Designing a Notification System
A system design interview guide to building a notification service that reliably fans out push notifications, SMS, and email to millions of users without losing messages, sending duplicates, or spamming anyone.
A notification system is one of those services that looks trivial from the outside ("just send a message") and turns out to be a surprisingly rich design problem once you account for scale, third-party gateways you do not control, and the hard requirement that you neither lose a message nor send it twice. The interesting work is not the sending itself but everything around it: deciding what contact information to keep, decoupling the callers from the slow external gateways, retrying without duplicating, respecting user preferences, and being able to prove afterwards whether a notification was actually delivered. This guide walks through a design that handles all of that, building up from the channels outward.
Contents
1. Channels and Gateways
The first thing to pin down is that a notification system almost never delivers messages itself. Instead it hands each message to a third-party gateway that owns the last mile to the device or inbox. There are several distinct channels, each with its own gateway, its own credentials, and its own quirks. Your design has to treat them as separate pipelines rather than assuming one uniform "send" path.
| Channel | Gateway | What it does |
|---|---|---|
| iOS push | APNs (Apple Push Notification service) | Delivers push notifications to iPhones and iPads. You authenticate to APNs and send the payload addressed to a per-device token. |
| Android push | FCM (Firebase Cloud Messaging) | Google's equivalent for Android devices (and a cross-platform option). Again addressed by a device registration token. |
| SMS | An SMS provider (e.g. a commercial messaging API) | Sends a text message to a phone number. Usually metered per message and subject to carrier rules. |
| An email provider / transactional email service | Sends email to an address, handling deliverability concerns like SPF, DKIM, and bounce tracking. |
The common thread is that all four are external, networked, and unreliable from your point of view. They can be slow, rate-limited, or temporarily down, and you cannot fix them — you can only react. That single fact drives most of the architecture that follows: you must isolate yourself from each gateway so that one misbehaving channel cannot stall the others, and you must be able to retry safely when a gateway returns an error.
2. Gathering Contact Info
Before you can send anything you need to know where to send it, and that information has to be collected and kept up to date well before the first notification fires. The natural collection points are when a user signs up and when they install the app on a new device.
For each user you want to store:
- User id — the stable internal identifier that everything else hangs off.
- Device token / device id — the per-device address that APNs or FCM requires. A single user may have several, one per device, and tokens can rotate, so this is a one-to-many relationship that needs refreshing.
- Phone number — for the SMS channel, ideally validated and stored in a normalized international format.
- Email address — for the email channel.
When the mobile app is installed and registers for push, it obtains a device token from the OS and sends it to your backend; you persist it against the user id. Sign-up captures the phone number and email. All of this lands in a database that the notification system reads at send time to resolve a user id into concrete addresses.
# on app install / push registration
function register_device(user_id, platform, device_token):
db.devices.upsert(user_id, platform, device_token, last_seen=now())
# on sign-up
function register_contact(user_id, phone, email):
db.users.upsert(user_id, normalize(phone), email)A schema sketch keeps the one-to-many device relationship explicit:
| Table | Key fields | Notes |
|---|---|---|
| users | user_id, phone, email, locale, timezone | One row per user. Locale and timezone matter later for templating and quiet hours. |
| devices | device_id, user_id, platform, token, last_seen | Many rows per user. Stale tokens get cleaned up when a gateway reports them invalid. |
3. End-to-End Architecture
With channels and contact info in place, the central design is the path a notification takes from the service that wants to send it to the device that receives it. The key move is to put a queue between the request and the actual sending, so the fast, synchronous part (accepting the request) is decoupled from the slow, unreliable part (talking to the gateway).
