Redis — Internal Architecture
A developer's guide to how Redis actually works under the hood: the single-threaded event loop, the data structures and their encodings, the RESP protocol, expiry and eviction, persistence, replication, and how it scales out with Sentinel and Cluster.
Redis is an in-memory data structure server. Unlike a traditional database that keeps data on disk and caches hot pages in memory, Redis keeps the entire dataset in RAM and treats disk only as a durability backstop. Its second defining choice is that command execution is single-threaded: one logical thread runs commands one at a time, which removes locks and makes every individual command atomic. Those two decisions — memory-resident data and a single-threaded execution model — explain almost everything else about how Redis behaves, from its microsecond latencies to the way it persists, replicates, and shards. This guide walks through the internals a developer needs to reason about Redis confidently.
Contents
1. Design Goals and Core Ideas
Every internal decision in Redis traces back to a small set of goals. Keeping them in mind makes the rest of the architecture predictable.
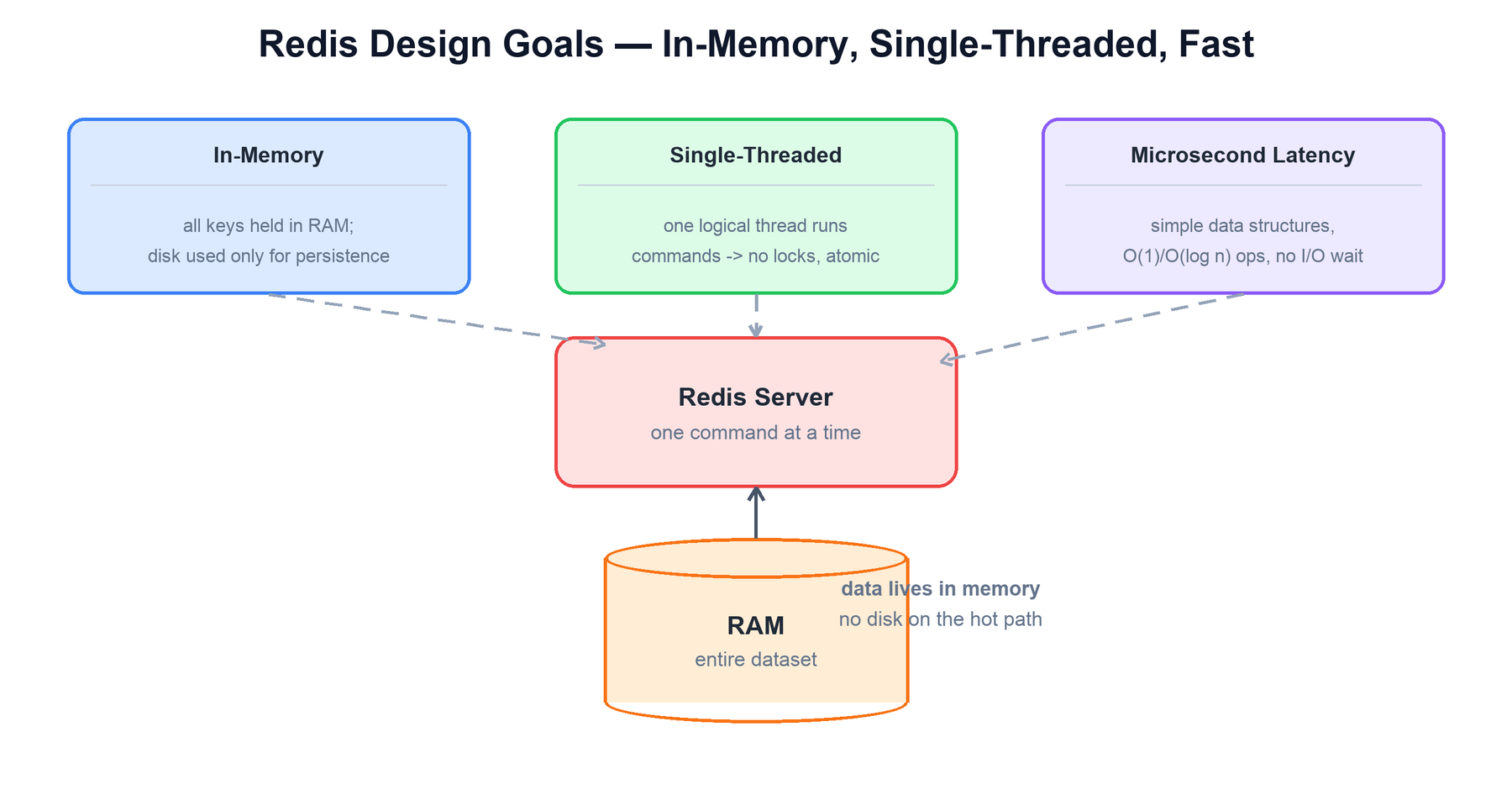
| Goal | How Redis achieves it |
|---|---|
| Microsecond latency | All data is in memory; operations are O(1) or O(log n) on purpose-built data structures, with no disk seek on the hot path. |
| Simplicity and atomicity | A single thread runs commands serially. No locks, no race conditions between commands; each command is atomic by construction. |
| Rich data types as a server | Redis is not just a string cache. Lists, hashes, sets, sorted sets, and streams let the server do work that would otherwise round-trip to the client. |
| Predictable performance | Memory layout and encodings are tuned so common operations cost the same regardless of dataset size. |
| Optional durability | Persistence (RDB, AOF) is configurable. You choose the trade-off between speed and how many recent writes you can afford to lose. |
2. Architecture and the Event Loop
At its core Redis is a single process running an event loop. It uses the operating system's efficient I/O readiness mechanism (epoll on Linux, kqueue on BSD/macOS) to wait for many client sockets at once and wake up only when one of them has data ready. There is no thread per connection; one thread multiplexes thousands of clients.
