Designing a Video Platform
A system design interview walkthrough for a YouTube-style service: how a raw upload becomes a watchable video, why transcoding is modeled as a directed acyclic graph, how the orchestration and worker pools are organized, and how a CDN serves the result to a global audience.
A video platform looks deceptively simple from the outside: someone uploads a file, other people press play. Underneath, two very different flows have to work well at scale. The upload and processing flow takes a large, arbitrarily-formatted source file and turns it into many playable renditions; it is write-heavy, bursty, and compute-intensive. The streaming flow delivers those renditions to viewers; it is overwhelmingly read-heavy, latency-sensitive, and global. Almost every interesting decision in the design comes from treating these two flows separately and connecting them with durable storage and a CDN. This guide builds the system up flow by flow, leaning on the same handful of ideas — decoupling, parallelism, and pushing bytes close to the viewer.
Contents
1. Requirements and Scale
Before drawing boxes, pin down what the system must do and what shape the load takes. A video platform is defined far more by its access pattern than by its feature list, and that pattern drives nearly every later choice.
| Requirement | What it implies for the design |
|---|---|
| Read-dominated | Views vastly outnumber uploads. The streaming path must be cheap and fast per request, which points straight at caching and a CDN rather than serving bytes from origin storage. |
| Global audience | Viewers are everywhere, so content must be served from edge locations near them. Round-trips to a single region would dominate startup latency. |
| Very large files | Source uploads can be gigabytes. Uploads need resumability, direct-to-storage paths, and processing that does not load whole files into a single machine's memory. |
| Many devices and networks | Phones, TVs, browsers, and flaky connections all need different resolutions, bitrates, and codecs — the core reason transcoding exists. |
| Two distinct flows | Upload/processing (write-heavy, compute-heavy) and streaming (read-heavy, latency-sensitive) are designed and scaled independently. |
2. The Upload Flow and Architecture