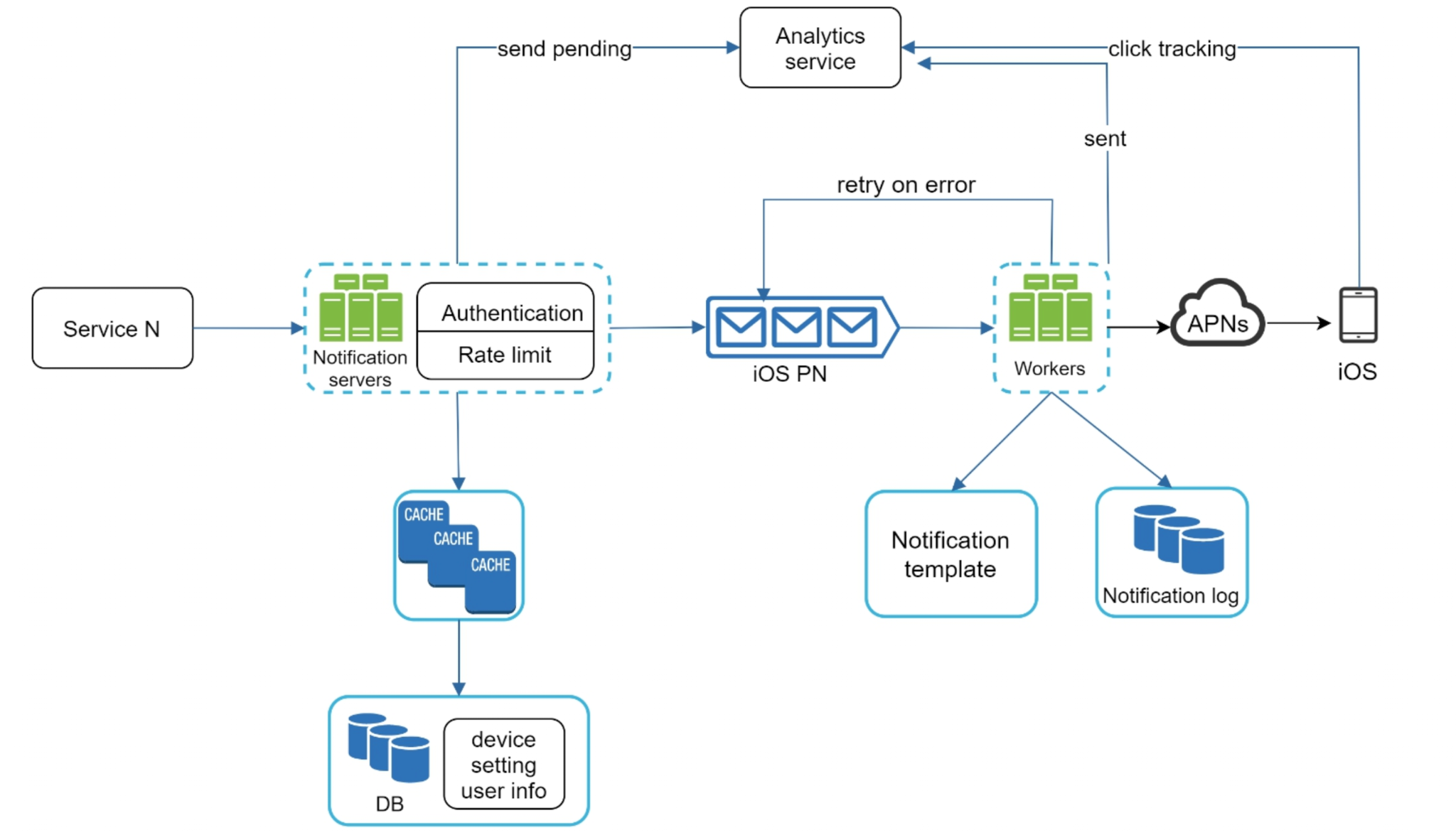
Reading the flow left to right:
- Calling service. Any internal service — a payments service, a social feature, a marketing job — triggers a notification by calling the notification system's API with a user id, a channel (or "any available"), and the content or a template reference.
- Notification servers. These are the front door. They authenticate the caller (only trusted services may send), apply rate limits, look up the recipient's device token / phone / email from the cache (backed by the DB of device settings and user info), render the content using the template store, and write the notification to the notification log. Crucially they do this quickly and then return — the real send happens asynchronously.