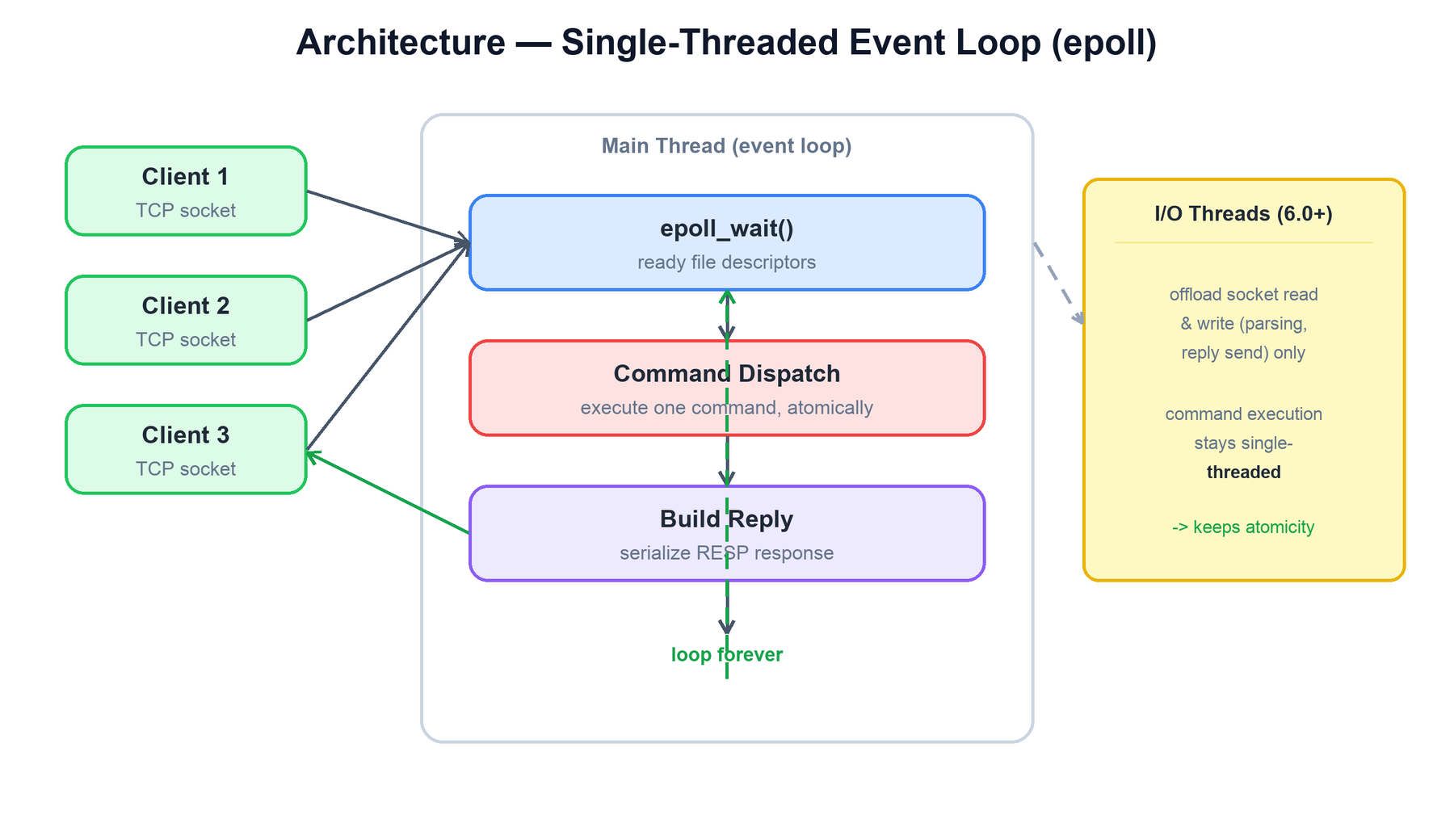
One iteration of the loop does the following:
- Poll for readiness:
epoll_wait()returns the set of file descriptors that have data to read or room to write. Redis registers a callback per event type. - Read and parse: for a readable client socket, Redis reads the bytes and parses the RESP request into a command plus arguments.
- Dispatch and execute: the command name is looked up in the command table and executed against the keyspace. Because this happens on one thread, the command runs to completion with nothing else touching the data — that is the source of atomicity.
- Build and queue the reply: the result is serialized into RESP and queued on the client's output buffer, to be written when the socket is writable.
- Run background work: the loop also fires time events — active expiration, incremental rehashing, client timeouts, and similar housekeeping.
I/O threads (Redis 6.0+). Profiling showed that on busy servers a large share of CPU was spent in the kernel reading request bytes and writing reply bytes, not in executing commands. Redis 6 added an optional pool of I/O threads that parallelize only the socket read/parse and reply-write steps. The actual command execution remains single-threaded, so atomicity and the no-locks model are preserved while throughput on multi-core machines improves.
while server_running:
events = epoll_wait(fds) # block until sockets ready
for fd in events.readable:
buf = read(fd) # (optionally on an I/O thread)
cmd, args = parse_resp(buf)
reply = dispatch(cmd, args) # executes on the MAIN thread, atomically
queue_output(fd, reply)
for fd in events.writable:
write(fd, output_buffer[fd]) # (optionally on an I/O thread)
run_time_events() # expiry, rehashing, timeouts3. Data Structures and Internal Encodings
Redis exposes a handful of data types — string, list, hash, set, sorted set, and stream — but each type can be stored internally in more than one way. Redis picks a compact encoding when a value is small and transparently upgrades to a general encoding once it grows past a configurable threshold. The command behavior is identical; only memory layout and performance characteristics change.
