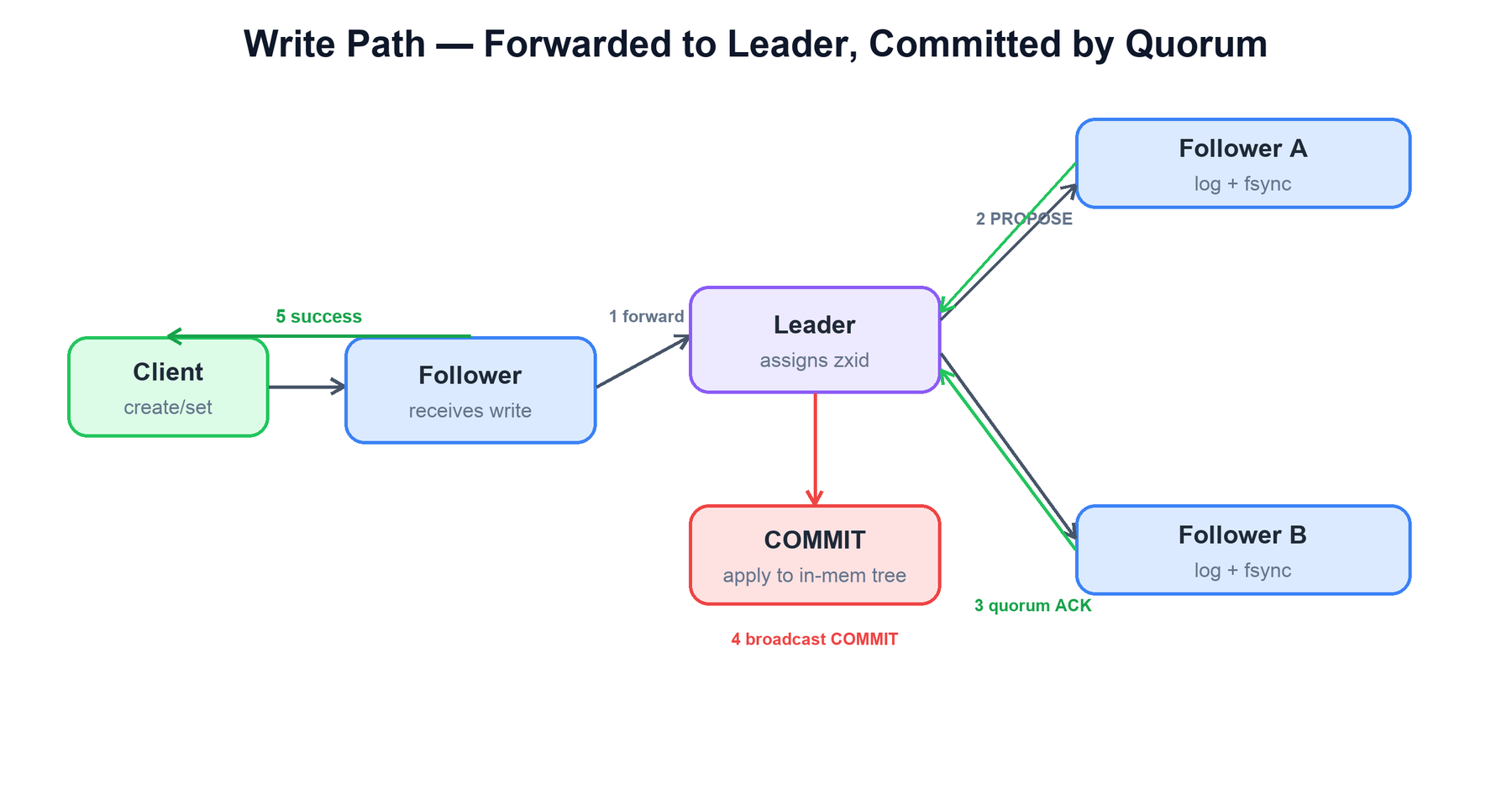
The end-to-end sequence for a create or setData:
- The client sends the write to its connected server.