- Per-channel message queue. The server enqueues the prepared message onto the queue for its channel (an iOS PN queue, an Android queue, an SMS queue, an email queue). The queue is the buffer that absorbs spikes and decouples the servers from the gateways.
- Workers. A pool of workers pulls messages off each queue and makes the actual call to the third-party gateway. If the gateway returns an error, the worker retries (with backoff) rather than dropping the message.
- Gateway and device. The worker calls APNs (or FCM, or the SMS/email provider), which delivers to the user's iOS device, Android device, phone, or inbox.
- Analytics service. Throughout, an analytics service records lifecycle events — send-pending, sent, and click — so the whole flow is observable end to end.
function notify(caller, user_id, channel, template_id, params):
authenticate(caller) # reject untrusted services
if not rate_limiter.allow(user_id, channel):
return DROPPED # don't spam the user
contact = cache.get_contact(user_id) # falls back to DB
body = templates.render(template_id, params, contact.locale)
msg = build(notification_id=uuid(), user_id, channel, contact, body)
log.write(msg, status="send-pending")
queue[channel].enqueue(msg) # return fast; send is async
return ACCEPTED4. Why a Queue per Channel
It is tempting to use one big queue for everything, but giving each channel its own queue is one of the highest-leverage decisions in the design. The reasons compound:
- Isolation. If APNs is slow or down, the iOS queue backs up — but the email and SMS queues keep draining normally. One sick channel cannot poison the others, which a shared queue would allow.
- Buffering. The queue absorbs bursts. A marketing campaign that triggers a million notifications at once does not overwhelm the gateways; the messages sit in the queue and drain at a sustainable rate.
- Independent scaling. Channels have wildly different throughput and cost profiles. You can run many workers on the push queues and a smaller, carefully throttled pool on the SMS queue (where each message costs money), tuning each channel separately.
- Backpressure. Queue depth is a direct, observable signal. A growing iOS queue tells you the gateway or the worker pool is the bottleneck, and it gives you a natural place to apply backpressure rather than failing requests at the front door.
5. Reliability: No Lost Data
The defining requirement of a notification system is usually stated as two rules that pull in opposite directions: do not lose a notification, and do not send the same notification twice. Satisfying both at once is the heart of the reliability design.
Three mechanisms work together:
- Persist first. Before a notification is considered accepted, write it to durable storage (the notification log) with a status of
send-pending. If a worker crashes mid-send, the record survives and can be retried. Never treat an in-memory message as the source of truth. - Retry on error. Gateways fail transiently all the time. When a worker's call returns a retryable error, it retries with exponential backoff rather than dropping the message. Non-retryable errors (such as an invalid device token) are recorded and the stale token is cleaned up instead of being retried forever.
- Dedup with a notification id. Every notification carries a unique
notification_id. Because retries (and at-least-once queue delivery) mean a message can be processed more than once, the worker checks whether that id has already been sent before calling the gateway. This is what prevents a user from receiving the same alert twice.
function worker_process(msg):
if log.already_sent(msg.notification_id): # dedup: don't send twice
return
try:
gateway[msg.channel].send(msg)
log.mark(msg.notification_id, status="sent")
analytics.record(msg.notification_id, "sent")
except RetryableError as err:
if msg.attempts < MAX_ATTEMPTS:
queue[msg.channel].requeue(msg, backoff(msg.attempts))
else:
log.mark(msg.notification_id, status="failed") # give up loudly
except InvalidTokenError:
db.devices.remove(msg.device_id) # clean up, do not retryThe combination is what gives at-least-once delivery with effective exactly-once user experience: persistence and retries guarantee the message is not lost, and the notification-id dedup check guarantees the user does not see it twice even though the message may flow through the worker more than once.
6. Templates
Most notifications are not bespoke one-off strings; they are the same message structure filled in with different values — "Your order #{order_id} has shipped," "{name} liked your post." Embedding that text inline in every calling service is a maintenance and consistency nightmare. A notification template store solves this by keeping reusable, parameterized content in one place.