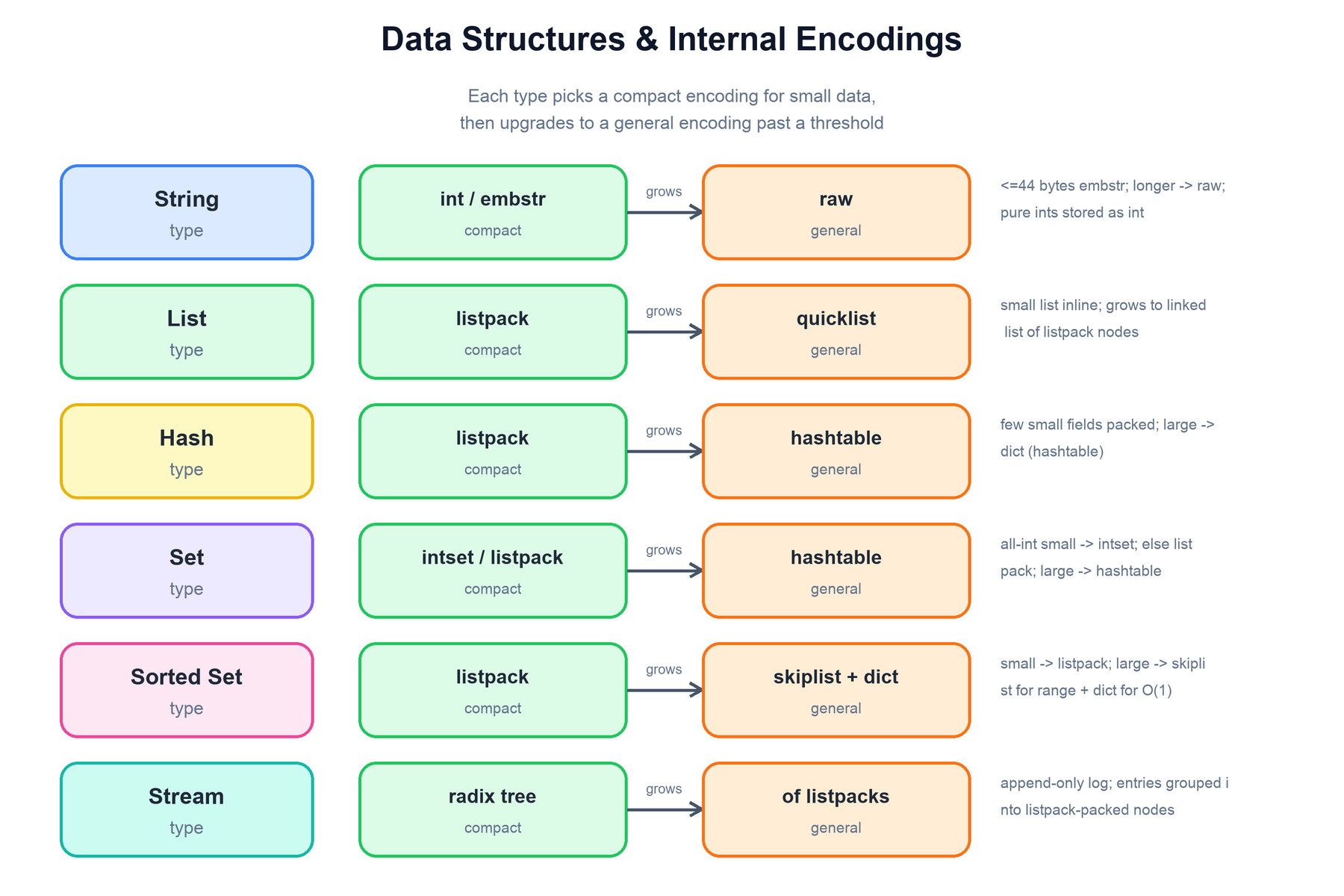
The key encodings are:
| Type | Encodings | How it works |
|---|---|---|
| String | int, embstr, raw | A value that is a valid integer is stored as a boxed long (int). Short strings (≤ 44 bytes) use embstr, which allocates the header and the bytes in one contiguous block. Longer or modified strings use raw. |
| List | listpack → quicklist | A small list is a single listpack (a flat, packed byte array). As it grows it becomes a quicklist: a doubly linked list whose nodes are each a listpack, balancing memory density against fast end operations. |
| Hash | listpack → hashtable | Few small field/value pairs are packed into one listpack and scanned linearly. Past the threshold it becomes a real hash table (dict) for O(1) field access. |
| Set | intset / listpack → hashtable | A set of only integers uses a sorted intset. A small mixed set uses a listpack. Large sets become a hash table (keys only). |
| Sorted Set | listpack → skiplist + dict | Small zsets use a listpack. Large ones combine a skip list (ordered by score, for range queries) with a dict (member → score, for O(1) lookups). |
| Stream | radix tree of listpacks | An append-only log keyed by time-ordered IDs. Entries are grouped into listpack-packed nodes indexed by a radix tree, with consumer-group state tracked alongside. |
hash-max-listpack-entries, set-max-intset-entries). The trade-off is always the same: compact encodings save memory and have great cache locality but are O(n) to scan, so they are only used while n is small. Once a structure is large, Redis pays the per-element overhead of a general structure to keep operations cheap.4. RESP Protocol and Command Flow
Clients talk to Redis using RESP (REdis Serialization Protocol) — a simple, line-oriented, binary-safe protocol that is easy to parse and human-readable on the wire. A request is an array of bulk strings: the command name followed by its arguments. The reply is a single RESP value whose type depends on the command.
