Designing a Social Graph
A system design interview guide to storing and querying who follows whom at scale — the relationship layer underneath feeds, friend suggestions, and follower counts — without letting a single celebrity break the whole system.
Underneath every social product is a deceptively simple data structure: a set of relationships between users. Who follows whom, who is friends with whom, who blocked whom. It looks like a table of pairs until you confront the numbers — billions of users, hundreds of billions of edges, a handful of accounts with tens of millions of followers each — and the access patterns, where "list this user's followers" and "is A following B" must each return in milliseconds. The interesting design problem is not modeling a relationship; it is storing those relationships so the common queries are fast, sharding them across many machines without making every query touch every machine, and surviving the wildly uneven reality that a few accounts have millions of edges while most have a handful. This guide builds that storage layer up from the model outward.
Contents
1. The Edge Model
The first decision is what an edge actually represents, because the two common relationship types behave differently and that difference shapes everything downstream. Getting this right early prevents a lot of confusion later.
| Relationship | Direction | Meaning | Example |
|---|---|---|---|
| Follow | Directed | A follows B does not imply B follows A. Each edge is one-way. | Twitter / Instagram following |
| Friendship | Undirected (mutual) | If A is friends with B, then B is friends with A. The edge is symmetric. | Facebook friends |
A follow is a directed edge: it has a source (the follower) and a target (the followee), and the reverse may or may not exist. A friendship is an undirected edge, but it is almost always implemented as two directed edges — one in each direction — precisely so that the storage and query machinery can be identical for both. Once you model friendship as a mutual pair of follow edges, you only ever have to design for the directed case, with the extra rule that friendship edges are created and deleted in pairs. For the rest of this guide we reason in terms of directed follow edges.
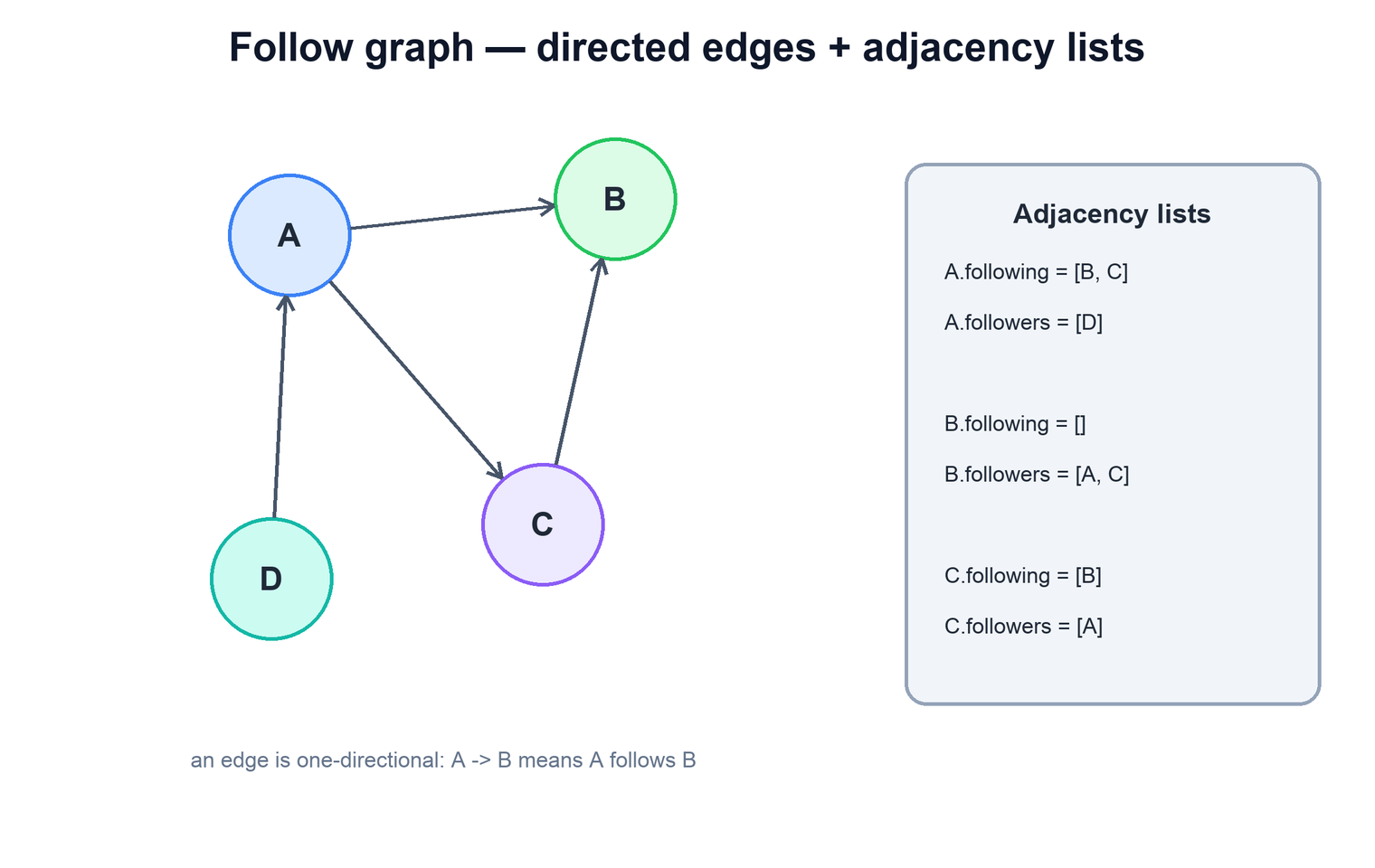
2. Adjacency-List Storage
Having decided that the graph is a set of directed edges, the next question is how to lay those edges out in storage so the common queries are cheap. The dominant approach is the adjacency list: for each user, store the list of users they are connected to. The natural alternative — one giant table of (source, target) rows — is simple but forces an index scan for every lookup; adjacency lists put each user's neighbors right where you can grab them in one read.
Concretely, each user gets (at least) two lists:
- Following list — the set of accounts this user follows. This is the list you read to build the user's home feed, since their feed is assembled from the people they follow.