The upload flow is the spine of the system. A client sends a raw file; the platform stores it durably, records metadata, transcodes it into playable formats, and finally exposes those formats through a CDN. The architecture below shows the moving parts.
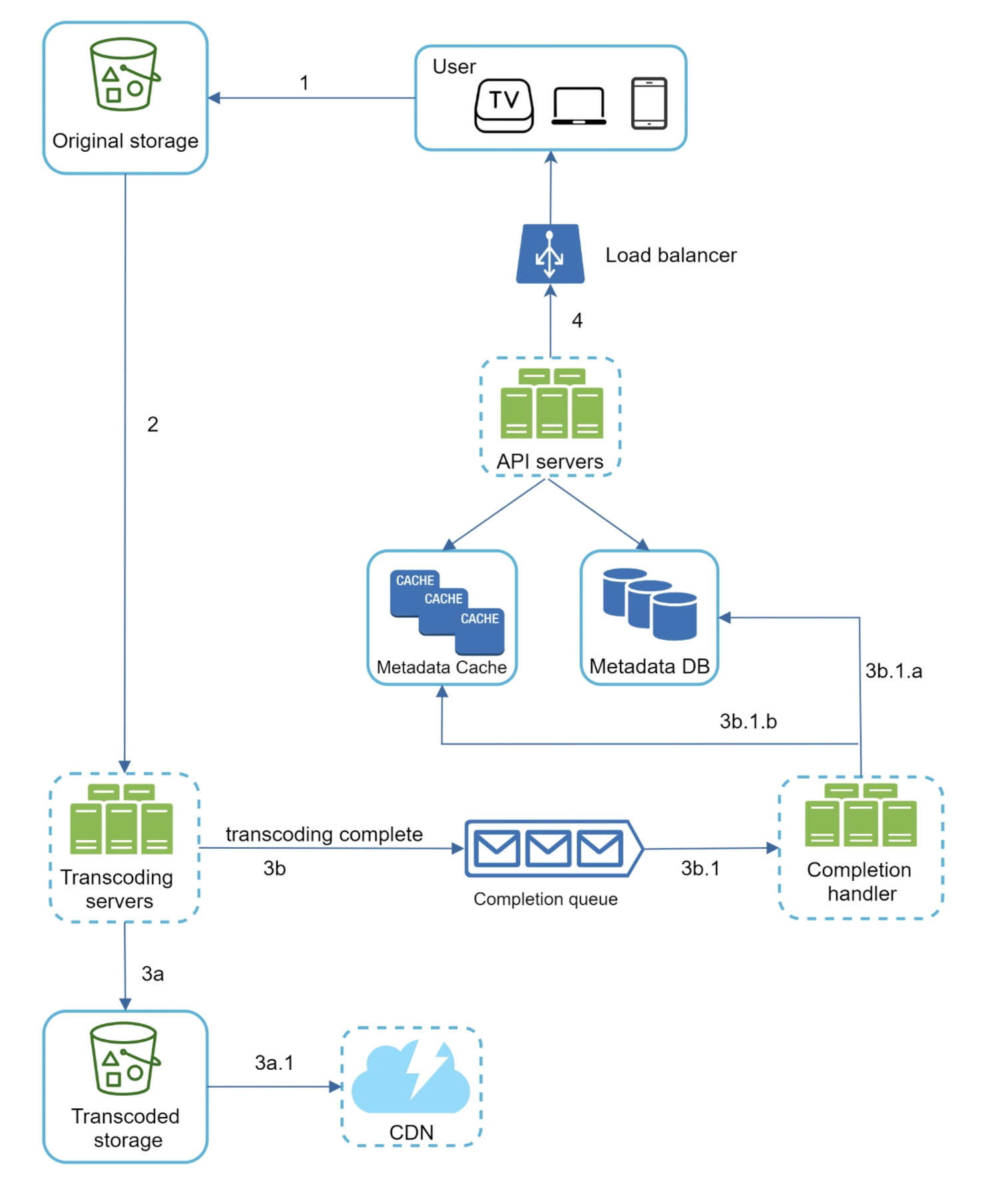
Walking the upload path end to end:
- Client to storage. Rather than streaming gigabytes through the API tier, the client typically requests a pre-signed URL and uploads the file directly to blob storage (the original storage). The API servers never touch the heavy bytes; they only mint short-lived, scoped permission to write one object.
- Record metadata. The API servers write a row to the metadata database — title, owner, upload state, and a pointer to the original object. A metadata cache in front absorbs the read-heavy lookups that follow once the video is live.
- Kick off transcoding. Once the upload completes, the system enqueues a transcoding job. Transcoding servers read the original from storage and produce the renditions (covered in the next sections).
- Signal completion. When a job finishes, the worker posts to a completion queue. A completion handler consumes that event, updates the metadata DB (state →
ready, plus rendition manifest), and invalidates or warms the cache. Decoupling completion through a queue keeps the slow, variable transcoding step from blocking the API tier. - Serve from the CDN. The finished renditions land in transcoded storage, which is the origin behind the CDN. Viewers then pull bytes from the nearest edge, never from origin directly.
function upload_video(client, file_meta):
url = api.create_presigned_put(file_meta) # scoped, expiring
client.put(url, raw_bytes) # straight to blob storage
video_id = metadata_db.insert(state="uploaded", original=url.object)
transcode_queue.enqueue(video_id) # start processing
return video_id
function on_transcode_complete(event): # completion handler
metadata_db.update(event.video_id,
state="ready",
renditions=event.manifest)
metadata_cache.invalidate(event.video_id)
# transcoded output is now live behind the CDN3. Why Transcoding Is Necessary
You cannot simply store the uploaded file and stream it back. Source videos arrive in a huge variety of containers (MP4, MOV, MKV, WebM), codecs (H.264, H.265, VP9, AV1), resolutions, and bitrates — whatever the creator's camera or editor happened to produce. The viewer's side is just as varied: an old phone on a 3G connection and a 4K television on fiber cannot consume the same stream.