- If that server is a follower, it forwards the request to the leader.
- The leader assigns the next zxid and sends a PROPOSE to all followers, logging it durably itself.
- Each follower fsyncs the proposal to its transaction log and returns an ACK.
- On a quorum of acks, the leader sends COMMIT; every server applies the change to its in-memory tree, and the originating server replies success to the client.
# From the client's connected server's perspective
function handle_write(req):
if not is_leader:
forward_to_leader(req) # followers cannot originate writes
zxid, ok = leader.propose_and_commit(req) # PROPOSE -> quorum ACK -> COMMIT
if ok:
apply_to_memory(req) # applied in zxid order, everywhere
return SUCCESS(zxid)
return FAILED # e.g. no quorum reachableThe key durability point: a follower must persist a proposal to disk (fsync) before acking it. Combined with the quorum rule, this guarantees that any committed transaction survives the failure of a minority of servers — it is already on stable storage on a majority.
8. Read Path and Consistency
Reads are where ZooKeeper gets its throughput. A read never involves the leader or a quorum: the server the client is connected to answers directly from its in-memory copy of the tree. This makes reads extremely fast and lets read capacity scale by adding followers and observers.
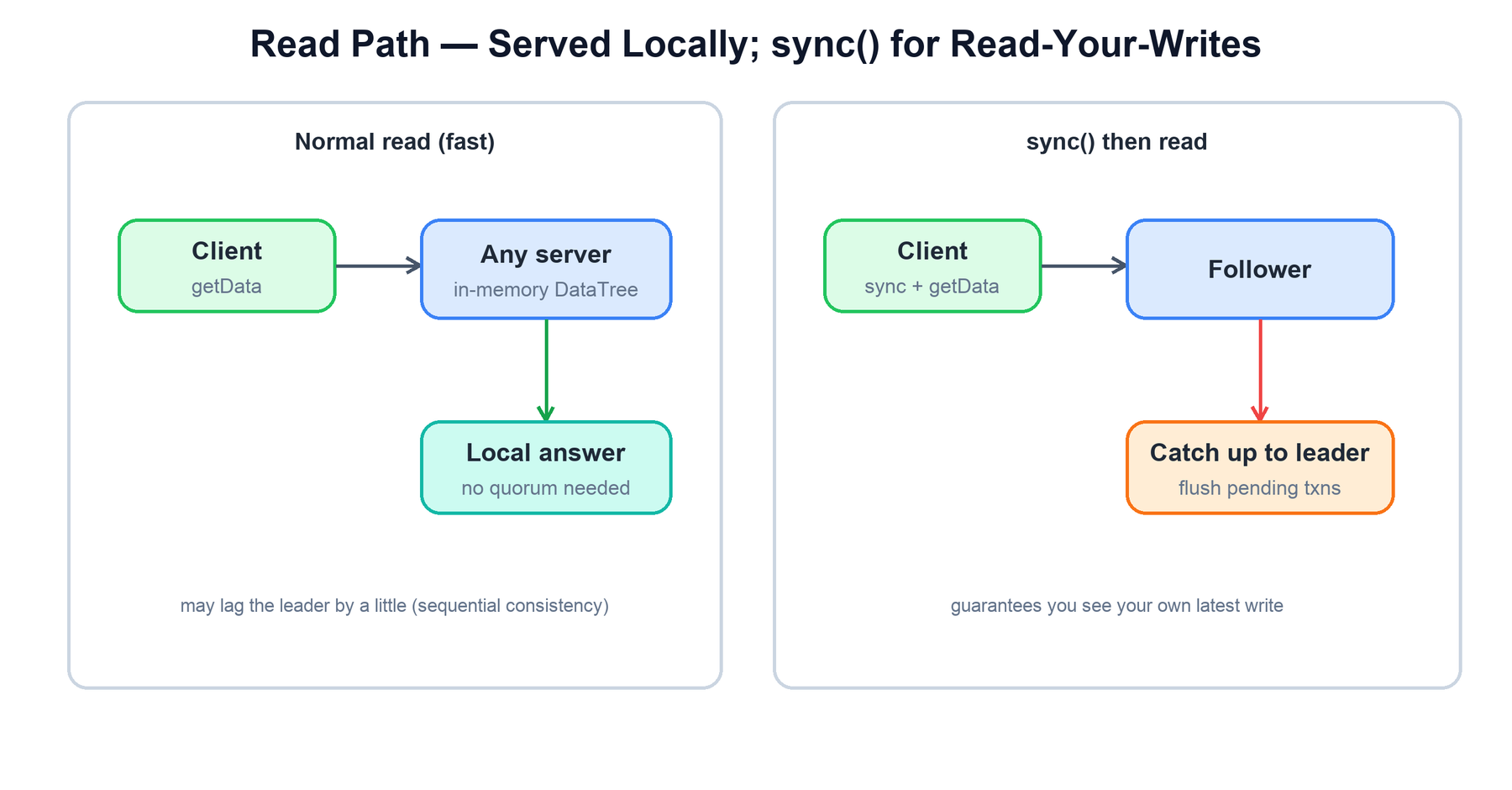
sync() before a read forces the server to catch up, giving read-your-writes.The cost of that speed is the precise consistency model. ZooKeeper guarantees sequential consistency: a single client's operations are applied in the order it issued them, and all clients see writes in the same total order. But it does not guarantee that a read reflects the absolute latest committed write across the whole ensemble. A follower may be a few transactions behind the leader, so a client reading from a lagging follower can momentarily see a slightly stale value.
When read-your-writes (or read-after-write) freshness is required, the client calls sync(). sync() is a request that flushes through the leader's pipeline; once it returns, the connected server has applied everything up to that point, so a subsequent read on the same connection is guaranteed to see the client's own latest write and anything ordered before it.
# Normal read: fast, may be slightly stale
value = server.local_tree.get("/config") # no quorum, no leader
# Read-your-writes: force the server to catch up first
server.sync("/config") # flush through the leader; wait until applied