A template is a named, versioned piece of content with placeholders. Callers reference a template by id and supply the parameters; the notification servers render the final body at send time. This buys several things at once:
- Consistency. Wording, formatting, and branding live in one place and can be updated without redeploying every caller.
- Localization. A template can have per-locale variants, so the same notification renders in the user's language using the locale stored with their contact info.
- Per-channel rendering. The same logical notification can have a short SMS form and a richer email form, chosen by the channel.
# template: "order_shipped" with placeholders
templates["order_shipped"] = {
"push": "Your order {order_id} is on the way!",
"email": "Hi {name}, order {order_id} shipped and arrives {eta}.",
}
render("order_shipped", {order_id: 482, name: "Sam", eta: "Friday"}, channel="email")
# -> "Hi Sam, order 482 shipped and arrives Friday."7. Settings and Rate Limiting
Just because you can send a notification does not mean you should. Two controls protect the user from being overwhelmed, and they are also what keep your sending reputation (and SMS bill) healthy.
- User settings and opt-out. Users decide which categories of notification they want and on which channels — they may want push but not email, or order updates but not marketing. These preferences live in the settings DB and are checked before every send. A notification the user has opted out of is silently dropped rather than queued. Honoring opt-out is frequently a legal requirement, not just a courtesy.
- Rate limiting. Even for opted-in users, you cap how many notifications a given user receives in a window so a buggy or overzealous caller cannot flood them. Rate limits apply per user and often per category, so a flurry of one type does not crowd out genuinely important alerts. Hitting the limit drops or defers the excess.
function should_send(user_id, channel, category):
prefs = settings.get(user_id)
if not prefs.opted_in(channel, category):
return False # respect opt-out
if not rate_limiter.allow(user_id, category):
return False # don't spam
return True8. Observability
Because the actual delivery happens inside third parties you do not control, you cannot reason about the system without recording what happened at each step. Two pieces give you that visibility.
- Notification log. A durable record of every notification and its status transitions —
send-pending→sent→delivered, orfailed. This is both the reliability backbone (it is what makes persist-first and dedup possible) and the audit trail you consult when a user asks "why didn't I get the alert?" - Analytics service. Aggregates the lifecycle events across all notifications to answer product and operational questions: how many were sent, how many were delivered, and how many were clicked. Click and delivery rates per template and per channel tell you what is working; a sudden drop in delivery rate on one channel is an early warning of a gateway problem.
Tracking sent, delivered, and clicked as distinct events matters because the gaps between them are diagnostic. A high sent-but-not-delivered rate points at the gateway or stale tokens; a high delivered-but-not-clicked rate points at content. Without these events you are flying blind through services you cannot otherwise inspect.
analytics.record(notification_id, "send-pending") # accepted, queued
analytics.record(notification_id, "sent") # handed to gateway
analytics.record(notification_id, "delivered") # gateway receipt
analytics.record(notification_id, "clicked") # user engagement9. Summary
A notification system is a resilient dispatch layer in front of several unreliable external gateways. Its design is a handful of decisions that reinforce each other:
| Concern | Mechanism |
|---|---|
| How do messages actually reach devices? | Third-party gateways per channel: APNs (iOS push), FCM (Android push), an SMS provider, an email provider. |
| Where do we send to? | Contact info — user id, device tokens, phone, email — collected at sign-up and install, stored in a DB. |
| How do callers trigger sends? | Notification servers authenticate the caller, apply rate limits, render the template, persist, and enqueue. |
| How do we stay isolated from flaky gateways? | A message queue per channel: isolation, buffering, independent scaling, and backpressure. |
| How do we avoid losing messages? | Persist first to the notification log, then retry on error with backoff. |
| How do we avoid sending twice? | Dedup on a unique notification id before calling the gateway. |
| How do we keep content consistent? | A template store with reusable, parameterized, localizable content. |
| How do we avoid spamming users? | User settings / opt-out plus per-user, per-category rate limiting. |
| How do we know what happened? | A notification log plus an analytics service tracking sent, delivered, and clicked. |