Transcoding bridges that gap by producing, from one source, a family of renditions:
- Multiple resolutions — e.g. 240p, 480p, 720p, 1080p, 4K — so each device gets a size it can decode and display.
- Multiple bitrates per resolution, so a player can drop to a lower-bandwidth version when the network degrades and climb back when it recovers.
- Multiple codecs, because device support varies and newer codecs (AV1, H.265) cut bandwidth at the cost of more encoding work.
The renditions are not delivered as monolithic files. Each is cut into short segments (a few seconds each) and described by a manifest. This is the basis of adaptive bitrate streaming (ABR), standardized as DASH and HLS: the player reads the manifest, then chooses, segment by segment, the highest-quality rendition the current bandwidth can sustain. Without transcoding there is nothing for the player to adapt between.
| Dimension | Why it varies | Tradeoff |
|---|---|---|
| Resolution | Screen size and decode capability differ across devices. | Higher resolution = better picture, more bytes and more encode cost. |
| Bitrate | Available bandwidth fluctuates mid-playback. | Lower bitrate = smoother on bad networks, softer image. |
| Codec | Device support and compression efficiency differ. | Modern codecs save bandwidth but cost far more CPU to encode. |
4. Transcoding as a DAG
Transcoding a single video is not one monolithic step; it is many tasks with dependencies. Some can run in parallel, some must wait for others. The natural way to express that is a directed acyclic graph (DAG): nodes are tasks, edges are dependencies, and the graph guarantees there are no cycles so the work always terminates.
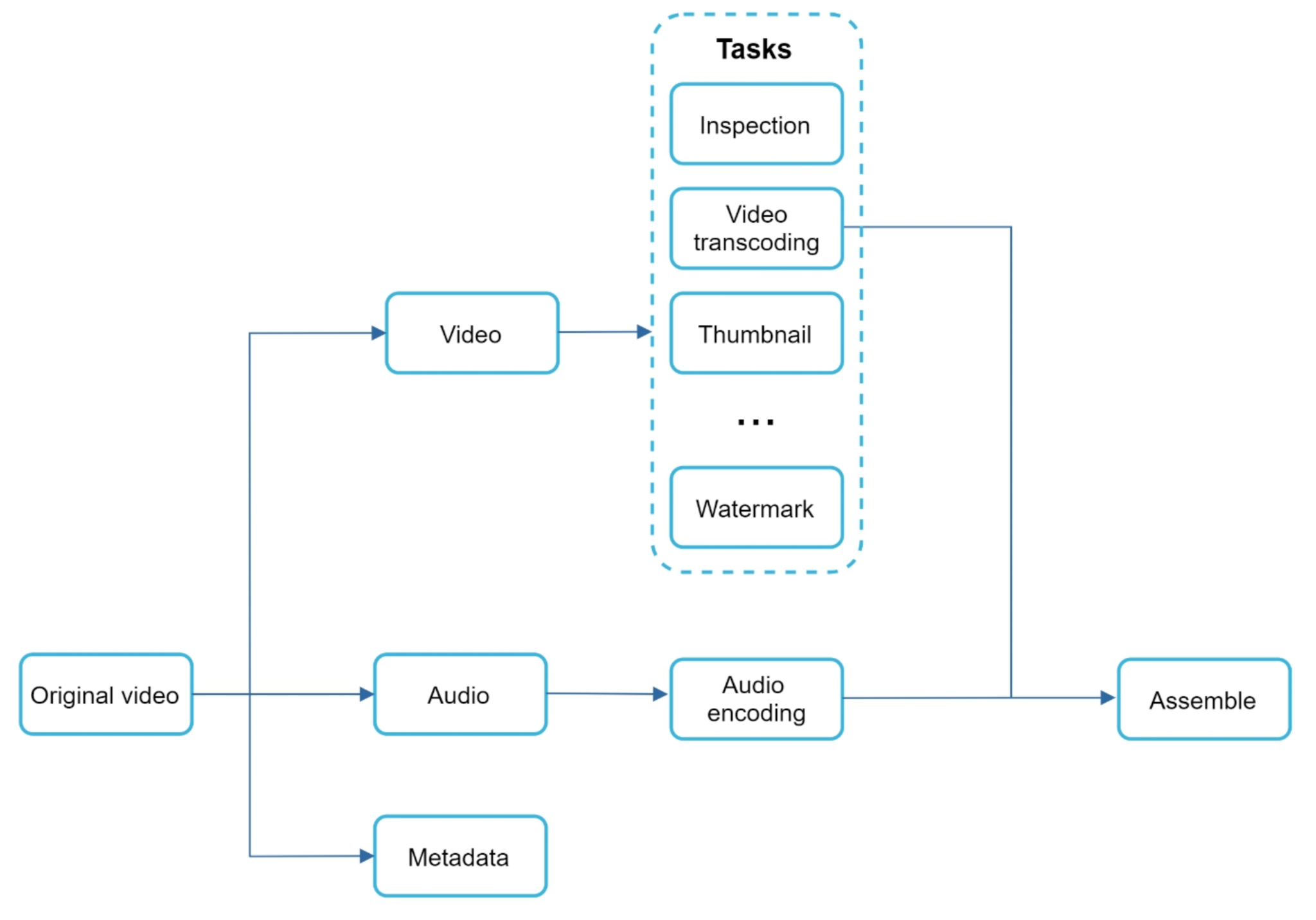
A typical transcoding DAG works in three phases:
