Designing a Ride Matching Service
A system design interview guide to building an Uber-style dispatch system that matches a rider to the best nearby driver in seconds — over a sea of driver locations that change every few seconds, without ever handing the same driver to two riders.
Ride matching looks like a proximity search with a twist, and the twist is where the design gets hard. Finding drivers near a rider is the same "what is near me?" spatial-index problem a Yelp-style service solves — but here the things you are indexing move, and you do not just read the result, you act on it by assigning a specific driver to a specific rider exactly once. Two new pressures dominate: an enormous, constant stream of driver location updates that must keep the index fresh, and a correctness requirement that two riders are never matched to the same driver. This guide walks through the location pipeline, the matching flow, the concurrency problem at its core, and how the system recovers when a driver declines or goes silent.
Contents
1. What Makes Matching Hard
The headline feature — "show me a driver and send them to me" — hides three distinct hard problems that an interviewer wants you to separate cleanly. Conflating them is the most common way the design goes wrong.
- The data moves constantly. Every active driver reports a new location every few seconds. With many thousands of drivers in a city, that is a relentless write stream into the very index you also need to query for matching. A spatial index that is cheap to read but expensive to update will not survive this.
- Matching is an action, not a read. A proximity query returns a list; ride matching must pick one driver and reserve them. The moment you turn a read into a reservation, concurrency rears its head.
- The best match is not just the nearest. The driver to offer is the one who can get there soonest, which depends on road network and traffic (ETA), not raw straight-line distance — and availability changes second to second.
2. The Location Pipeline
Start with the firehose. Each driver's app sends a location ping on a short interval, and these pings must flow into a geospatial index fast enough that a matching query a moment later sees a fresh picture of where everyone is. The defining trait of this path is that it is write-dominated — far more location updates arrive than ride requests — so it is built and scaled around absorbing writes.
Because a driver's position is only useful while it is current, this data is a natural fit for a fast, in-memory, frequently overwritten store rather than a durable disk-backed database. You do not need the full history of every GPS point; you need the latest position, indexed spatially, available in milliseconds. A geo-indexed in-memory store (or an in-memory quadtree) keyed by location is the usual choice.
# driver app pings every few seconds
function on_location_update(driver_id, lat, lng):
cell = geo_cell(lat, lng) # geohash / quadtree leaf
geo_index.upsert(driver_id, cell, lat, lng, ts=now())
# overwrite, don't append — only the latest fix mattersThe key design decisions on this path:
- Overwrite, do not accumulate. Each update replaces the driver's previous position. You are maintaining a current-state map, not a log, which keeps storage bounded and writes cheap.
- In-memory for speed. Reads and writes both have to be fast, and the data is disposable, so it lives in memory rather than on disk.
- Index by cell. Each driver is tagged with a spatial cell (geohash or quadtree leaf) so the matching service can fetch "drivers near here" with a cell lookup rather than scanning everyone.
3. The Geospatial Index
The index is the bridge between the two halves of the system: the location pipeline writes into it, and the matching service reads from it. Conceptually it is the same spatial index a proximity service uses — drivers are placed into cells, and a query for a rider returns the drivers in the cell the rider is in plus the neighboring cells, trimmed to a radius.