- Followers list — the set of accounts that follow this user. This is the list you read to show "followers" and, crucially, to know who to deliver this user's new posts to.
# adjacency lists keyed by user id
following[A] = [B, C, D] # accounts A follows
followers[A] = [E, F] # accounts that follow A
# reading "who does A follow" is a single keyed lookup
function get_following(user_id):
return following[user_id]The win is that the two most frequent reads — "who does this user follow" and "who follows this user" — each become a single keyed lookup rather than a scan over an edge table. The cost, which the next section addresses head-on, is that you are now storing each relationship twice and must keep the two copies in agreement.
3. Denormalizing Both Directions
A directed edge "A follows B" is logically a single fact, but the two queries it serves pull from opposite ends. "Who does A follow?" needs the fact indexed by A; "who follows B?" needs the same fact indexed by B. If you store the edge only once, one of those two queries always degrades into a scan. The standard answer is to denormalize: store the edge from both ends.
So creating a single follow writes two records:
- Append B to
following[A]— the forward direction, for A's feed and A's "following" list. - Append A to
followers[B]— the reverse direction, for B's "followers" list and B's post fan-out.
function follow(a, b):
following[a].add(b) # forward edge: A -> B
followers[b].add(a) # reverse edge: maintained for fast reads
function unfollow(a, b):
following[a].remove(b)
followers[b].remove(a) # both copies must change togetherThis trades write cost and storage for read speed, which is the right trade for a social graph because reads vastly outnumber writes — people view follower lists and load feeds far more often than they follow or unfollow. The price is that every relationship now exists as two physical records that can drift out of sync if a write half-fails, which is exactly the consistency problem addressed later.
4. Query Patterns
The storage layout only makes sense in light of the queries it has to serve, so it is worth enumerating them and seeing how each maps onto the adjacency lists. Three patterns dominate, in rough order of difficulty.
- Is A following B? A membership test: check whether B appears in
following[A](or, equivalently, whether A appears infollowers[B]). With the right structure this is a near-constant-time point lookup, and it is the query behind rendering a "Follow / Following" button. - List the followers (or following) of a user. A direct read of one adjacency list, returned in pages. Cheap for ordinary users; the pathological case is the celebrity with millions of followers, handled in its own section.
- Friends-of-friends. A two-hop traversal: take the user's neighbors, then the neighbors of each of those, then remove the user and anyone already a direct connection. This powers "people you may know." It is the most expensive pattern because the work fans out multiplicatively with each hop.