- Split. Demux the original into independent streams: the video track, the audio track, and the container metadata. Separating them lets the two media branches proceed at their own pace.
- Fan out. On the video branch, run independent tasks in parallel — inspection (validate the stream, detect resolution and frame rate), video transcoding (produce each resolution/bitrate rendition), thumbnail generation, and watermark application. On the audio branch, run audio encoding. None of these depend on each other, so they can be scheduled across many workers at once.
- Assemble. Once the branches finish, an assemble step muxes the encoded video and audio back together, packages the segments, and writes the manifest. This is the join point where the DAG converges.
Modeling transcoding as a DAG buys two things. First, parallelism falls out for free — independent tasks have no ordering constraint, so the scheduler can run as many as there are workers. Second, retryability is fine-grained: if the watermark task fails, only that node reruns, not the whole video.
# conceptual DAG definition for one video
split = task("split", inputs=[original])
inspect = task("inspect", inputs=[split.video])
transcode = task("transcode", inputs=[split.video]) # one per rendition
thumbnail = task("thumbnail", inputs=[split.video])
watermark = task("watermark", inputs=[transcode])
audio = task("audio", inputs=[split.audio])
assemble = task("assemble", inputs=[watermark, audio, split.metadata])
# inspect, thumbnail, audio have no dependency on each other -> run in parallel5. Orchestrating the DAG
A DAG is just a description; something has to turn it into running work, in the right order, on a finite pool of machines. That orchestration splits into two collaborating pieces: a scheduler that knows the shape of the graph, and a resource manager that knows the state of the worker pool.
