MinIO — Internal Architecture
A developer's guide to how MinIO actually works under the hood: the S3-compatible API surface, the server/drive/erasure-set/pool layout, Reed-Solomon erasure coding, the write and read paths, healing, and how a deployment scales and replicates.
MinIO is a high-performance, S3-compatible distributed object store. It is software-defined: it runs as a single self-contained binary on commodity servers with locally attached drives, and exposes the Amazon S3 REST API. Its design borrows two big ideas: erasure coding instead of replication for durability (Reed-Solomon data and parity shards spread across many drives, so it survives multiple drive or server failures while paying far less storage overhead than 3x copies) and a stateless, fully symmetric server fleet (no metadata server, no master) where the server that receives a request coordinates the erasure operation across its peers. Understanding MinIO means understanding how those two halves fit together.
Contents
1. Design Goals and Core Ideas
Every internal decision in MinIO traces back to a small set of goals. Keeping them in mind makes the rest of the architecture predictable.
| Goal | How MinIO achieves it |
|---|---|
| S3 compatibility | Speaks the Amazon S3 REST API natively. Existing S3 SDKs, tools, and applications work unchanged against the same endpoint. |
| High throughput | A lean Go binary streams objects straight to and from drives. Erasure encode/decode is SIMD-accelerated; there is no separate metadata service in the hot path. |
| Simplicity | One static binary, no external database, no config server. A deployment is just servers + drives + an endpoint. |
| Durability without 3x cost | Reed-Solomon erasure coding survives multiple simultaneous drive/server failures while storing far less redundant data than full replication. |
| Software-defined & portable | Runs on bare metal, VMs, or Kubernetes with commodity drives. No proprietary hardware, no kernel modules. |
2. Architecture and Deployment Layout
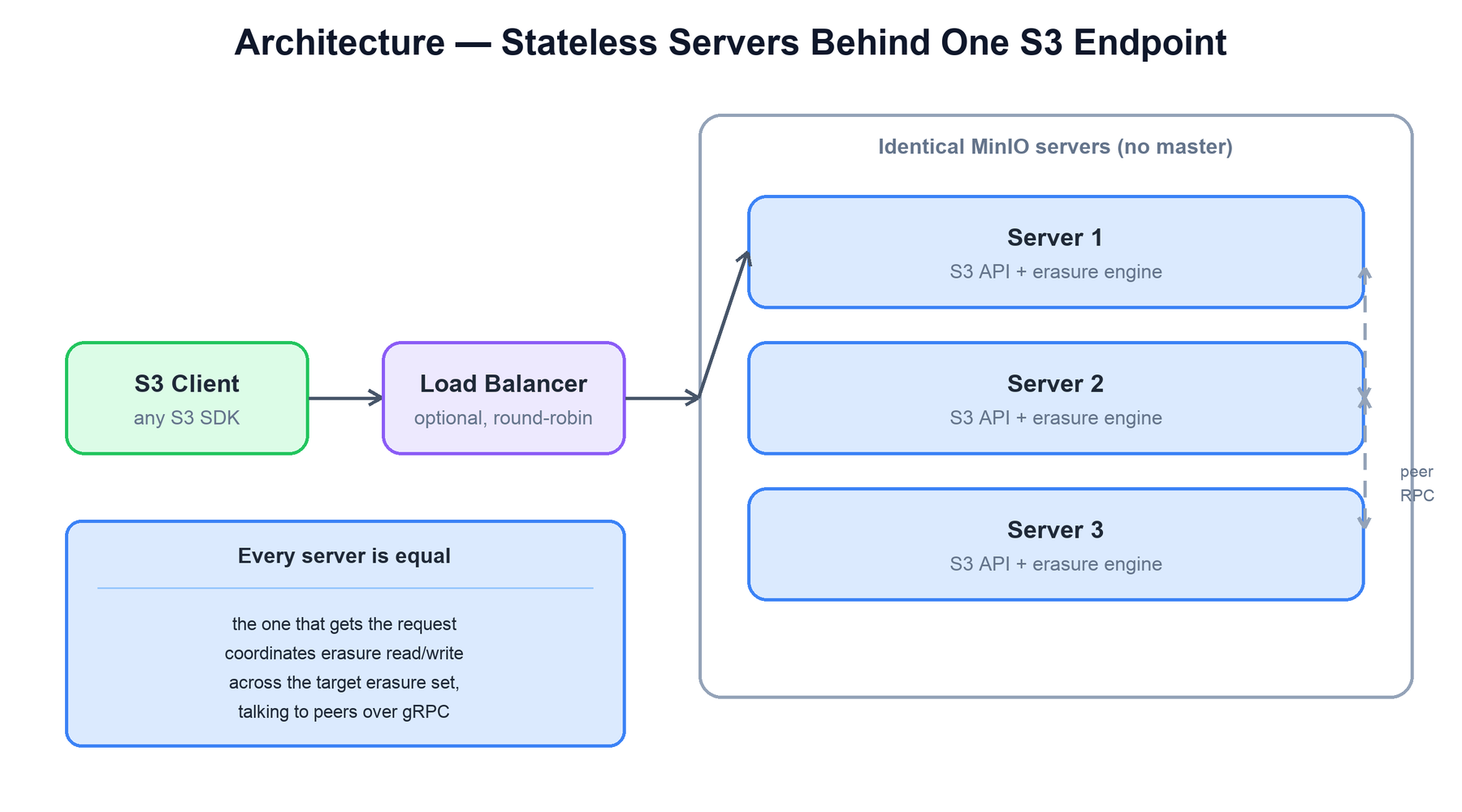
A MinIO deployment is a fleet of identical server processes. There is no master, no name node, and no metadata server. Every server speaks the full S3 API, and any server can accept any request. The server that receives a request becomes the coordinator for that single request: it runs the erasure-coding logic and reads from or writes to the relevant drives, talking to its peers over an internal gRPC channel when those drives live on other machines.
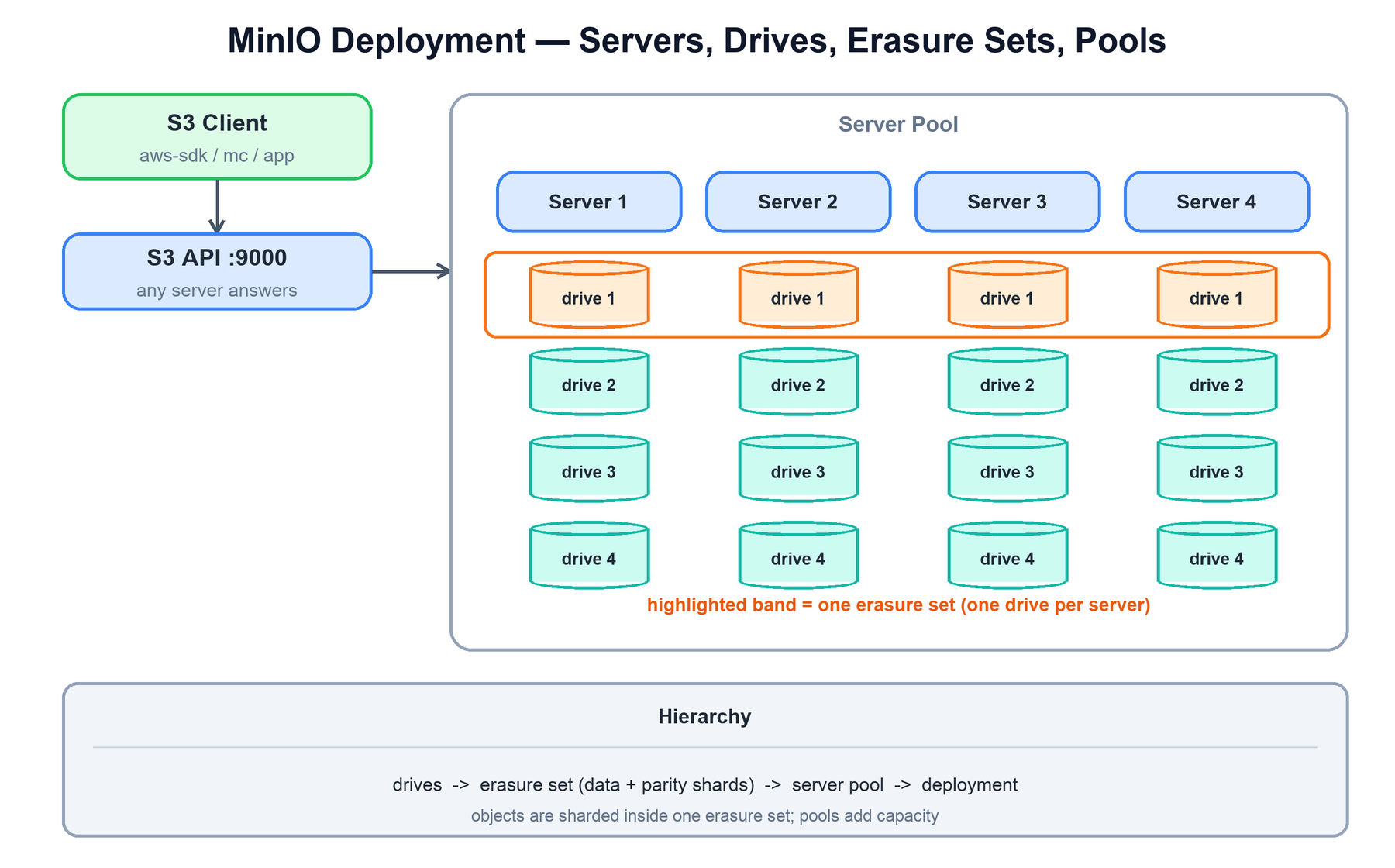
