Designing a URL Shortener
A system design walkthrough for building a service like TinyURL or bit.ly: how a long URL becomes a short slug, how that slug is stored and looked up, and why almost every decision is shaped by the fact that reads vastly outnumber writes.
A URL shortener takes a long, unwieldy link and hands back a short one — https://example.com/abc123 — that redirects to the original. The product is deceptively simple, which is exactly why it is a popular interview question: the requirements are small enough to fully specify in a few minutes, yet the design forces you to reason about ID generation, storage schemas, caching, and the semantics of HTTP redirects. This guide walks the problem from requirements to a working design, keeping the discussion generic and educational rather than tied to any one company's implementation.
Contents
1. Requirements and Estimates
Before sketching anything, pin down what the service must do. The functional requirements are short: given a long URL, return a short URL; given a short URL, redirect the caller to the original long URL. Optional extras — custom aliases, link expiry, analytics, user accounts — are worth naming so you can decide what is in scope, but the core is just those two operations.
The non-functional requirements are where the design gets its shape. The system should be highly available (a dead redirect breaks every link that was ever shared), redirects should be low-latency, and short URLs must not be guessable in a way that leaks others' links. The single most important observation, though, is the traffic shape.
| Property | Assumption | Why it matters |
|---|---|---|
| Read:write ratio | Roughly 100:1 — links are created once and clicked many times. | The system is overwhelmingly a read service. Optimize the redirect path and cache aggressively. |
| New URLs per month | Say ~100M creates/month. | Drives the key space: how long a slug must be to never run out. |
| Redirects per month | ~10B at 100:1. | Drives read throughput and the need for a cache tier in front of the store. |
| Retention | Links live for years. | Storage grows steadily; the slug length must cover many years of creates. |
A quick back-of-the-envelope pass: 100M writes per month is roughly 40 writes per second on average. At a 100:1 ratio that is about 4,000 reads per second, with peaks well above that. Storage is modest per row — a few hundred bytes for the long URL plus metadata — so 100M rows a month is on the order of tens of gigabytes a year, easily handled by a single relational or key-value store with replication. The dominant cost is not storage; it is serving the read flood quickly and reliably.
2. Write Path and Read Path
The service has exactly two flows, and it pays to draw them separately because they are asymmetric. The write path runs rarely and can afford to do real work; the read path runs constantly and must be as short as possible.
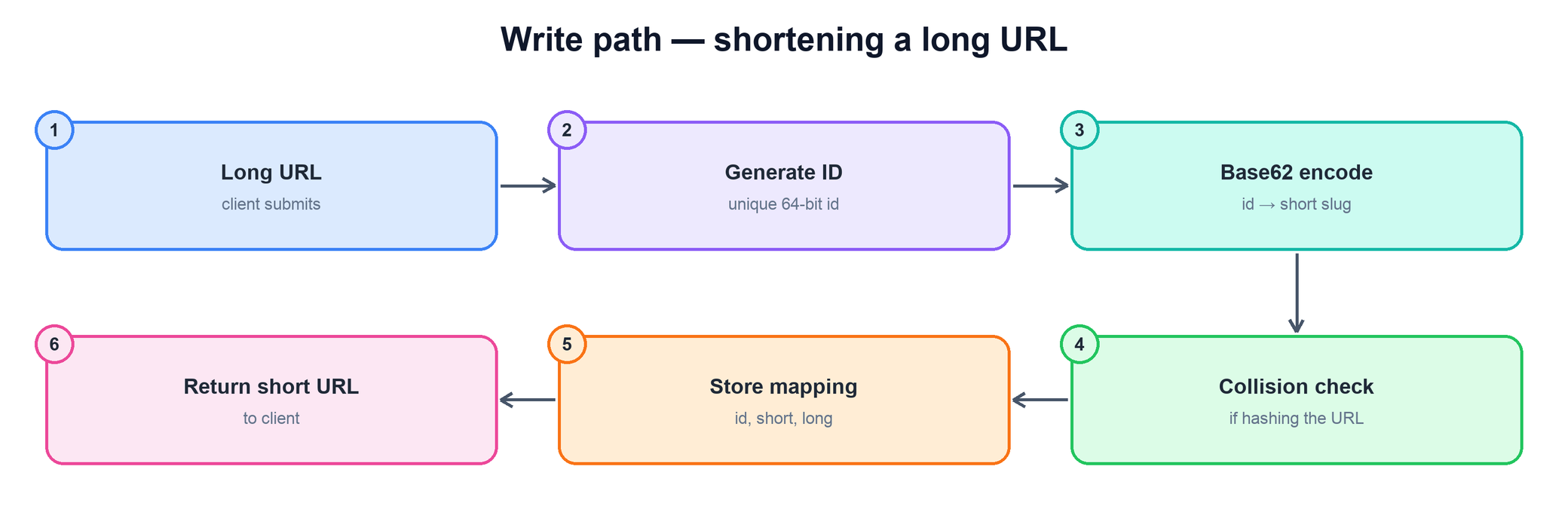
On a create request, the service generates an identifier for the new link, encodes that identifier into a short slug using base62, confirms the slug is not already taken (a check that is trivial or unnecessary depending on the ID strategy below), stores the mapping, and returns the assembled short URL to the caller. This is the expensive path, but it runs only on the order of tens of times per second.