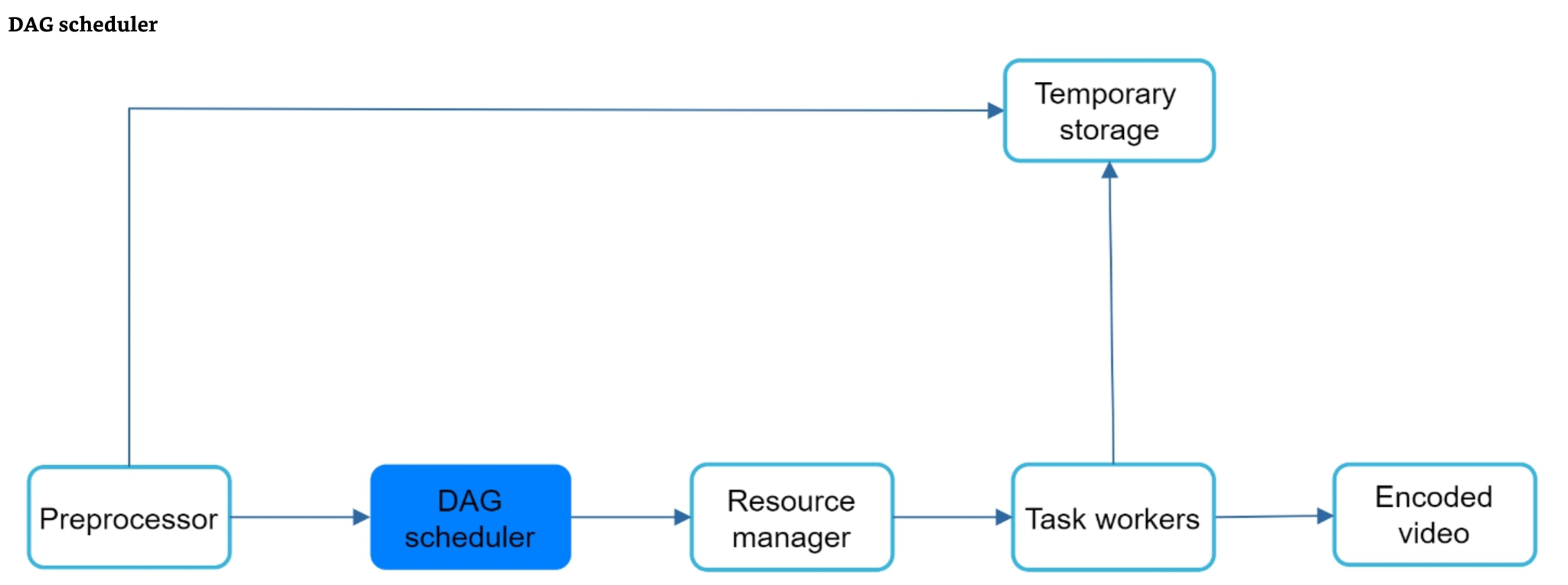
The flow through the orchestration layer is:
- Preprocessor. Takes the incoming video and configuration and builds the concrete DAG — which renditions, which tasks, what dependencies. It also splits the source if needed and stages inputs.
- DAG scheduler. Walks the graph in dependency order, releasing a task for execution only once all of its upstream tasks have completed. It is the component that understands "what can run now."
- Resource manager. Takes runnable tasks from the scheduler and matches them to available workers. It is the component that understands "where can this run."
- Task workers. A pool of (often specialized) workers that actually execute tasks — encoding, thumbnailing, watermarking, merging.
- Temporary storage. Tasks rarely hand artifacts directly to one another. Instead each writes its output to temporary storage and the next task reads from it. This keeps workers stateless and decoupled, and lets a rerun pick up the previous stage's output without recomputing it.
The resource manager deserves its own look, because matching tasks to workers efficiently is where throughput is won or lost.
