Designing a Rate Limiter
A system design interview guide to building a rate limiter: why you need one, where it sits, the classic algorithms and their tradeoffs, and how to make it correct and fast in a distributed setting.
A rate limiter controls how many requests a client may send to a service in a given window of time. When a client stays under its allowance, requests pass through to the service; when it exceeds the allowance, the limiter rejects or defers the extra requests instead of letting them reach the backend. This sounds simple, but a good design has to answer several harder questions: which algorithm decides what "too many" means, where the limiter physically lives, how it stays accurate when many requests arrive at once, and how multiple limiter instances agree on a single count. This guide walks through each of those decisions in the order an interview usually takes them.
Contents
1. Why Rate Limit
Rate limiting is one of those features that looks like a tax on legitimate traffic until the day it saves the service. There are four distinct reasons to add one, and a strong answer names all of them rather than just "to stop abuse."
| Motivation | What it protects against |
|---|---|
| Abuse and attacks | Brute-force login attempts, credential stuffing, scrapers, and denial-of-service floods. Capping requests per client makes these attacks slow and expensive instead of free. |
| Cost control | Every request consumes CPU, bandwidth, and downstream calls — some of which are billed. A limiter keeps a single noisy client from running up the bill or exhausting a paid third-party quota. |
| Fairness | Without a limit, one heavy user can starve everyone else of capacity. Per-client quotas keep the service responsive for the majority during a spike from a minority. |
| Cascading failure protection | An overloaded service slows down, retries pile up, and the slowness spreads to its callers. Shedding excess load at the edge keeps the backend inside its safe operating range and stops a local overload from becoming an outage. |
2. Where to Place the Limiter
Before choosing an algorithm, decide where the check runs. There are three common placements, and they trade enforceability against blast radius and reuse.
- Client side. The client throttles its own requests before sending them. This is cheap and saves a round trip, but it is unenforceable — anyone can modify the client or forge requests — so it is at best a courtesy, never a security control.
- Server side, inside the application. The service checks the limit as part of handling each request. This is enforceable and has full request context, but every service has to reimplement the logic, and the rejected request still pays for connection setup and routing before it is dropped.
- Middleware or an API gateway. A dedicated layer in front of the services inspects every request and applies the limit before forwarding it. This is the usual choice: it is enforceable, it is shared by all backends behind it, and it sheds excess load early, before it reaches application servers. The cost is one more component to operate and a network hop.
For most designs you choose the gateway/middleware placement. It centralizes the rules, keeps the limiting logic out of every individual service, and rejects bad traffic at the cheapest possible point in the path.
3. Algorithms and Tradeoffs
The heart of the design is the algorithm that decides whether a given request is allowed. Five are worth knowing. They differ in how they track usage, whether they permit bursts, and how much memory and accuracy they cost.
| Algorithm | How it works | Tradeoffs |
|---|---|---|
| Token bucket | A bucket holds up to N tokens and is refilled at a fixed rate. Each request removes one token; if the bucket is empty the request is rejected. Unused tokens accumulate up to the cap. | Simple, memory-cheap (two numbers per client), and allows short bursts up to the bucket size — which is often what you want. Two parameters (capacity and refill rate) to tune. |
| Leaking bucket | Requests enter a FIFO queue of fixed size and are processed ("leak") at a constant rate. A full queue means the request is dropped. | Produces a smooth, steady output rate regardless of bursty input — good for protecting a downstream that needs a stable load. But it cannot absorb bursts, and a full queue adds latency to requests waiting in line. |
| Fixed window counter | Time is split into fixed windows (e.g. each minute). One counter per window per client; increment on each request, reject once it passes the limit, reset at the window boundary. | Trivial to implement and very cheap. Its flaw is the boundary burst: a client can send the full limit at the end of one window and again at the start of the next, briefly doubling the allowed rate across the boundary. |
| Sliding window log | Store a timestamp for every request in a sorted set. On each new request, drop timestamps older than the window, then count what remains; allow only if the count is under the limit. | Exact — no boundary artifact, the limit holds over any rolling window. But it stores one entry per request, so memory grows with traffic, making it expensive for high-volume clients. |
| Sliding window counter | A hybrid that approximates the log using just two fixed-window counters. It weights the previous window's count by how much of it still overlaps the rolling window. | Cheap like fixed window, but smooths out the boundary burst. Slightly approximate (it assumes requests were spread evenly in the previous window), which is acceptable for almost all uses. |
The sliding window counter is worth spelling out, because its formula is the part interviewers most often ask you to derive. The estimated request count for the current rolling window is:
# count over the rolling window =
estimate = current_window_count
+ previous_window_count * overlap_percentage_of_rolling_window
# overlap_percentage = fraction of the previous fixed window
# that still falls inside the rolling window right now
allow if estimate < limitFor example, with a one-minute window and a limit of 100: if the previous minute saw 80 requests, the current minute has 30 so far, and 25% of the previous window still overlaps the rolling window, the estimate is 30 + 80 × 0.25 = 50, which is under 100, so the request is allowed. As the rolling window advances, the previous window's weight shrinks toward zero, smoothly retiring its contribution instead of dropping it all at once like the fixed window does.