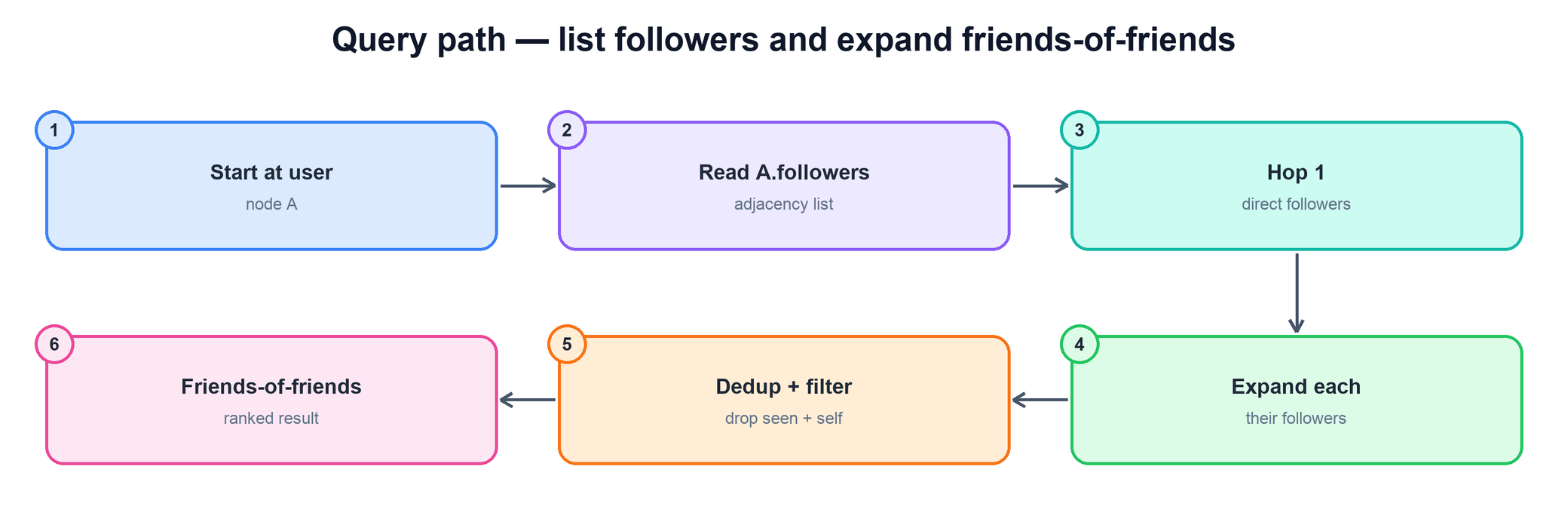
# friends-of-friends: a bounded two-hop BFS
function friends_of_friends(a):
direct = set(following[a])
candidates = {}
for f in direct:
for ff in following[f]: # hop 2
if ff != a and ff not in direct: # drop self + already-known
candidates[ff] += 1 # count mutual connections
return rank_by_mutuals(candidates)5. Sharding by User Id
No single machine can hold hundreds of billions of edges, so the graph has to be partitioned across many shards. The natural partition key is the user id: a user's adjacency lists live on the shard that owns that user. This keeps any single user's data co-located, so "list A's followers" hits exactly one shard.