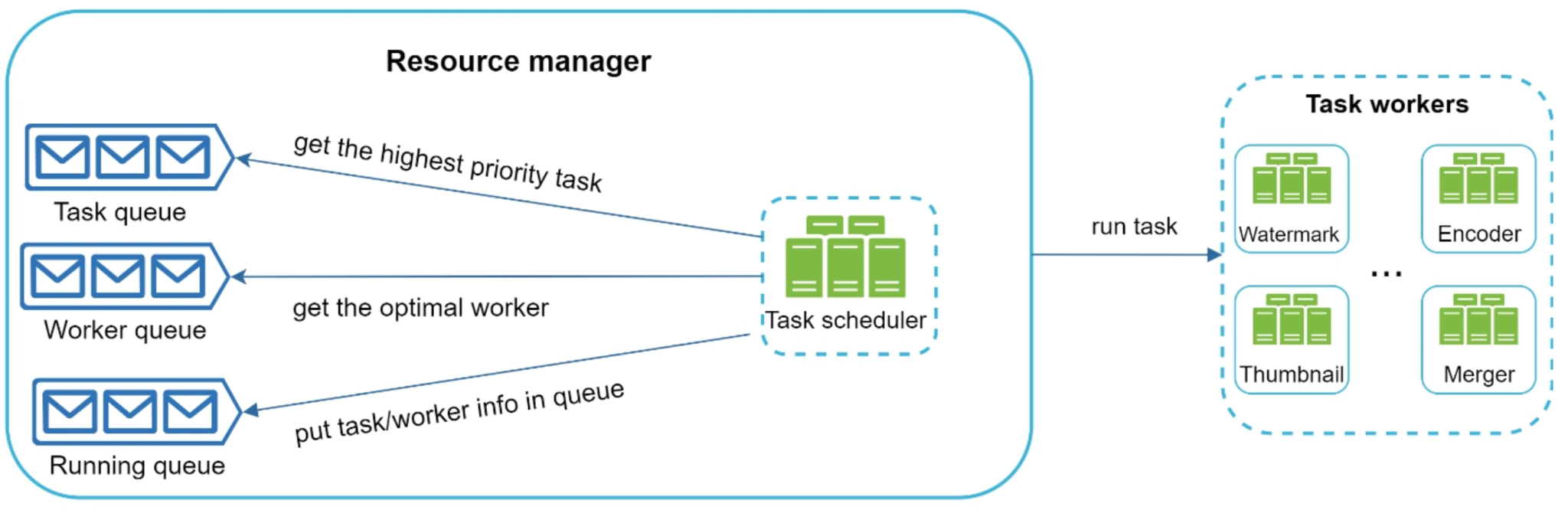
Internally the resource manager coordinates three queues:
| Queue | Holds | Purpose |
|---|---|---|
| Task queue | Tasks the scheduler has marked runnable (dependencies satisfied). | The backlog of work waiting for a worker. |
| Worker queue | Workers currently idle and available. | Capacity waiting for work. |
| Running queue | Task–worker pairs currently executing. | Lets the system track progress, detect stalls, and reclaim workers on failure. |
A task scheduler inside the resource manager repeatedly pulls a runnable task and a free worker, assigns them, and moves the pair into the running queue. When a worker finishes, it returns to the worker queue and its task is reported complete so the DAG scheduler can release downstream tasks. Specializing workers by task type — a dedicated encoder pool, a thumbnail pool, a merger pool — lets each be sized and tuned independently, since encoding is far more expensive than thumbnailing.
function resource_manager_loop():
while True:
if task_queue.empty() or worker_queue.empty():
wait() # nothing to pair yet
continue
task = task_queue.pop() # dependencies already met
worker = worker_queue.pop(matching=task.type)
running_queue.add(worker.run(task)) # dispatch
function on_worker_done(worker, task, output):
temp_storage.put(task.id, output) # stage for next stage
running_queue.remove(worker, task)
worker_queue.push(worker) # worker is free again
dag_scheduler.mark_complete(task) # may release dependents6. The Decoupled Pipeline
Even within a single worker's job, the work has natural stages: fetch the input, do the heavy compute, write the result back. Coupling those stages in one process means a slow upload to storage stalls a CPU that should be encoding, and any failure throws away the whole job. The fix is to split the work into modules separated by message queues.