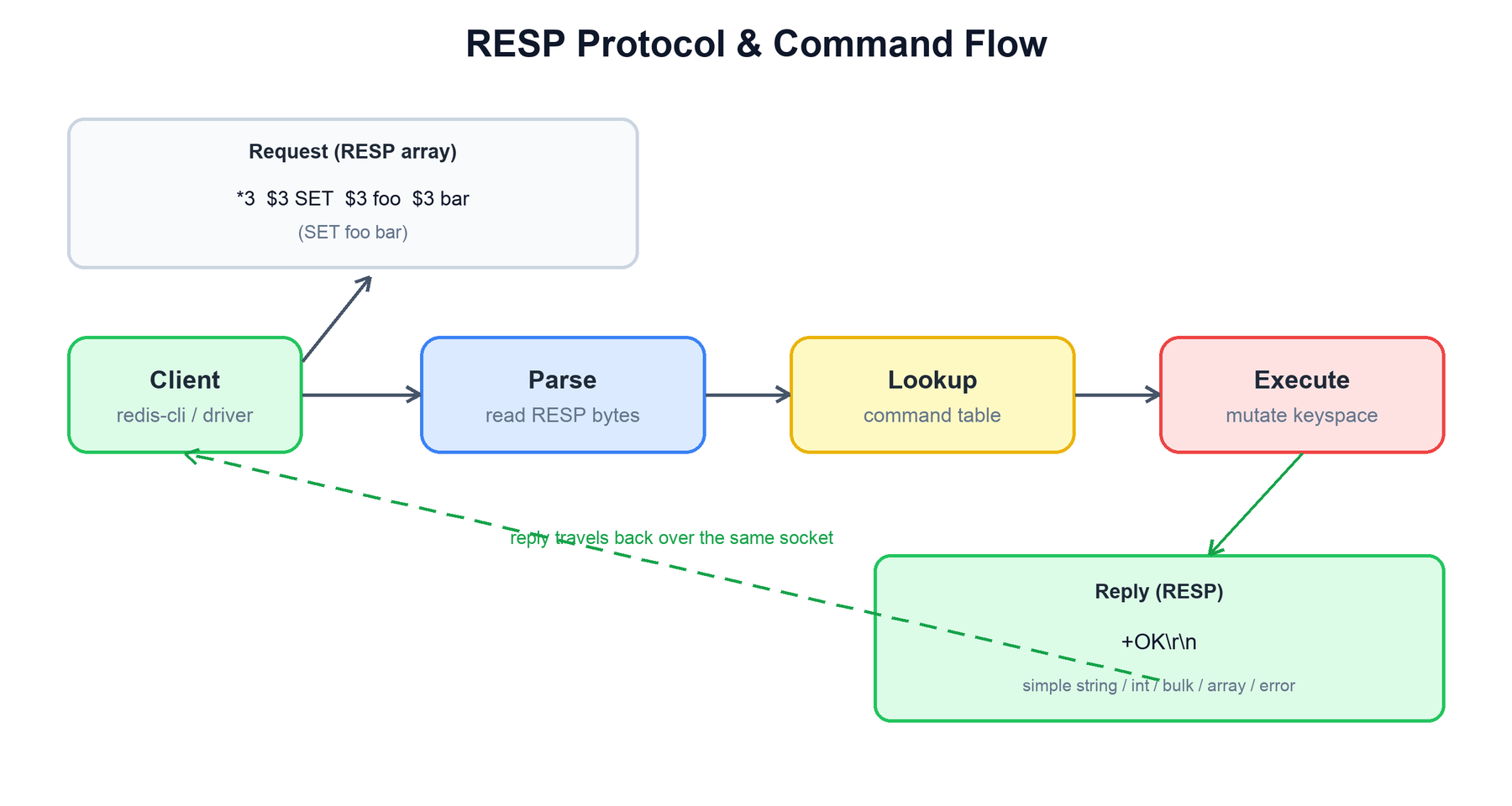
RESP uses a one-byte type prefix to tell the parser what follows:
| Prefix | Type | Example |
|---|---|---|
+ | Simple string | +OK\r\n |
- | Error | -WRONGTYPE ...\r\n |
: | Integer | :1000\r\n |
$ | Bulk string (length-prefixed, binary-safe) | $3\r\nbar\r\n |
* | Array | *2\r\n...\r\n...\r\n |
The full flow for a single command is short, which is the point — minimal per-command overhead:
# Client sends: SET foo bar -> *3\r\n$3\r\nSET\r\n$3\r\nfoo\r\n$3\r\nbar\r\n
function handle_request(socket):
bytes = socket.read()
argv = parse_resp(bytes) # ["SET", "foo", "bar"]
cmd = command_table.lookup(argv[0])
if cmd is None:
return reply_error("unknown command")
if not cmd.arity_ok(argv):
return reply_error("wrong number of arguments")
result = cmd.proc(argv) # mutate the keyspace, atomically
return encode_resp(result) # "+OK\r\n"Pipelining falls out of this design for free: a client may send many requests back to back without waiting for each reply. Redis reads them all, executes them in order, and sends the replies in order, which amortizes network round-trip time across many commands. MULTI/EXEC transactions go one step further by queuing commands and executing the whole batch as one uninterrupted unit on the single thread.
5. Expiry and Eviction
Two different mechanisms reclaim memory, and they solve two different problems. Expiry removes keys whose TTL has elapsed. Eviction removes keys (whether or not they have a TTL) when the server is at its memory limit and needs room for a new write.