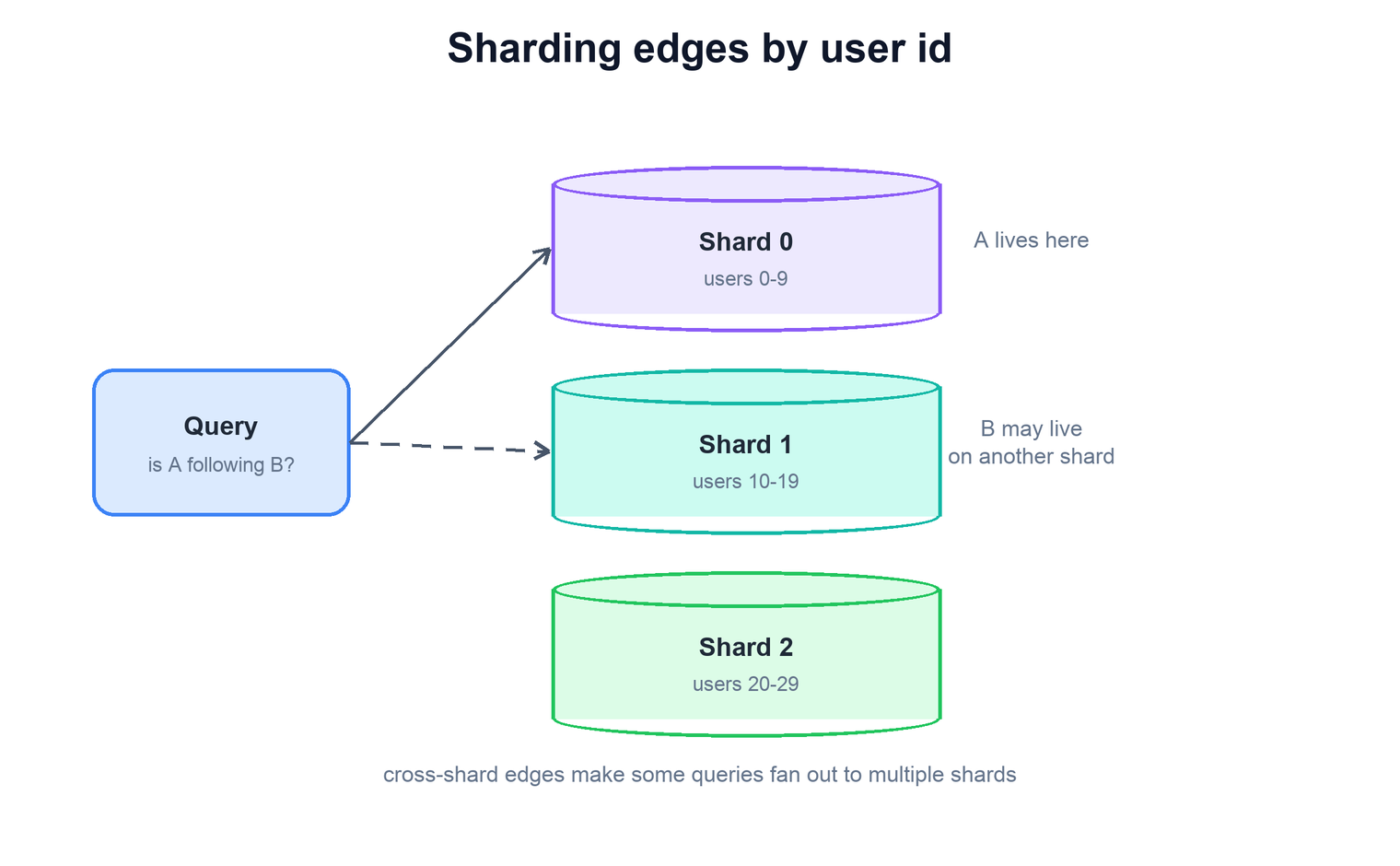
Sharding by user solves the storage problem but introduces the cross-shard query problem. Because an edge connects two users who may be owned by different shards, queries about a single user are clean but queries that span an edge are not:
- "List A's followers" stays on one shard — A's
followerslist lives entirely on A's shard (thanks to denormalization). - "Is A following B?" can be answered on A's shard alone, since A's
followinglist is there — this is a good reason to prefer reading the forward edge. - Friends-of-friends is genuinely cross-shard: the second hop's users are scattered across many shards, so the traversal fans out to many machines and must gather the results. This is why two-hop queries are usually precomputed or served from a separate system rather than run live.
The general lesson is that denormalizing both directions is what keeps the high-frequency queries single-shard; the multi-hop queries that inherently cross edges are the ones you design around — by precomputing, caching, or accepting a scatter-gather.
6. The Celebrity Problem
The distribution of follower counts is extremely skewed: most users have tens or hundreds of followers, but a few have tens of millions. That single fact — the hot key — breaks several assumptions the design has quietly been making.
- One adjacency list no longer fits or reads cheaply. A followers list with thirty million entries cannot be loaded in one go; it has to be itself paginated and often split across storage. The shard owning a celebrity also becomes a load hot spot.
- It interacts with feed fan-out. The naive way to deliver a post is "fan-out on write": push the post into the feed of every follower. For an ordinary user that is fine. For a celebrity, a single post means writing to millions of feeds at once — a write storm that is wasteful and slow, especially since many of those followers may never log in to see it.