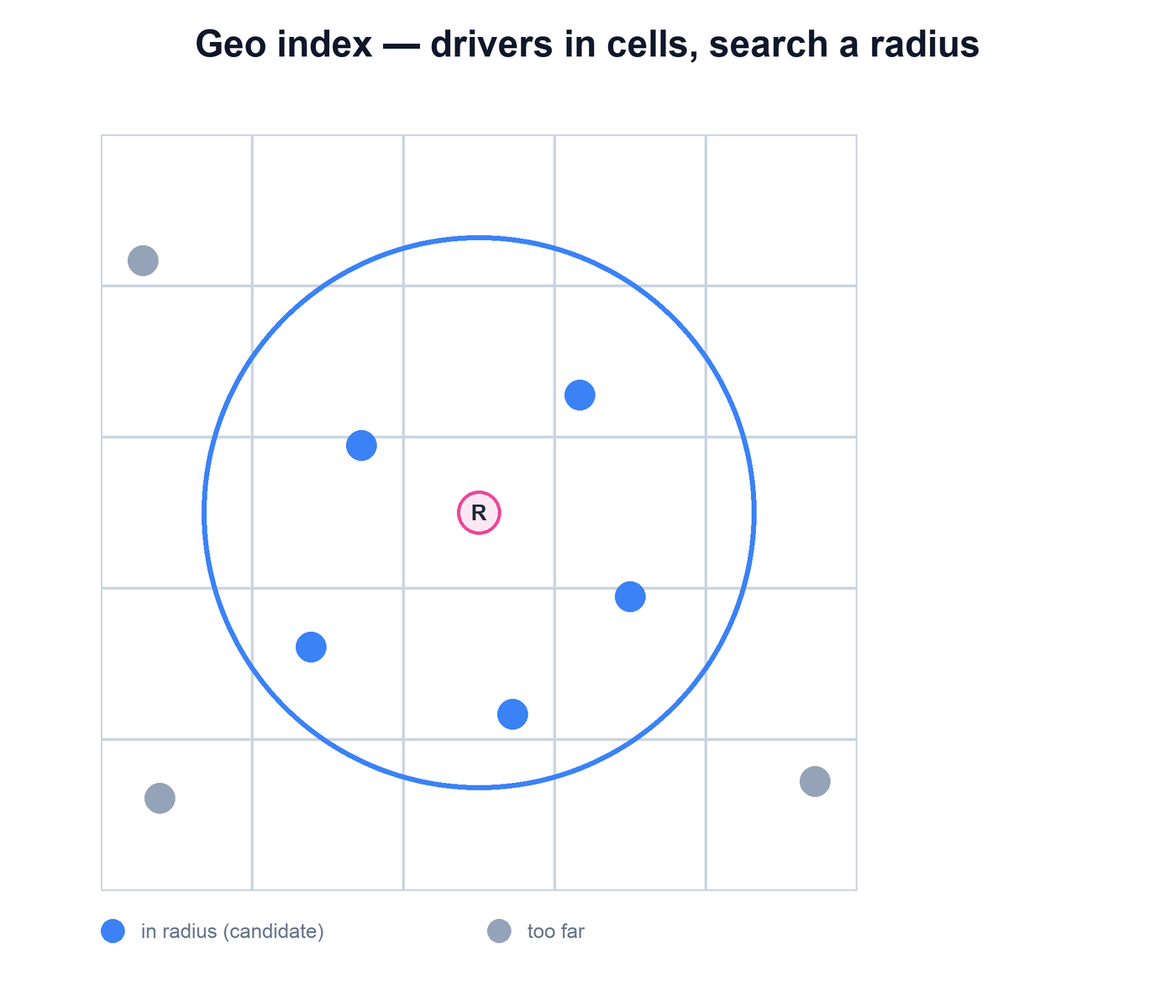
The difference from a static proximity service is churn: entries are constantly being overwritten as drivers move, and they carry a freshness timestamp so the matcher can ignore a driver whose last ping is stale. A driver also has a status — available, offered, or on a trip — and only available drivers are eligible candidates. The index therefore answers a slightly richer question than "who is near here": it is "which available drivers are near here, with a recent location."
function nearby_available(rider_lat, rider_lng, radius):
cells = cells_for(rider_lat, rider_lng, radius) # cell + neighbors
drivers = []
for cell in cells:
for d in geo_index.in_cell(cell):
if d.status == AVAILABLE and fresh(d.ts): # skip stale / busy
if haversine(rider_lat, rider_lng, d.lat, d.lng) <= radius:
drivers.append(d)
return drivers4. The Rider Request Flow
When a rider requests a trip, the matching service runs a short pipeline: find candidate drivers nearby, rank them by who can arrive soonest, then offer and dispatch the best one. Crucially, ranking is by estimated time of arrival, not raw distance — a driver two blocks away stuck behind a closed road may be a worse pick than one slightly farther on an open route.