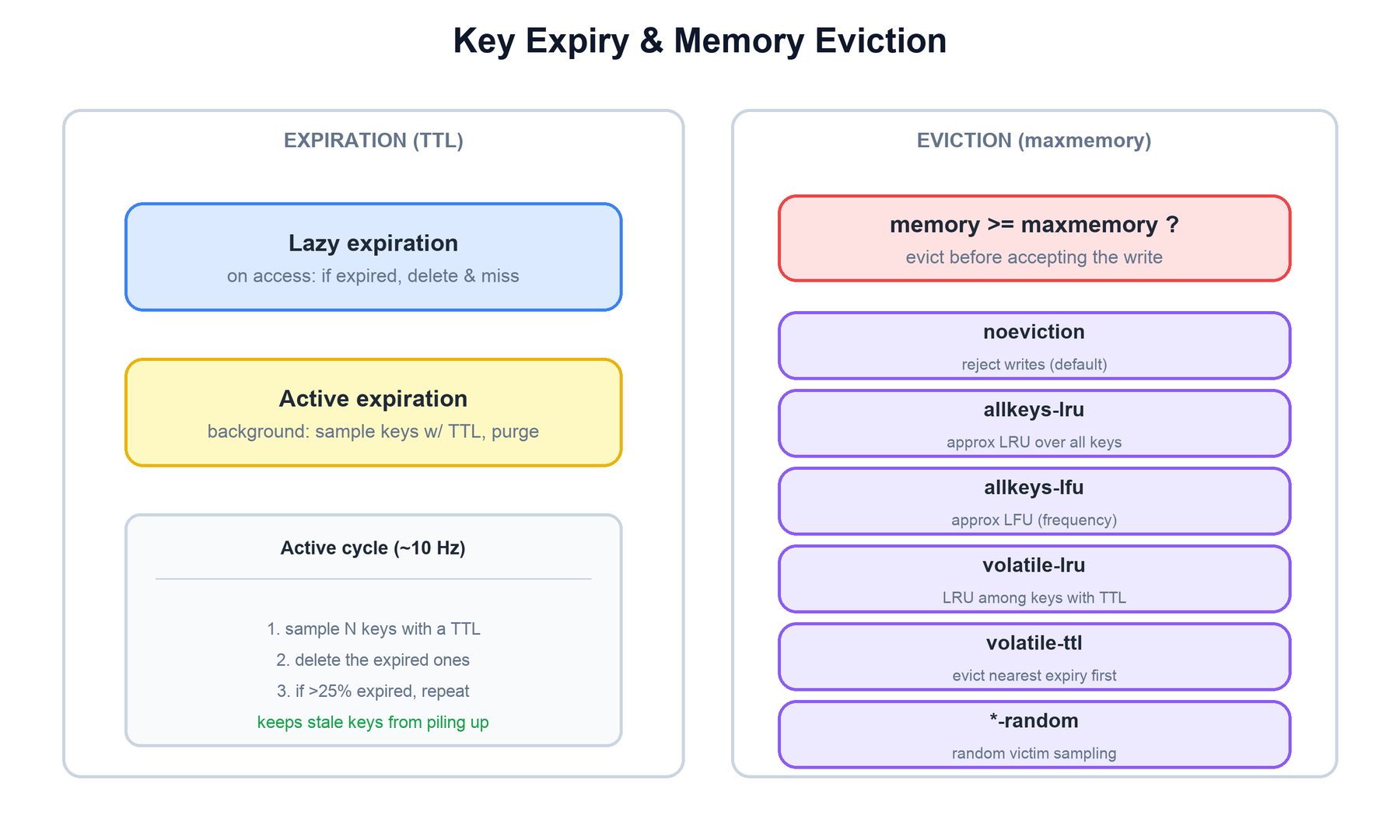
Expiration: lazy plus active
Redis never scans every key to check TTLs — that would be far too expensive. Instead it combines two strategies:
- Lazy expiration: when a key is accessed, Redis checks its TTL first. If it has expired, the key is deleted on the spot and the command behaves as a miss. This guarantees you never read a stale value.
- Active expiration: a background cycle (roughly ten times per second) samples a batch of keys that have a TTL, deletes the expired ones, and — if more than about a quarter of the sample turned out to be expired — repeats immediately. This probabilistic sweep keeps expired-but-untouched keys from accumulating in memory.
Eviction: maxmemory policies
When maxmemory is set and a write would exceed it, Redis evicts keys according to the configured policy before accepting the write. LRU and LFU are approximations: rather than maintaining a globally ordered list (expensive), Redis samples a handful of keys and evicts the best candidate from the sample, which is close to true LRU/LFU at a fraction of the cost.
| Policy | What it evicts |
|---|---|
noeviction | Nothing. Writes that need memory return an error. The default. |
allkeys-lru | The approximately least-recently-used key, from all keys. |
allkeys-lfu | The approximately least-frequently-used key (tracks access frequency, decays over time). |
volatile-lru / volatile-lfu | Same as above, but only among keys that have a TTL set. |
volatile-ttl | The key with the nearest expiration time. |
allkeys-random / volatile-random | A random key (from all keys, or from keys with a TTL). |
6. Persistence: RDB and AOF
Because data lives in RAM, a restart loses everything unless it has been written to disk. Redis offers two persistence mechanisms with different trade-offs, and a hybrid that combines them.