The standard resolution is a hybrid fan-out: use fan-out on write for ordinary accounts, and fan-out on read for celebrities. Ordinary users' posts are pushed to their followers' feeds eagerly; a celebrity's posts are not pre-pushed, and instead each follower's feed query pulls the celebrity's recent posts at read time and merges them in. This caps the write amplification of any single post while keeping the common case fast.
function publish(author, post):
if follower_count(author) < FANOUT_THRESHOLD:
for f in followers[author]:
feed[f].push(post) # fan-out on write (ordinary user)
else:
hot_posts[author].add(post) # celebrity: pulled in at read time
function build_feed(user):
base = feed[user].recent() # pre-pushed posts
celebs = [hot_posts[c] for c in following[user] if is_hot(c)]
return merge(base, celebs) # fan-out on read for hot accounts7. Edge Consistency
Because every edge is stored twice — once in following, once in followers, often on two different shards — the two copies can disagree if a write only half-completes. The user experience of an inconsistent edge is jarring: A's app says A follows B, but B's follower count and follower list never updated.
The practical stance is to favor eventual consistency with mechanisms that converge the two copies, rather than paying for a distributed transaction on every follow:
- Make one direction authoritative. Treat, say, the forward
followingedge as the source of truth and the reversefollowersedge as a derived index. If they disagree, the index is what gets repaired. - Repair asynchronously. Drive the reverse write off a durable log or queue so that a transient failure to update the second copy is retried until it succeeds, rather than lost.
- Reconcile in the background. Periodic jobs scan for mismatches — an edge present in one direction but not the other — and fix them, bounding how long any inconsistency can persist.
This is an acceptable trade because a follow that takes a second to reflect on the other side is rarely a correctness problem, whereas a synchronous two-shard transaction on every follow would be a serious cost at this scale. The key is that the inconsistency window is bounded and self-healing, not permanent.
8. KV Store vs Graph DB
A recurring interview question is whether to build the graph on a general-purpose key-value store with adjacency lists or to adopt a dedicated graph database. Both are legitimate; the right answer depends on which queries dominate.
| Approach | Strengths | Weaknesses |
|---|---|---|
| KV / wide-column store with adjacency lists | Massive horizontal scale; predictable O(1) reads for one-hop queries; operationally well understood; you control sharding and denormalization. | Multi-hop traversals are awkward and must be done in application code or precomputed; you maintain edge consistency yourself. |
| Dedicated graph database | Multi-hop traversals (friends-of-friends, paths) are first-class and expressive; the model matches the domain directly. | Harder to scale to the very largest graphs; sharding a graph engine is itself a hard problem; can be a heavier operational dependency. |
For the bread-and-butter social graph — overwhelmingly one-hop reads (followers, following, is-A-following-B) at enormous scale — most large systems land on a partitioned KV or wide-column store with hand-maintained adjacency lists, precisely because the dominant queries are simple lookups and scale matters more than traversal expressiveness. A dedicated graph database earns its place when deep, ad-hoc traversals are central to the product. The honest interview answer is to pick based on the query mix and to acknowledge that the multi-hop queries are the ones that make a graph database tempting and a KV store work harder.
9. Summary
A social graph is a store of directed edges engineered so the common queries are cheap and the skew of the real world does not break it. The design is a chain of reinforcing decisions:
| Concern | Mechanism |
|---|---|
| What is a relationship? | A directed follow edge; a friendship is just a mutual pair of directed edges. |
| How are edges stored for fast reads? | Adjacency lists per user: a "following" list and a "followers" list. |
| How are both directions made fast? | Denormalize — write each edge from both ends so each lookup is a single keyed read. |
| What queries must be cheap? | Is A following B (point lookup), list followers/following (paged read), friends-of-friends (two-hop BFS). |
| How is the graph partitioned? | Shard by user id; single-user queries hit one shard, edge-spanning queries may cross shards. |
| How do we survive celebrities? | Hybrid fan-out — fan-out on write for ordinary users, fan-out on read for hot accounts; paginate huge lists. |
| How do the two copies stay in agreement? | Eventual consistency: one authoritative direction, async repair via a log, background reconciliation. |
| What storage engine? | Partitioned KV / wide-column with adjacency lists for scale; a graph DB when deep traversals are central. |