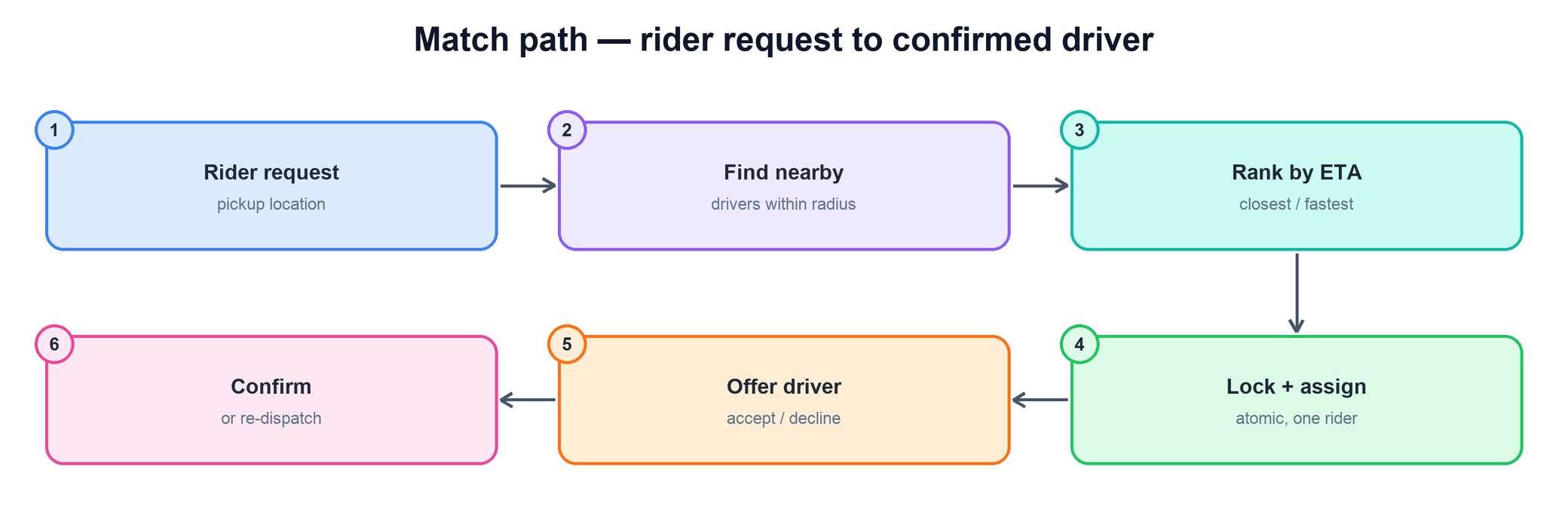
Reading the flow:
- Request. The rider submits a pickup location (and destination). The matching service receives it.
- Find nearby. Query the geospatial index for available drivers within a radius of the pickup point.
- Rank by ETA. Order candidates by estimated arrival time, factoring in road network and traffic, not just straight-line distance.
- Lock and assign. Atomically reserve the top driver so no other request can grab them — this is the step that guarantees exactly-once assignment.
- Offer and confirm. Present the trip to the driver. On acceptance, confirm the match; on decline or timeout, release and move to the next candidate.
5. The Concurrency Problem
This is the heart of the design and the part most likely to be probed. Imagine two riders a block apart request rides at nearly the same instant. Both matching requests query the index, and both see the same idle driver as their best candidate. If each simply "assigns" that driver, you have double-booked one driver to two riders — a correctness bug no amount of retry logic fixes after the fact.