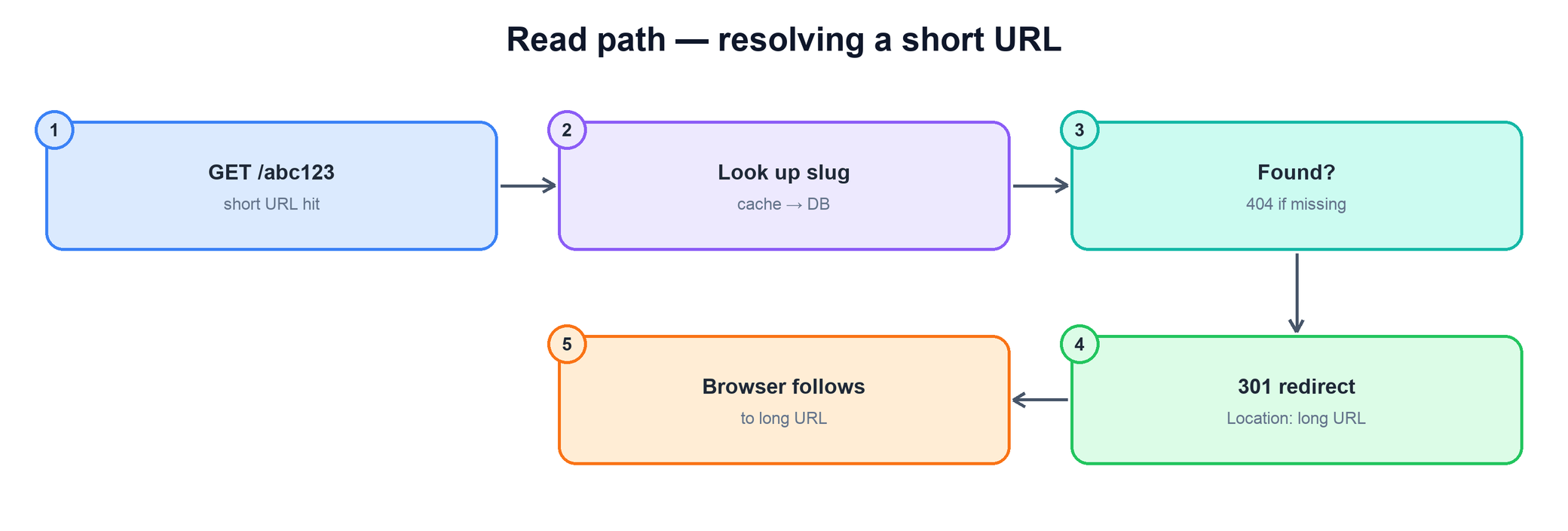
On a redirect request — a GET /abc123 — the service extracts the slug, looks up the corresponding long URL, and responds with an HTTP redirect pointing at it. The browser then follows that redirect to the destination. If the slug does not exist, the service returns 404 Not Found. The lookup checks an in-memory cache first and only touches the database on a miss. Keeping this path to a single fast lookup is the entire performance game.