The storage hierarchy is what makes the rest of the system legible. From smallest to largest:
- Drive: a single physical disk on one server. The smallest unit of storage.
- Erasure set: a fixed group of drives (commonly 4 to 16) over which one object is sharded. MinIO automatically forms erasure sets at startup by striping drives across servers, so a set spans many machines and survives whole-server loss. An object lives entirely within one erasure set.
- Server pool: a group of servers (and their drives) deployed together. A pool contains one or more erasure sets. New writes are balanced across pools by free space.
- Deployment: one or more server pools behind a single S3 endpoint.
Because the fleet is symmetric, there is no leader election for data ownership and no single component to lose. The object's location is computed deterministically — a hash of bucket/object selects the pool and erasure set — so any server can locate any object without consulting a central directory.
3. Erasure Coding
Instead of keeping N full copies of each object, MinIO splits an object into data shards and computes additional parity shards using Reed-Solomon coding. With N drives in an erasure set and M parity shards (written as EC:M), the object survives the loss of any M shards, because the original data can be reconstructed from any N−M surviving shards. Storage overhead is M/N rather than the 200% of three-way replication.
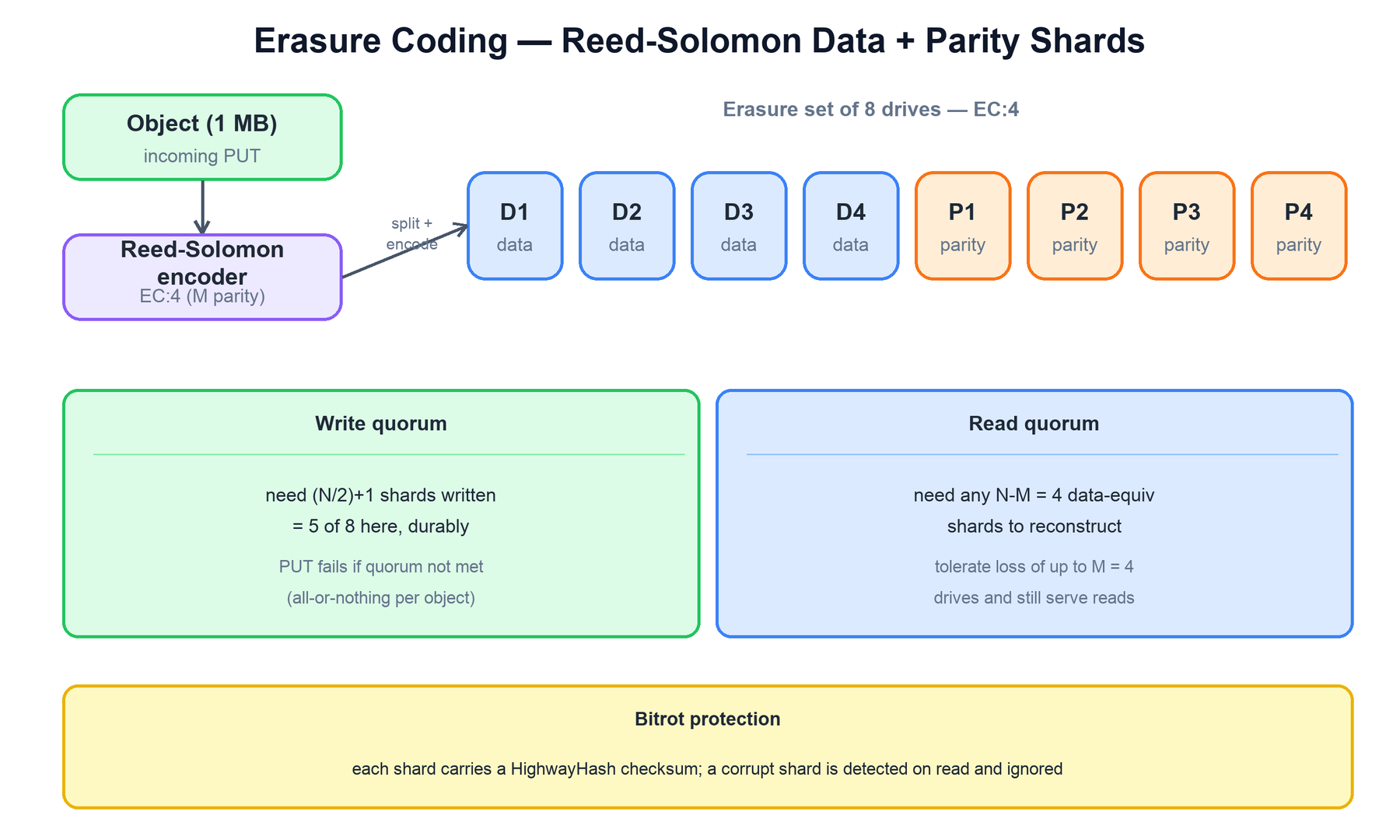
Two quorums govern correctness:
- Write quorum: a PUT succeeds only when at least
(N/2)+1shards are written durably. If fewer drives are available, the write is rejected rather than left half-committed. This guarantees that any future read can find enough shards. - Read quorum: a GET succeeds as long as at least
N−Mshards (enough to reconstruct the data) are readable. The set tolerates losing up to M drives and still serves reads.
Each shard also carries a HighwayHash checksum. On read, MinIO verifies the checksum of every shard it touches; a shard whose hash does not match is treated as missing (silent corruption, or "bitrot"), and the object is reconstructed from the remaining good shards. This is how MinIO catches corruption that the drive itself does not report.
EC:4 is common (4 parity, tolerate 4 losses); the standard parity can be raised per deployment or even per object via a storage class.4. Object Layout and xl.meta
When an object is stored, MinIO does not write one file. It writes one shard part plus one metadata file on each drive of the erasure set. The shards together reconstruct the object; the metadata file describes how.