The fix is to make the assignment atomic: reserving a driver must be a single, indivisible operation that exactly one request can win. Concretely, you acquire a lock (or perform an atomic compare-and-set on the driver's status) keyed by driver id before offering the trip. The first request flips the driver from available to offered and proceeds; the second finds the driver no longer available, skips them, and falls through to its next-best candidate.
function try_assign(driver_id, rider_id):
# atomic: only one request can flip AVAILABLE -> OFFERED
ok = geo_index.compare_and_set(
driver_id, expect=AVAILABLE, set=OFFERED)
if not ok:
return False # someone else grabbed this driver
offer(driver_id, rider_id)
return True
function match(rider):
for d in rank_by_eta(nearby_available(rider.lat, rider.lng, R)):
if try_assign(d.id, rider.id): # first winner stops the loop
return d
return NO_DRIVER # none could be reserved6. Decline, Timeout, and Re-dispatch
Reserving a driver is not the end — drivers are people who can ignore or reject an offer, so the system must handle the offer not turning into a trip. Once a driver is locked and offered, three things can happen, and the design needs an answer for each.
| Outcome | What the system does |
|---|---|
| Driver accepts | Confirm the trip; the driver moves to on-trip and is removed from the candidate pool. |
| Driver declines | Release the lock (status back to available) and re-dispatch to the next-best candidate. |
| Offer times out | A no-response is treated like a decline: release the reservation and re-dispatch, so a silent driver never strands a rider. |
The timeout is essential. Without it, a driver who locks the screen or loses signal would hold a reservation indefinitely, stranding the rider on a driver who is never going to accept. By bounding how long an offer is held, the system guarantees forward progress: every offer is resolved within seconds, one way or another, and the rider keeps moving down the ranked list of candidates until someone accepts or the list is exhausted.
function on_offer_result(driver_id, rider_id, result):
if result == ACCEPTED:
geo_index.set_status(driver_id, ON_TRIP)
confirm(rider_id, driver_id)
else: # declined OR timed out
geo_index.set_status(driver_id, AVAILABLE) # release
re_dispatch(rider_id) # try the next candidate7. ETA and Supply/Demand
Two pieces of intelligence make the matching genuinely good rather than merely correct. The first is ETA estimation: the time for a driver to reach the rider depends on the road network and current traffic, so the system estimates travel time along real routes rather than comparing straight-line distances. Ranking by ETA is what makes the offered driver the one who actually arrives first, which is what the rider experiences as a good match.