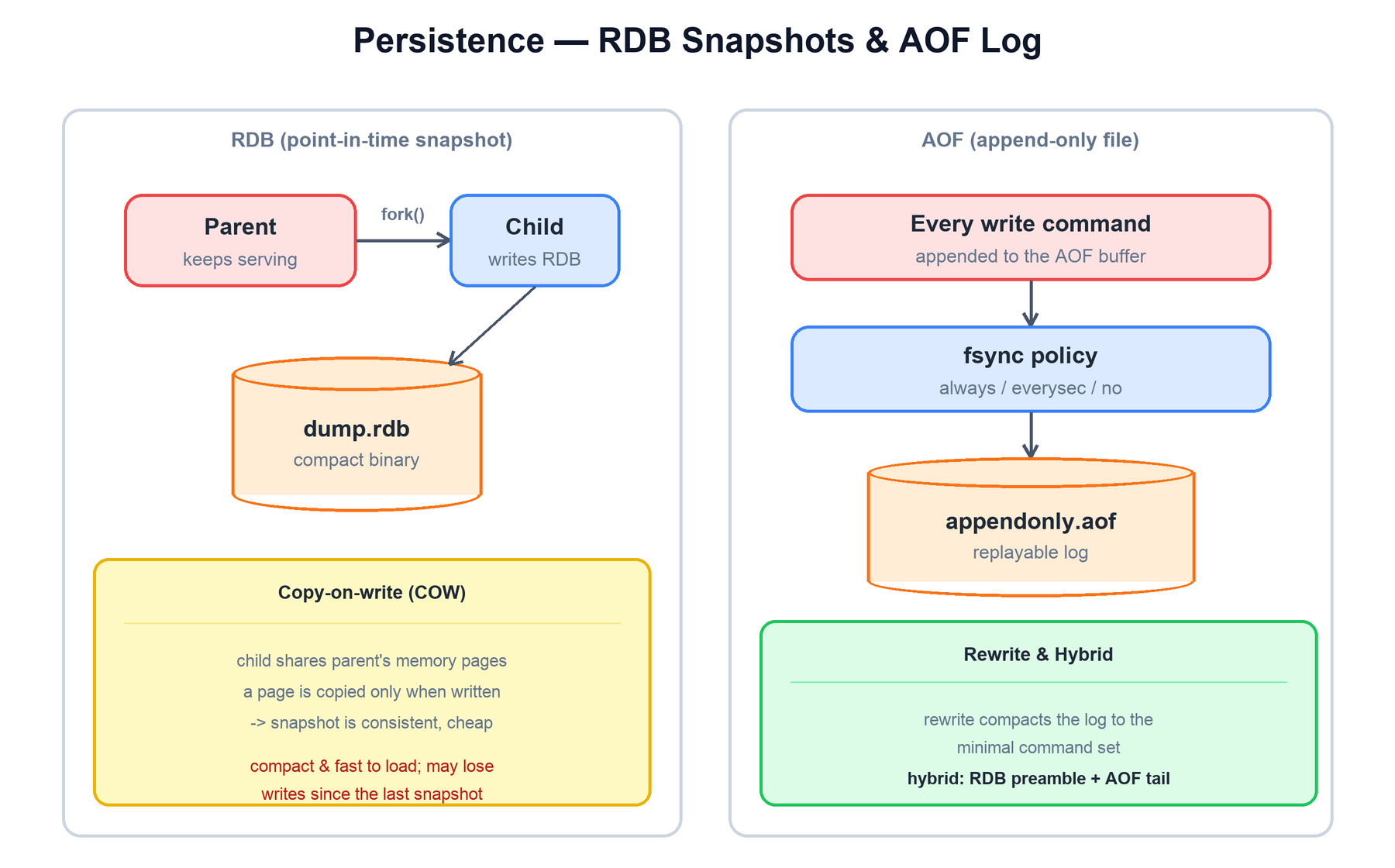
RDB: point-in-time snapshots
An RDB snapshot is a compact binary dump of the whole dataset at a moment in time. To take one without blocking, the parent process calls fork(). The child inherits a copy of the parent's memory and writes the snapshot to dump.rdb, while the parent keeps serving clients. This is cheap because of the operating system's copy-on-write: parent and child share the same physical memory pages, and a page is only duplicated when one of them writes to it. The snapshot the child sees is therefore consistent and frozen, even as the parent continues mutating data.
RDB files are small and load quickly, which makes them ideal for backups and fast restarts. The downside is the window of loss: anything written since the last snapshot is gone if the process dies.
AOF: append-only file
The Append Only File logs every write command as it is executed. On restart, Redis replays the log to reconstruct the dataset. How much you can lose depends on the fsync policy:
| fsync policy | Durability vs. speed |
|---|---|
always | fsync after every write. Safest, slowest. |
everysec | fsync once per second. At most one second of writes at risk. The recommended default. |
no | Let the OS decide when to flush. Fastest, least safe. |
Because the AOF grows without bound, Redis periodically performs an AOF rewrite: it forks a child that writes a new, minimal log representing the current dataset (for example collapsing a hundred increments into a single SET), again using copy-on-write so the parent is not blocked.
Hybrid RDB + AOF
Modern Redis defaults to a hybrid format: an AOF rewrite begins with an RDB-format preamble (the compact snapshot) followed by an AOF tail of the commands that arrived during and after the rewrite. This gives the fast loading of RDB with the small loss window of AOF — the best of both.
# RDB snapshot (non-blocking via fork + copy-on-write)
function save_rdb():
pid = fork()
if pid == 0: # child
write_snapshot_to("dump.rdb") # sees frozen, consistent memory
exit()
# parent keeps serving; COW copies a page only when written
# AOF on every write
function on_write(cmd):
apply(cmd)
aof_buffer.append(serialize(cmd))
# flushed to disk per the fsync policy (always / everysec / no)7. Replication
Redis replication is asynchronous and leader-based: one master accepts writes and streams them to one or more replicas, which serve read-only copies. A master does not wait for replicas to acknowledge before replying to the client, which keeps write latency low at the cost of a small replication lag.