value = server.local_tree.get("/config") # now guaranteed current9. Sessions and Ephemeral Nodes
A session is the heartbeat of ZooKeeper's liveness machinery. When a client connects, it negotiates a session with a timeout. The client keeps the session alive by sending periodic heartbeats (ping requests) — if it has no other traffic, it pings at roughly a third of the timeout so there is margin to retry. If the server hears nothing for longer than the timeout, it declares the session expired.
Session expiry is the mechanism that gives ephemeral znodes their power. When a session expires, ZooKeeper automatically deletes every ephemeral znode that session created, and fires the watches on them. That single guarantee — "your node disappears when you die" — is what turns ZooKeeper into a liveness detector:
- Membership: each process creates an ephemeral node under a group path. The live membership is just the current children of that path; a crashed process's node vanishes on its own.
- Locks and leader election: the lock holder or leader is identified by an ephemeral node. If it dies, the node disappears, and the waiting clients (who hold watches) are notified to contend again.
- Failure detection without polling: instead of every client probing every other client, ZooKeeper centralizes liveness in session timeouts and pushes change via watches.
Sessions are resilient to network blips. Because session identity is independent of any single TCP connection, a client that loses its connection can reconnect — to a different server — and resume the same session as long as it does so before the timeout elapses. The ephemeral nodes and watches survive the reconnect. Only when the timeout is genuinely exceeded does the session expire and the cleanup happen.
# Server-side session bookkeeping (conceptual)
on heartbeat(session_id):
sessions[session_id].deadline = now + sessions[session_id].timeout
every tick:
for s in sessions:
if now > s.deadline:
for znode in ephemerals_owned_by(s):
delete(znode) # a committed write -> fires watches
expire(s) # watchers learn the holder is gone10. Persistence and Recovery
Although ZooKeeper serves everything from memory, it must not lose committed data when a server restarts. It achieves durability with the same pattern as a database: a write-ahead transaction log for every commit, plus periodic snapshots of the full in-memory tree to bound recovery time.