4. Architecture with Redis
Put the pieces together. A request from the client hits the rate limiter middleware. The middleware looks up the rules that apply to this client and the counters tracking its recent usage, runs the chosen algorithm, and either forwards the request to the API servers or rejects it. The counters need to be read and written on every request, so they live in a fast in-memory store; the rules change rarely, so they are cached and refreshed in the background.
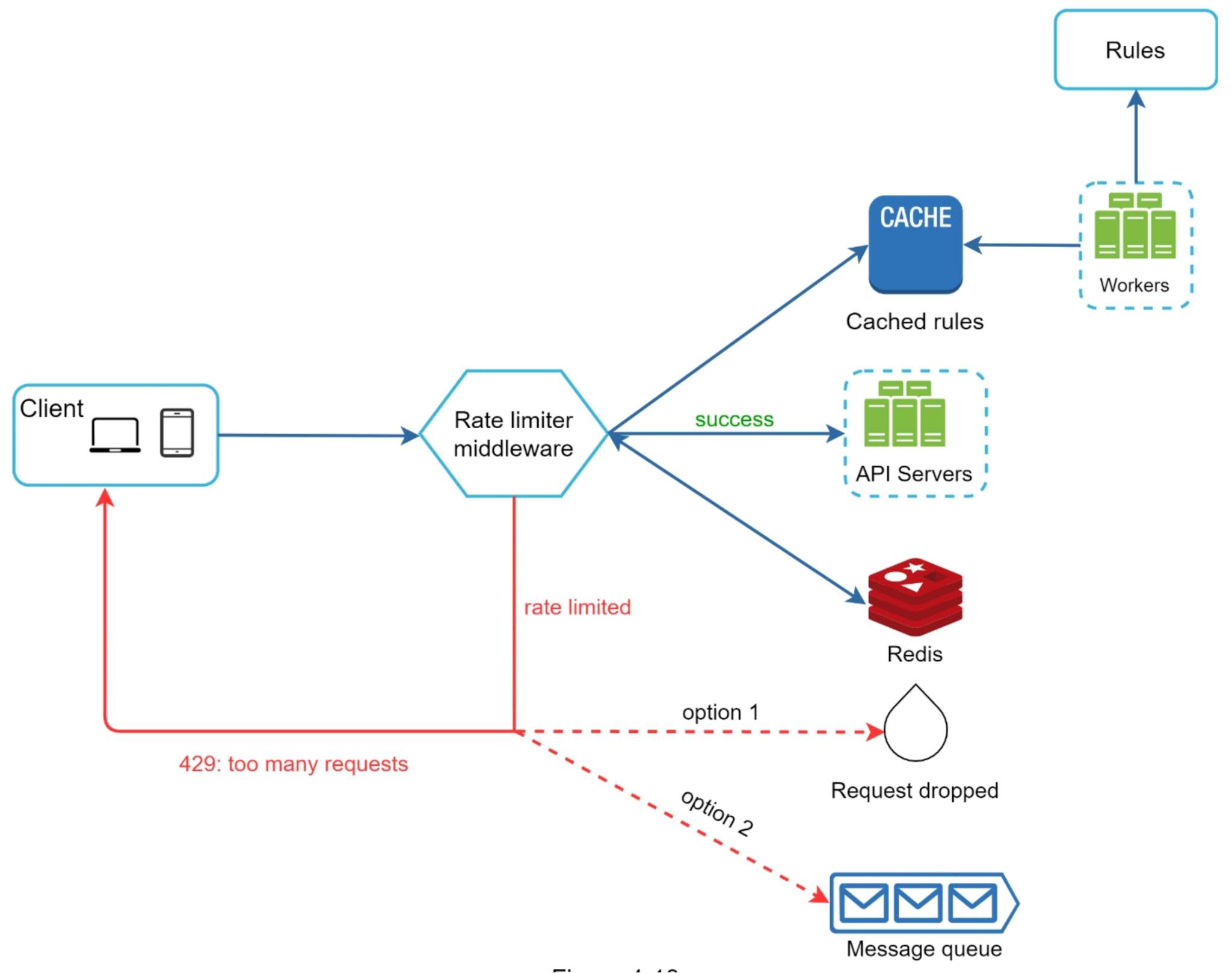
The components are:
- Rate limiter middleware. Sits in front of the API servers. For each request it identifies the client (API key, user ID, or IP), fetches the relevant counter and rule, applies the algorithm, and decides allow or reject.
- Redis (counters). An in-memory key-value store holding the per-client counters. It is chosen because the limiter touches a counter on every single request: an in-memory store gives sub-millisecond reads and writes, and Redis ships with
INCRand key expiration that map directly onto window counting. - Rules cache and workers. The limiting rules (which client gets which limit) are kept in a durable rules store. Background workers periodically load them into an in-memory cache next to the middleware, so the hot path never queries the database. A rule change propagates on the next refresh.