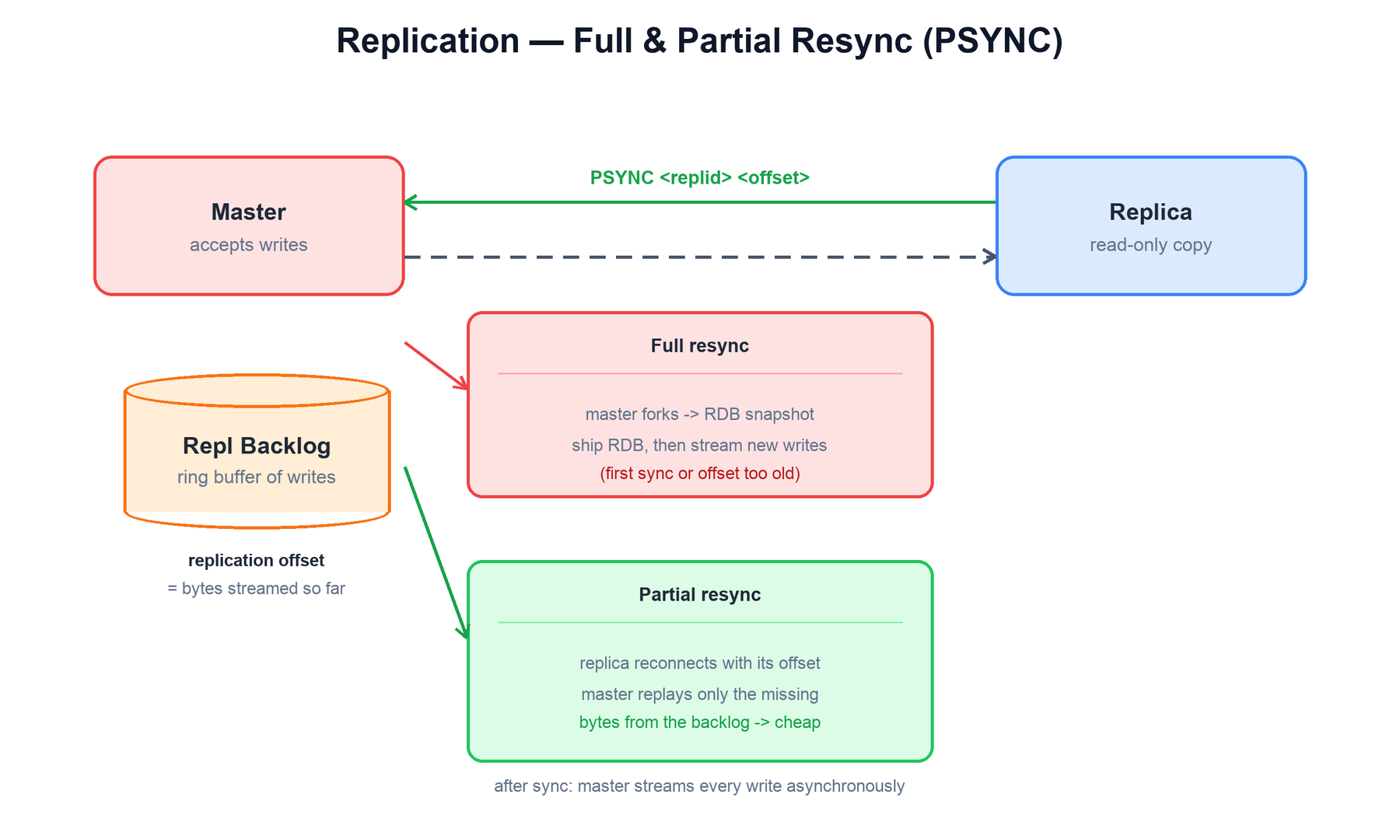
The synchronization protocol is PSYNC, which supports two paths:
- Full resync. Used on first contact or when a replica has fallen too far behind. The master produces an RDB snapshot (forking as in persistence), sends it to the replica, and meanwhile buffers every new write so it can stream them once the snapshot transfer finishes. The replica loads the RDB, then applies the buffered stream.
- Partial resync. Used when a replica briefly disconnects and reconnects. Each master keeps a replication backlog — a fixed-size ring buffer of the most recent write stream — and tracks a replication offset, the number of bytes streamed so far. The replica reconnects citing its last offset and the master's replication ID; if those bytes are still in the backlog, the master replays only the gap. This avoids a full snapshot for a transient blip.
After either path, the master simply keeps streaming each new write command to its replicas as it executes them. Replicas can themselves have sub-replicas (chained replication), forming a tree that offloads fan-out from the master.
# replica connects (or reconnects) to its master
function replica_sync(master):
send(master, "PSYNC " + known_replid + " " + last_offset)
resp = recv(master)
if resp == "FULLRESYNC":
rdb = recv_rdb(master) # master forked + snapshotted
load_into_memory(rdb)
last_offset = resp.offset
else: # CONTINUE -> partial resync
pass # keep current data; just resume
while connected:
cmd = recv_stream(master) # async stream of writes
apply(cmd)
last_offset += len(cmd)WAIT command lets a client block until a write has reached a given number of replicas, trading latency for a stronger durability guarantee when you need it.8. High Availability and Scale
Replication by itself gives you read scaling and a warm copy, but a human still has to react when the master dies, and the whole dataset must fit on one machine. Redis solves the first problem with Sentinel and the second with Cluster.