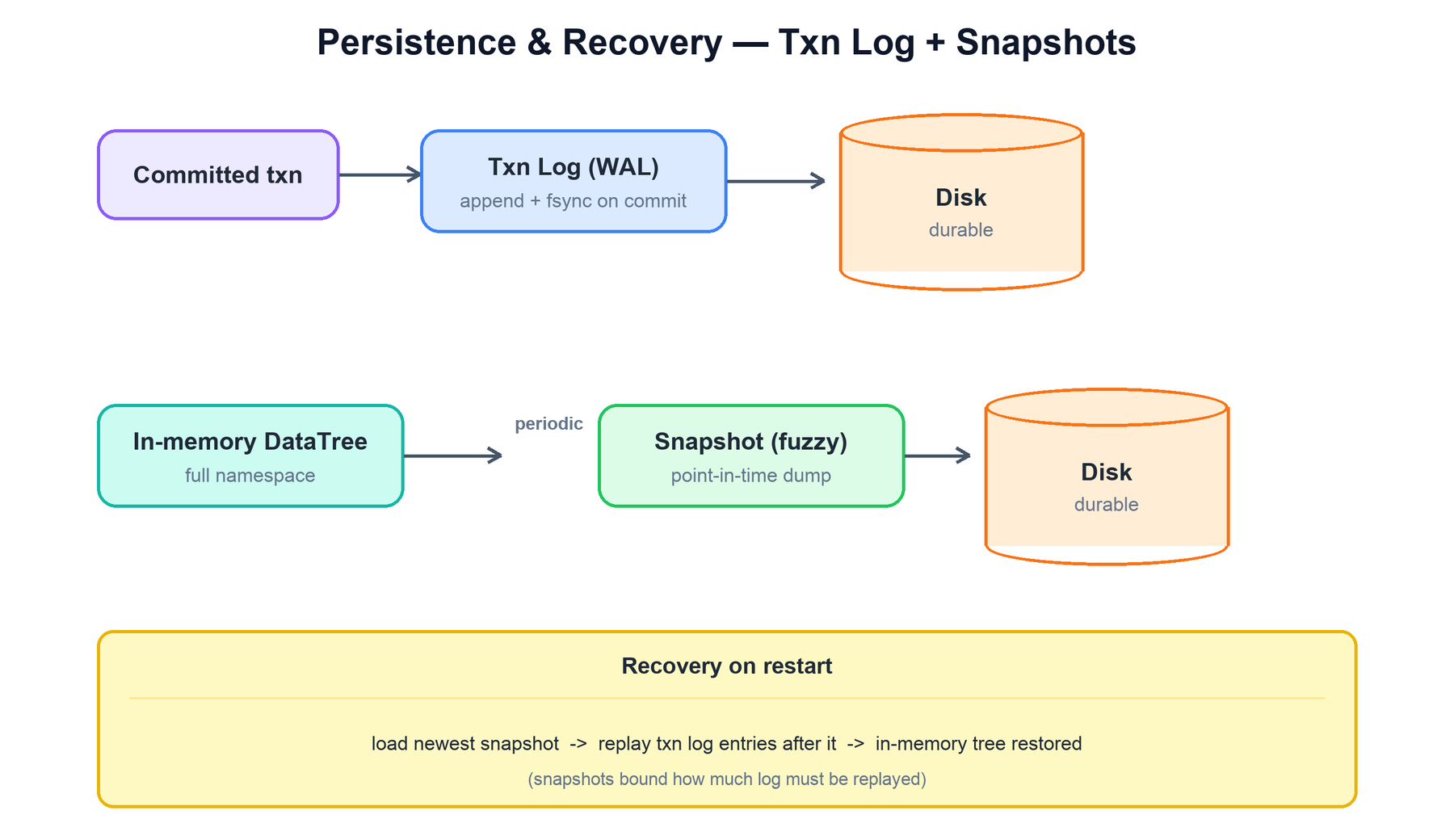
- Transaction log (WAL): before a server acks a proposal, it appends the transaction to its log and fsyncs to disk. This is the durability guarantee — a committed transaction is on stable storage on a quorum of servers. The log is the authoritative, ordered record of every change.