The second is the broader supply and demand picture. At any moment a city has a shifting balance of available drivers (supply) against waiting riders (demand), and that balance varies sharply by neighborhood and time. The system tracks it both to set expectations (longer waits where supply is thin) and, in mature designs, to nudge behavior — surfacing where demand is high so supply can follow. For the core matching problem, the relevant point is that candidate availability is dynamic: a cell that was driver-rich a minute ago may be empty now, which is exactly why the index must stay fresh and the matcher must tolerate "no driver found" and retry.
8. Separating the Services
The single most important structural decision is to split the high-write location service from the matching service. They have opposite profiles — one is a write firehose with disposable data, the other does relatively rare but logically heavy work that must be exactly-once — and forcing them into one component makes both worse.
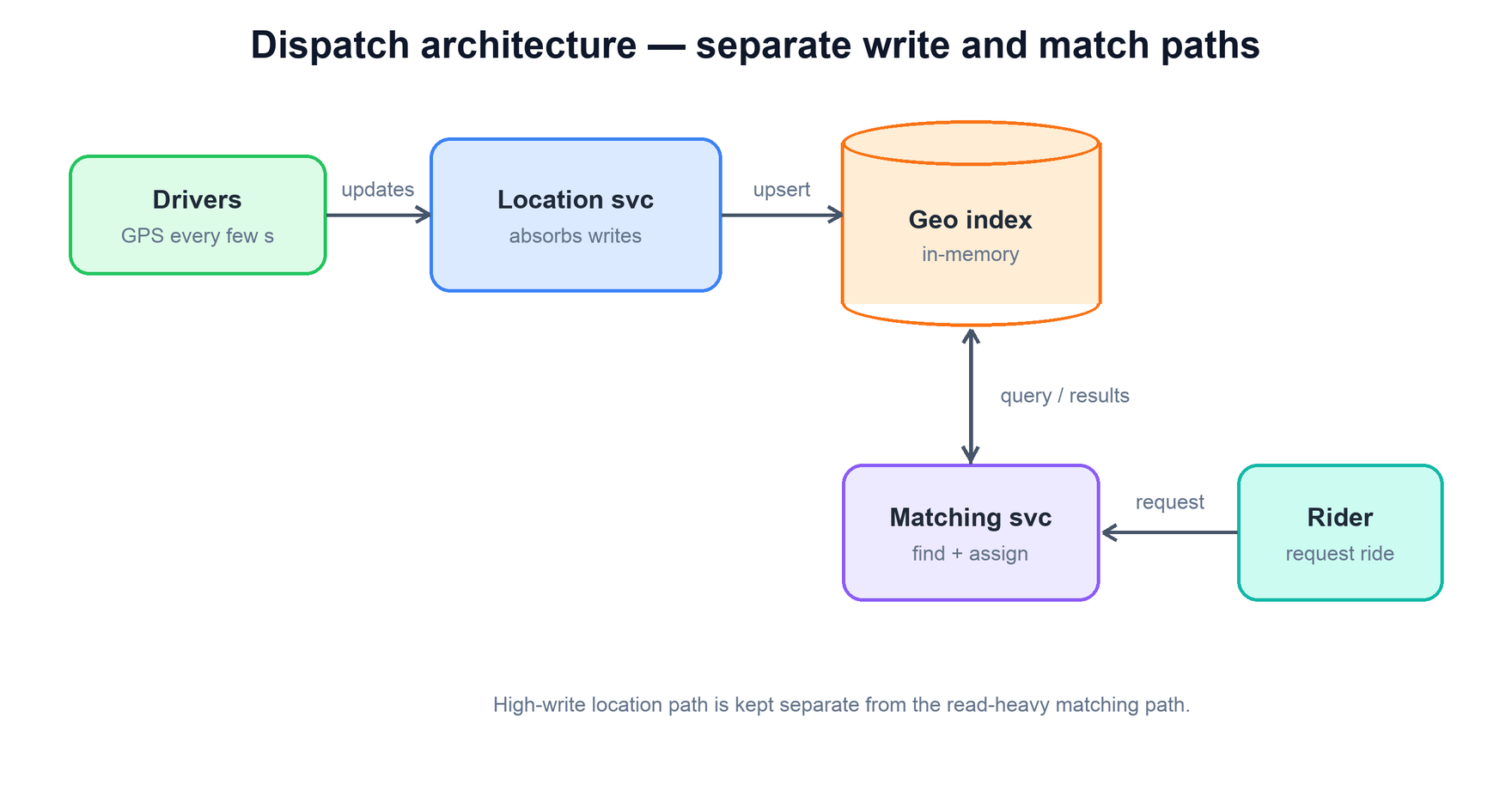
- Location service. Optimized purely for ingesting the update firehose and keeping the geo index current. It can be scaled and tuned independently for write throughput.
- Matching service. Reads the index, ranks by ETA, and performs the atomic lock-and-assign. Its correctness logic is isolated from the noise of constant location writes.
- Shared geo index. The in-memory spatial store both sides touch — written by the location service, read and status-mutated by the matcher.
This separation means a surge of location pings cannot starve the matching logic, and a flurry of ride requests cannot back up location ingestion. Each side scales on its own axis, and the geo index is the clean, narrow contract between them.
9. Summary
Ride matching is a high-write geospatial index feeding an exactly-once assignment engine. The design is a set of choices that keep those two halves fast and correct:
| Concern | Mechanism |
|---|---|
| How do we track constantly-moving drivers? | A write-dominated location pipeline that upserts the latest position every few seconds. |
| Where do driver locations live? | A fast, in-memory, frequently overwritten geospatial index (geo store or quadtree). |
| How do we find candidates for a rider? | Query the index for available, fresh drivers in the rider's cell plus neighbors, within a radius. |
| Which driver do we offer? | Rank candidates by ETA over the road network, not by straight-line distance. |
| How do we avoid double-booking a driver? | An atomic lock / compare-and-set on driver status — exactly one request wins. |
| What if the driver declines or goes silent? | Release the reservation on decline or timeout and re-dispatch to the next candidate. |
| How do we keep the system scalable? | Separate the high-write location service from the read-and-assign matching service. |