Why an in-memory store rather than a database? Counters change on every request and must be read with very low latency, or the limiter itself becomes the bottleneck it was meant to prevent. A disk-backed database cannot keep up at that rate; Redis can, and its single-threaded command execution plus native counter and TTL primitives make it a natural fit.
The fixed-window check in Redis is two commands — increment the counter for the current window, and set it to expire when the window ends:
function allow(client_id):
key = client_id + ":" + current_window() # e.g. "user42:1719356400"
count = redis.INCR(key) # create at 1 or bump existing
if count == 1:
redis.EXPIRE(key, window_seconds) # auto-clean old windows
return count <= limitThis naive version has a race: between INCR and EXPIRE, or when many requests read the same counter concurrently, two requests can both believe they are under the limit. The fix is to make the read-decide-write sequence atomic by running it as a single Lua script on the Redis server, which executes without interleaving:
# Lua script runs atomically on the Redis server
function allow_atomic(key, limit, window_seconds):
count = redis.call("INCR", key)
if count == 1:
redis.call("EXPIRE", key, window_seconds)
return count <= limit ? 1 : 0
# the whole check is one indivisible operation — no race5. Responding to the Client
When a request is rejected, the limiter returns HTTP 429 Too Many Requests. The status code alone is not enough; a well-behaved client needs to know its limit and when it can try again, so the limiter attaches rate-limit headers to the response.
| Header | Meaning |
|---|---|
X-RateLimit-Limit | The maximum number of requests allowed in the window. |
X-RateLimit-Remaining | How many requests the client has left in the current window. |
X-RateLimit-Retry-After | How many seconds to wait before retrying (sent when the client has been limited). |
Returning these headers on allowed responses too — not just on rejections — lets a well-behaved client slow itself down before it hits the wall, which reduces the number of 429s the system has to generate in the first place.
6. Handling Exceeded Requests
When a request goes over the limit, you have two choices for what to do with it, and the right one depends on whether the work is interactive or deferrable.
- Drop it. Reject the request immediately with a 429 and let the client decide whether to retry. This is the right behavior for interactive, latency-sensitive traffic — a user-facing API call — where a stale, delayed response is worse than a clear "try again."
- Enqueue it for later. Instead of dropping the request, push it onto a message queue to be processed when capacity frees up. This suits asynchronous work that does not need an immediate answer — a batch job, an email send, an event ingestion — where completing the work eventually matters more than completing it now. The cost is added complexity and the need to handle queue growth under sustained overload.
In practice many systems do both: drop excess requests on synchronous, user-facing paths, and enqueue excess work on asynchronous paths where deferral is acceptable.
7. Distributed Challenges
A single limiter instance with a local counter is easy. Real systems run many limiter nodes behind a load balancer, and that introduces two problems the design must address.
- Race conditions. When several requests for the same client land on different nodes (or the same node concurrently) and all read the counter at nearly the same moment, each may see a value under the limit and allow its request, so the combined total overshoots. This is the same race described earlier, and the same fix applies: make the read-and-update atomic at the shared store, using a Lua script or transaction so concurrent updates serialize.
- Synchronization across nodes. Each node must enforce a single, shared limit, not its own private one. There are two ways to achieve that:
| Approach | How it works | Tradeoff |
|---|---|---|
| Sticky sessions | The load balancer pins each client to one limiter node, so that client's counter lives in just one place and no cross-node coordination is needed. | Simple and avoids a shared store on the hot path, but it is fragile: an uneven client distribution creates hot nodes, and losing a node loses or resets its clients' counters. It also breaks elastic scaling. |
| Centralized store | All nodes read and write counters in one shared store (Redis). The limiter nodes become stateless; the count is authoritative in a single place. | The usual choice. Nodes scale freely and any node can serve any client, at the cost of a network round trip to the store per request and a dependency on the store's availability. |
The centralized store is the standard answer because it keeps the limiter nodes stateless and the count consistent. The latency of the extra hop is small with an in-memory store, and the atomic-update technique handles the races that the shared counter would otherwise invite.
8. Summary
A rate limiter is a sequence of decisions, each building on the last:
| Question | Answer |
|---|---|
| Why limit at all? | To stop abuse, control cost, keep usage fair, and protect the backend from cascading overload. |
| Where does it run? | Usually as middleware or an API gateway in front of the services — enforceable, shared, and cheap to reject early. |
| Which algorithm? | Token bucket for bursts, leaking bucket for smooth output, fixed window for simplicity, sliding window log for accuracy, sliding window counter for a cheap, accurate compromise. |
| Where do counters live? | An in-memory store such as Redis, using INCR + EXPIRE for window counting, with rules cached separately and refreshed by workers. |
| How is it kept correct? | Make the read-decide-update step atomic with a Lua script so concurrent requests cannot both slip through. |
| What does the client see? | HTTP 429 plus rate-limit headers (Limit, Remaining, Retry-After) so clients can back off. |
| What about the extra requests? | Drop them on interactive paths; enqueue them on asynchronous paths where deferral is fine. |
| How do many nodes agree? | A centralized shared counter keeps nodes stateless and the limit consistent; atomic updates handle the races. |