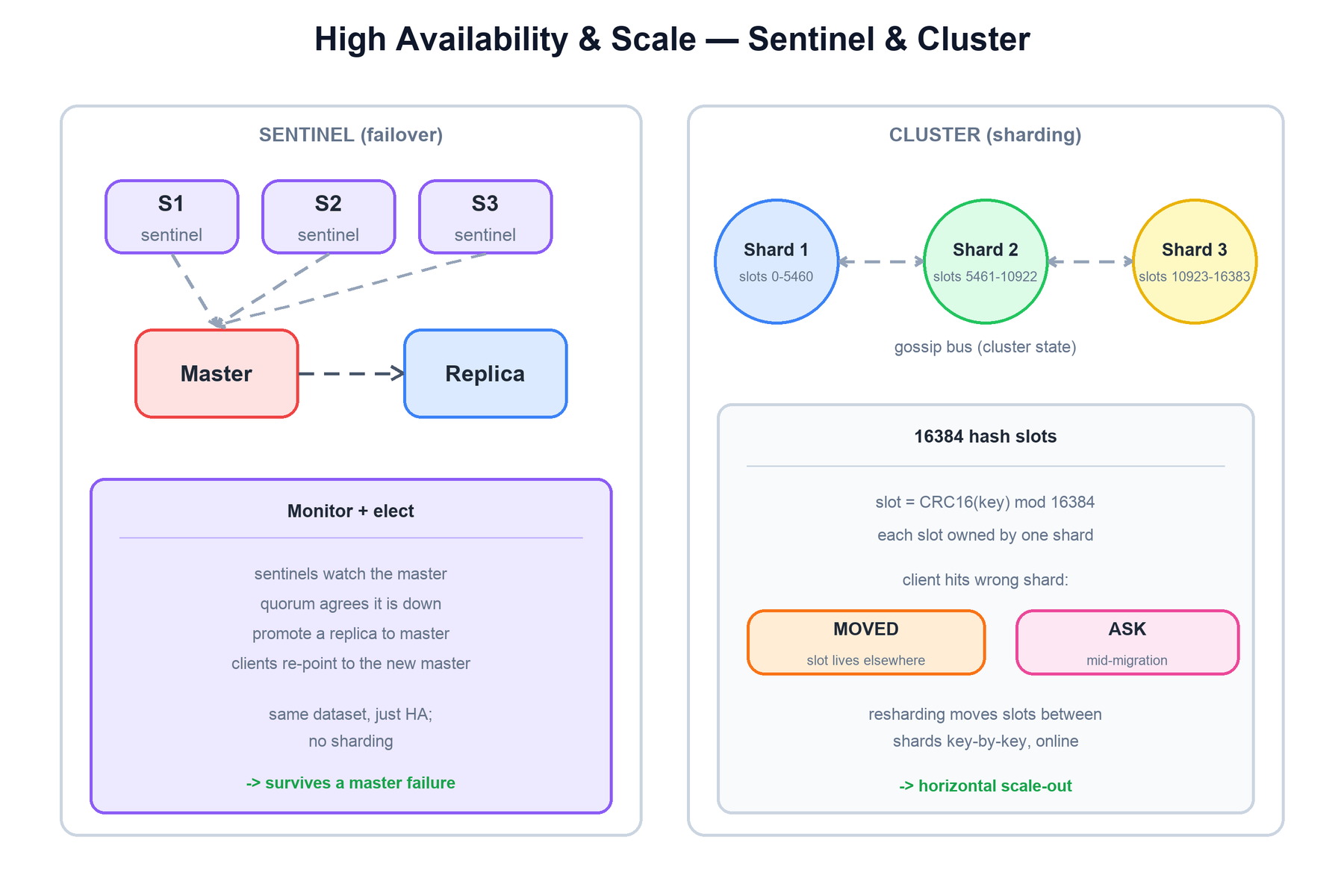
Sentinel: automatic failover
Sentinel is a separate process (run in odd numbers, typically three or five, for quorum) that monitors a master and its replicas. When enough sentinels agree the master is unreachable, they elect a leader among themselves, promote a suitable replica to master, reconfigure the other replicas to follow it, and tell clients where the new master is. Sentinel provides high availability but not sharding — the entire dataset still lives on one master at a time.
Cluster: sharding the keyspace
Redis Cluster partitions the keyspace across many master shards. The mechanism is a fixed map of 16384 hash slots. Every key is assigned to a slot by CRC16(key) mod 16384, and every slot is owned by exactly one shard. To distribute data you simply distribute slot ownership; each shard typically also has replicas for HA, so Cluster folds in the Sentinel-style failover too.
| Concept | What it does |
|---|---|
| Hash slots (16384) | A coarse, fixed partitioning of the keyspace. Moving data between shards means reassigning slots, not rehashing every key. |
| CRC16 hashing | slot = CRC16(key) mod 16384 maps a key to a slot deterministically on every client and node. |
| Gossip bus | Nodes exchange cluster state (who owns which slots, who is up) over a separate cluster bus port, so every node converges on the full topology without a central registry. |
| MOVED redirect | If a client sends a key to the wrong shard, the node replies MOVED <slot> <addr>; the client retries against the correct shard and caches the mapping. |
| ASK redirect | During a slot migration, a key may have moved already. The owner replies ASK to send that one request to the new shard without invalidating the client's whole slot map. |
Resharding moves slots from one shard to another online, key by key, while the cluster keeps serving traffic. The combination of a fixed slot count, deterministic CRC16 hashing, and MOVED/ASK redirects lets the cluster rebalance without a coordinator and without taking the keyspace offline.
# client-side routing in a Redis Cluster
function cluster_route(key):
slot = crc16(hash_tag(key)) % 16384 # {tag} forces co-location
node = slot_map[slot] # cached topology
resp = send(node, command)
if resp.is_moved(): # wrong shard, topology changed
slot_map[resp.slot] = resp.addr # update cache
return send(resp.addr, command)
if resp.is_ask(): # slot mid-migration
return send(resp.addr, ASKING + command) # one-shot redirect
return resp{...} substring in the key, e.g. user:{42}:profile and user:{42}:sessions — makes only the braced part feed CRC16, guaranteeing related keys share a slot and can be operated on together.9. Summary
The whole system is built from a few reinforcing ideas:
| Concern | Mechanism |
|---|---|
| Why is it fast? | Entire dataset in RAM; simple O(1)/O(log n) structures; no disk on the hot path. |
| Why are commands atomic? | A single thread executes one command at a time; no locks, no inter-command races. |
| How does it stay multi-core friendly? | Optional I/O threads parallelize socket read/write only; execution stays single-threaded. |
| How is memory kept small? | Compact encodings (listpack, intset, embstr) for small values, upgraded to general structures past a threshold. |
| How are clients served? | The simple, binary-safe RESP protocol over an epoll event loop, with free pipelining. |
| How is memory reclaimed? | Lazy + active TTL expiration; sampled LRU/LFU eviction at the maxmemory limit. |
| How is data made durable? | RDB snapshots (fork + copy-on-write) and the AOF log, combined in a hybrid format. |
| How does it survive failure? | Async replication (full/partial resync via PSYNC) plus Sentinel for automatic failover. |
| How does it scale out? | Cluster shards the keyspace into 16384 CRC16 hash slots, redirecting clients with MOVED/ASK. |