3. Two Ways to Generate the ID
The heart of the design is deciding what the slug should be derived from. There are two well-known approaches, and they trade collision-handling complexity against statelessness.
| Approach | How it works | Collisions | Tradeoff |
|---|---|---|---|
| Hash the long URL | Run the long URL through a hash like MD5 or SHA-256, then take a base62-encoded prefix of the digest (say the first 7 characters) as the slug. | Possible. Two different URLs can share a prefix, and the same URL submitted twice naturally hashes the same. | Stateless and simple to compute, but you must detect and resolve collisions on every write — rehash with a salt, or lengthen the prefix until the slug is free. |
| Unique ID + base62 | Generate a globally unique 64-bit integer id (from a counter, a sequence, or a distributed ID generator), then base62-encode that integer to produce the slug. | None by construction. Each id is unique, so each encoded slug is unique. | Cleaner — no collision check needed — but you need a source of unique ids, which adds a small piece of coordinated state. |
The hashing approach is appealing because it needs no shared counter: any node can compute a slug from the URL alone. The catch is that a fixed-length prefix of a hash will eventually collide as the table fills, so the write path has to check whether the candidate slug is already mapped to a different URL and, if so, perturb the input and try again. That collision loop is extra latency and extra code on every create.
function shorten_by_hash(long_url):
salt = ""
while True:
digest = sha256(long_url + salt)
slug = base62(digest)[0:7] # take a 7-char prefix
existing = store.get(slug)
if existing is None:
store.put(slug, long_url) # free: claim it
return slug
if existing == long_url:
return slug # same URL, reuse slug
salt = salt + "x" # collision: rehash and retryThe unique-ID approach sidesteps all of that. If every link gets a brand-new 64-bit id, encoding that id to base62 yields a slug that is guaranteed distinct from every other slug, because the encoding is a one-to-one mapping from integers to strings. There is no collision check at all — the create path just allocates an id, encodes it, and stores the row.
function shorten_by_id(long_url):
id = id_generator.next() # unique 64-bit integer
slug = base62_encode(id) # no collision possible
store.put(id, slug, long_url) # one write, no retry
return slug4. Base62 and the Length Math
Base62 uses the 62 characters that are safe and compact in a URL: the digits 0-9, the lowercase letters a-z, and the uppercase letters A-Z. Encoding an integer in base62 is the same idea as writing it in base10 or base16, just with 62 symbols instead of 10 or 16, so the resulting string is short and contains only URL-friendly characters.
ALPHABET = "0123456789abcdefghijklmnopqrstuvwxyz" +
"ABCDEFGHIJKLMNOPQRSTUVWXYZ" # 62 symbols
function base62_encode(n):
if n == 0: return "0"
chars = []
while n > 0:
chars.push(ALPHABET[n % 62])
n = n / 62 # integer division
return reverse(chars) # e.g. 125 -> "21"The length math decides how long your slugs need to be. A slug of n base62 characters can represent 62n distinct values, which grows far faster than the 10n you get from base10. A few rows make the difference obvious.
Length n | Base10 capacity (10n) | Base62 capacity (62n) |
|---|---|---|
| 4 | 10,000 | ~14.8 million |
| 5 | 100,000 | ~916 million |
| 6 | 1 million | ~56.8 billion |
| 7 | 10 million | ~3.5 trillion |
So a 6-character base62 slug covers roughly 56.8 billion links and a 7-character slug roughly 3.5 trillion. Against an estimate of 100M new links per month, a 7-character slug gives thousands of years of headroom, while a 6-character slug still covers decades. Picking the length is simply choosing the smallest n whose 62n comfortably exceeds the total number of URLs you ever expect to mint, with margin to spare. Most real services settle on 6 or 7 characters for exactly this reason.