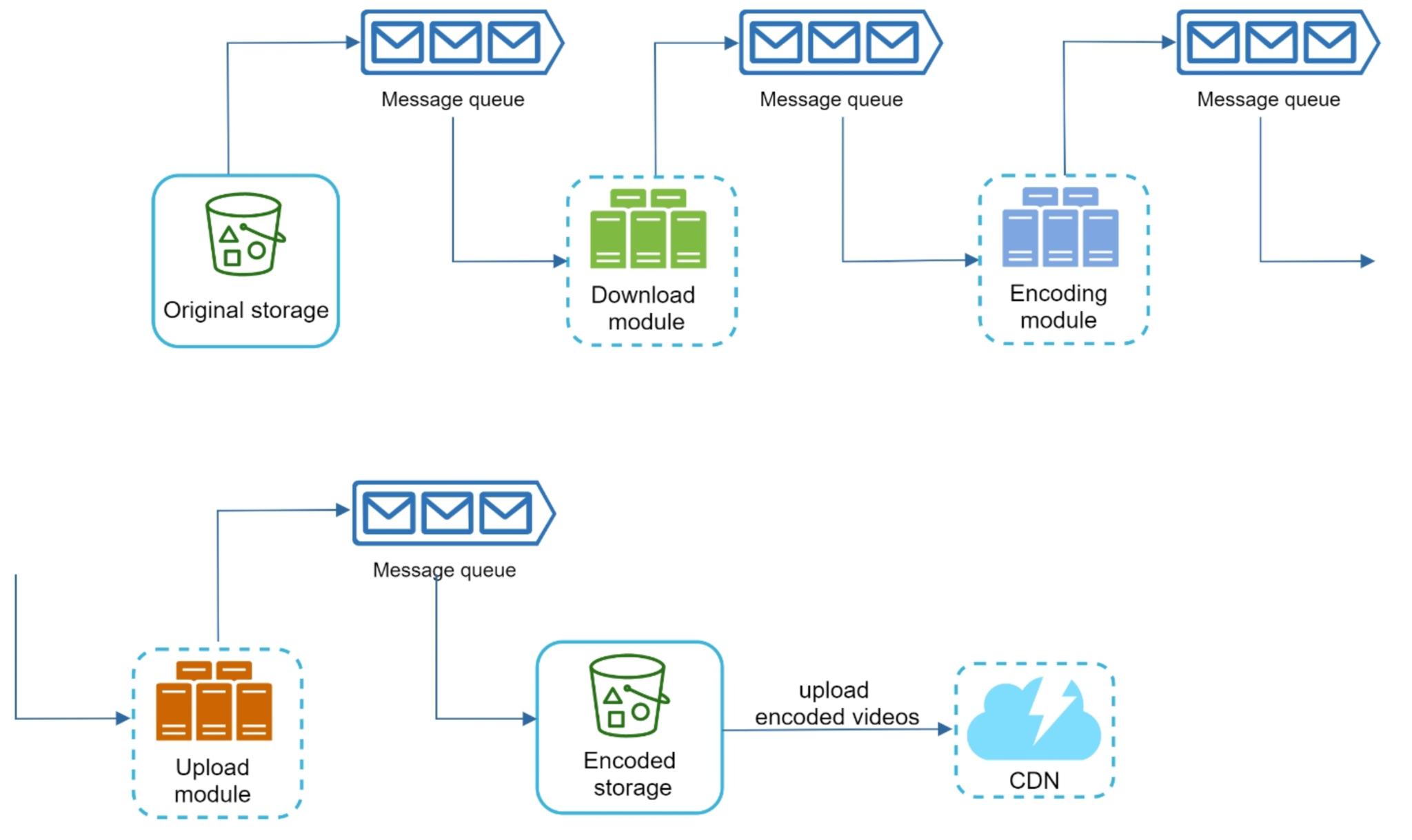
The pipeline reads left to right, with a queue as the seam between every module:
- Download module. Pulls the source segment from original storage and places it where the encoder can reach it. I/O-bound work.
- Encoding module. The CPU-heavy stage that actually transcodes the segment. Compute-bound work.
- Upload module. Writes the encoded output to encoded storage. I/O-bound again.
- Message queues between every stage. Each module consumes from its inbound queue and produces to its outbound queue.
This decoupling pays off in three ways:
- Independent scaling. Encoding is the bottleneck, so you run many encoders and only a handful of download/upload workers. Because the stages communicate through queues, you scale each pool to its own load without touching the others.
- Failure isolation and retry. If an encoder crashes mid-task, its message stays on the queue (unacknowledged) and another worker picks it up. A failure in one stage does not corrupt or block the others.