- Snapshots: periodically, a server serializes its entire in-memory DataTree to a snapshot file. ZooKeeper uses a fuzzy snapshot — it does not pause writes while dumping, so the snapshot may be slightly inconsistent, but that is fine because the transaction log is replayed over it on recovery and the operations are idempotent in zxid order.
On restart, recovery is mechanical:
- Load the most recent valid snapshot to reconstruct an approximate tree.
- Replay the transaction log entries with a zxid greater than the snapshot's, in order, applying each to the tree.
- The in-memory state is now exactly the committed history, and the server can rejoin the ensemble (syncing any transactions it missed from the leader).
on server start:
tree = load_latest_snapshot() # fuzzy, point-in-time
for txn in txn_log.entries_after(tree.last_zxid):
apply(tree, txn) # deterministic, in zxid order
rejoin_ensemble() # leader streams any newer txns
# snapshots bound how much log must be replayed; older logs can be purged11. Classic Recipes
ZooKeeper itself provides no lock object, no queue, no "elect a leader" call. Instead these are recipes — conventions composed from znode types and watches. The same two ingredients recur: ephemeral+sequential nodes for ordering and liveness, and watches for notification without polling.

| Recipe | How it is built |
|---|---|
| Distributed lock | Each contender creates an ephemeral+sequential child under /lock. The one with the lowest sequence number holds the lock. Each other waiter sets a watch on the node immediately ahead of it (not on the whole list, to avoid a herd) and acquires the lock when that node disappears. |
| Leader election | Identical to a lock: the contender with the lowest sequence number is the leader. If the leader's session dies, its ephemeral node vanishes, the next-lowest node is notified by its watch, and it becomes leader. |
| Configuration / discovery | Store config in a znode; clients read it with a watch. When the value changes, the watch fires, clients re-read and reload — no polling. Service discovery is the same idea with ephemeral nodes for live instances. |
| Group membership | Each member creates an ephemeral node under a group path; the live set is the children. Membership self-heals because crashed members' nodes are removed on session expiry. |
The "watch only the node just ahead of you" trick in the lock recipe is worth highlighting: it avoids the herd effect, where a single release wakes every waiter at once. By chaining watches, exactly one waiter is notified per release.
# Distributed lock recipe
function acquire_lock():
me = create("/lock/n-", EPHEMERAL | SEQUENTIAL) # e.g. /lock/n-0000000042
while true:
children = sorted(get_children("/lock"))
if me == children[0]:
return HELD # lowest sequence number -> lock is mine
prev = node_just_before(me, children)
if exists(prev, watch=true): # watch only my predecessor
wait_for_watch() # woken when predecessor releases / dies
# loop: recheck whether I am now lowest12. Summary
ZooKeeper is small on purpose. A few reinforcing ideas account for the whole system:
| Concern | Mechanism |
|---|---|
| What does a client see? | A hierarchical tree of small znodes with versioned stat metadata and one-shot watches. |
| How is consistency maintained? | A single leader plus the ZAB atomic-broadcast protocol; every server applies transactions in zxid order. |
| What guarantees a single history? | Quorum (majority) commit — any two majorities overlap, so no divergence. Odd ensemble sizes for efficient fault tolerance. |
| Why are reads fast? | They are served from each server's in-memory tree; no leader, no quorum. sync() when you need read-your-writes. |
| How is liveness detected? | Sessions with heartbeats; ephemeral znodes that vanish on expiry, firing watches. |
| How is data made durable? | Write-ahead transaction log (fsync) plus periodic snapshots; replay on restart. |
| How are coordination problems solved? | Recipes — locks, leader election, membership, config — built from ephemeral+sequential znodes and watches. |