5. Data Model
The storage need is a single mapping from slug to long URL, which is about as simple as a schema gets. A relational table or a key-value store both work; the access pattern (look up by slug) is a primary-key read either way.
| Column | Type | Purpose |
|---|---|---|
id | 64-bit integer (primary key) | The unique identifier the slug is encoded from. Also the natural primary key. |
shortURL | varchar (indexed/unique) | The base62 slug, e.g. abc123. Looked up on every redirect, so it must be indexed. |
longURL | text | The original destination the slug redirects to. |
created_at | timestamp (optional) | When the link was created — useful for expiry and analytics. |
user_id | identifier (optional) | Owner of the link, if the service has accounts. |
The write step is therefore a single insert: create a new row carrying the id, the shortURL slug, and the longURL destination (plus any optional metadata). Because the redirect path looks up by slug, the shortURL column carries a unique index so the lookup is an indexed point read rather than a scan.
# create: one row insert
INSERT INTO urls (id, shortURL, longURL, created_at)
VALUES (1006207, 'abc123', 'https://example.com/some/very/long/path', now());
# redirect: indexed point lookup
SELECT longURL FROM urls WHERE shortURL = 'abc123';6. Redirect Semantics: 301 vs 302
When the service resolves a slug it answers with an HTTP redirect, and the status code it chooses has real operational consequences. The two candidates are 301 Moved Permanently and 302 Found (a temporary redirect), and they differ in whether the browser is allowed to remember the answer.
| Status | Meaning | Caching behavior | Best when |
|---|---|---|---|
| 301 Moved Permanently | The slug permanently maps to this long URL. | Browsers cache the redirect. After the first hit, the browser jumps straight to the long URL without calling your server again. | You want to minimize load on your service and the mapping never changes. |
| 302 Found | The slug temporarily points here; ask again next time. | Browsers do not cache it. Every click comes back through your server. | You want to count clicks, run analytics, A/B test destinations, or change where a slug points. |
The tradeoff is direct: a 301 is cheaper because the browser stops asking you after the first request, but that is also its drawback — once the browser has cached the redirect you lose visibility into subsequent clicks, so you cannot track them or change the destination for users who already followed the link. A 302 keeps every click flowing through your server, which is exactly what you want for analytics and dynamic destinations, at the cost of carrying the full redirect load yourself. Choose 301 when the priority is reducing server traffic on immutable links, and 302 when click tracking or the ability to repoint a slug matters more than saving requests.
7. Caching the Hot Slugs
Because reads outnumber writes by roughly 100:1, and because link popularity is heavily skewed — a small fraction of slugs receive the bulk of the clicks — an in-memory cache in front of the database is the highest-leverage component in the system. The redirect path checks the cache first; on a hit it never touches the database at all.
A least-recently-used eviction policy fits naturally: the freshly viral links stay resident while cold links age out. On a cache miss the service falls back to the database, reads the mapping, populates the cache so the next hit is fast, and then issues the redirect. The vast majority of redirects are served entirely from memory.
function resolve(slug):
long_url = cache.get(slug)
if long_url is not None:
return redirect(long_url) # hot path: memory only
long_url = db.lookup(slug) # cache miss: hit the store
if long_url is None:
return http_404() # unknown slug
cache.put(slug, long_url) # warm the cache for next time
return redirect(long_url)8. Summary
The URL shortener is a small system whose design follows almost entirely from one fact — reads dominate writes — and a couple of clean encoding choices.
| Concern | Decision |
|---|---|
| What shapes the design? | A ~100:1 read:write ratio. The redirect path is the hot path; optimize and cache it. |
| How is the slug generated? | Prefer a unique 64-bit id base62-encoded (no collisions). Alternatively hash the URL and resolve collisions by rehashing or lengthening. |
| Why base62? | URL-safe characters (0-9a-zA-Z) and compact: 62n grows far faster than 10n, so 6-7 characters cover billions to trillions of links. |
| How is the mapping stored? | A row per link with id, shortURL, longURL (plus optional created_at, user_id); the slug column is uniquely indexed. |
| Which redirect code? | 301 to offload traffic (browser caches it); 302 when you need click tracking or a changeable destination. |
| How are reads kept fast? | An LRU in-memory cache of hot slugs in front of the database; a miss falls back to the store and warms the cache. |