- Smoothing bursts. Uploads arrive in spikes; queues absorb the spike and let the worker pools drain it at a steady rate, so a flood of uploads becomes a deeper queue rather than a pile of dropped jobs.
7. Streaming to Viewers
Once renditions exist behind the CDN, the read path is comparatively simple — but it is where the bulk of the traffic lives, so getting it right matters most for cost and experience.
- Serve from the edge. The CDN caches segments at edge locations close to viewers. A play request is satisfied from the nearest edge; origin (transcoded storage) is only hit on a cache miss. This is what keeps a global, read-dominated workload affordable and fast.
- Adaptive bitrate. The player fetches the manifest, then requests segments from whichever rendition the measured bandwidth can sustain, switching up or down between segments. Startup is fast (begin on a low rendition) and quality climbs as the buffer fills.
- Range requests. Players use HTTP
Rangerequests to fetch exactly the byte ranges (segments) they need, enabling seeking and progressive download without pulling the whole file. The CDN serves ranges directly from cached objects.
# player-side adaptive bitrate loop
manifest = cdn.get(video_id + "/manifest") # lists renditions + segments
bandwidth = estimate_initial()
for segment in manifest.segments:
rendition = highest_rendition_under(bandwidth)
bytes = cdn.get_range(rendition.url, segment.range) # nearest edge
play(bytes)
bandwidth = measure(bytes) # adapt for next segment8. Optimizations and Safety
With the core flows in place, a strong answer rounds out the design with the optimizations and safeguards a real platform needs.
| Area | Technique |
|---|---|
| Parallelism | Split long videos into chunks and transcode the chunks concurrently across the worker pool, then stitch them back together. Turns a long serial encode into many short parallel ones. |
| Presigned upload URLs | Let clients upload directly to blob storage with short-lived, scoped credentials. Keeps multi-gigabyte transfers off the API tier and supports resumable, multipart uploads. |
| CDN cost and placement | Cache only popular content at the edge; let the long tail fall back to origin or regional caches. Place renditions where the audience is to cut both latency and egress cost. |
| Deduplication | Hash uploads to detect re-uploads of identical content and skip redundant storage and transcoding. Saves significant compute on viral re-shares. |
| Content safety and inspection | The inspection task can also screen for malformed, malicious, or policy-violating content before a video is published, gating the completion handler on the result. |
Two of these deserve emphasis in an interview. Chunked parallel encoding is the single biggest lever on processing latency, and it composes cleanly with the DAG and queue-based pipeline already described — each chunk is just more independent tasks. Content safety is easy to forget but expected at scale: the same inspection stage that validates format is the natural place to enforce policy before anything reaches the CDN.
9. Summary
A video platform is two flows joined by storage and a CDN, each built from a few repeating ideas:
| Concern | Mechanism |
|---|---|
| How does a huge upload reach storage? | Pre-signed URL straight to blob (original) storage; the API tier never handles the bytes. |
| How is upload progress tracked? | Metadata DB (with a cache) records state; a completion queue and handler flip state to ready when processing finishes. |
| Why transcode at all? | Sources vary in format; viewers vary in device and bandwidth. Multiple resolutions/bitrates/codecs enable adaptive bitrate (DASH/HLS). |
| How is the processing structured? | A DAG: split into video/audio/metadata, fan out parallel tasks (inspect, transcode, thumbnail, watermark), then assemble. |
| What runs the DAG? | A preprocessor builds it, a DAG scheduler orders it, a resource manager with task/worker/running queues assigns it to specialized workers; temp storage passes artifacts between stages. |
| How does processing scale and survive failure? | Modules (download → encode → upload) separated by message queues: each scales independently, failures are isolated, work is retryable. |
| How are videos delivered? | CDN edge caching close to viewers, adaptive bitrate, and HTTP range requests for seeking. |
| What rounds out a real design? | Chunked parallel encoding, presigned uploads, CDN cost/placement, dedup, and content safety via the inspection stage. |