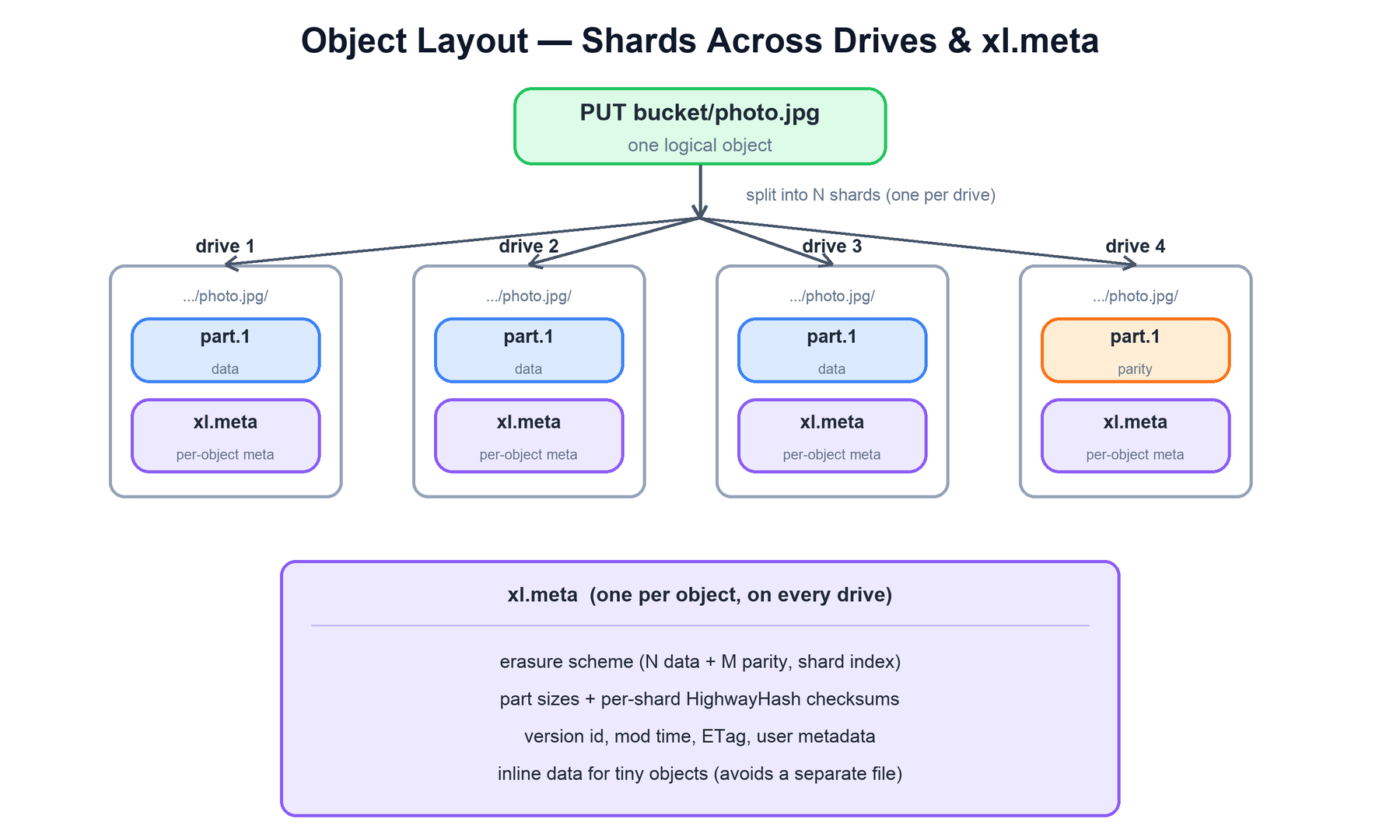
xl.meta. The metadata records the erasure scheme and per-shard checksums.On each drive, the object occupies a directory named after its key, holding:
part.1,part.2, ...: the actual shard data for this drive (one part per object part for multipart uploads).xl.meta: a small, self-describing metadata file (MessagePack-encoded) present on every drive of the set. It records the erasure scheme (N data + M parity and this drive's shard index), part sizes, per-shard HighwayHash checksums, the version id, modification time, ETag, and user metadata.
Keeping a copy of xl.meta on every drive means the metadata is itself protected by the same quorum as the data — there is no separate, single-point metadata store to lose. Very small objects are written inline inside xl.meta to avoid a second file open. Object versions are recorded as multiple entries inside the same xl.meta, each with its own version id and checksums.
5. Write Path (PUT)
A write streams the object through the coordinating server, which erasure-encodes it and scatters the resulting shards across the drives of the target erasure set. The PUT is acknowledged only once the write quorum of drives has confirmed their shards are durable.
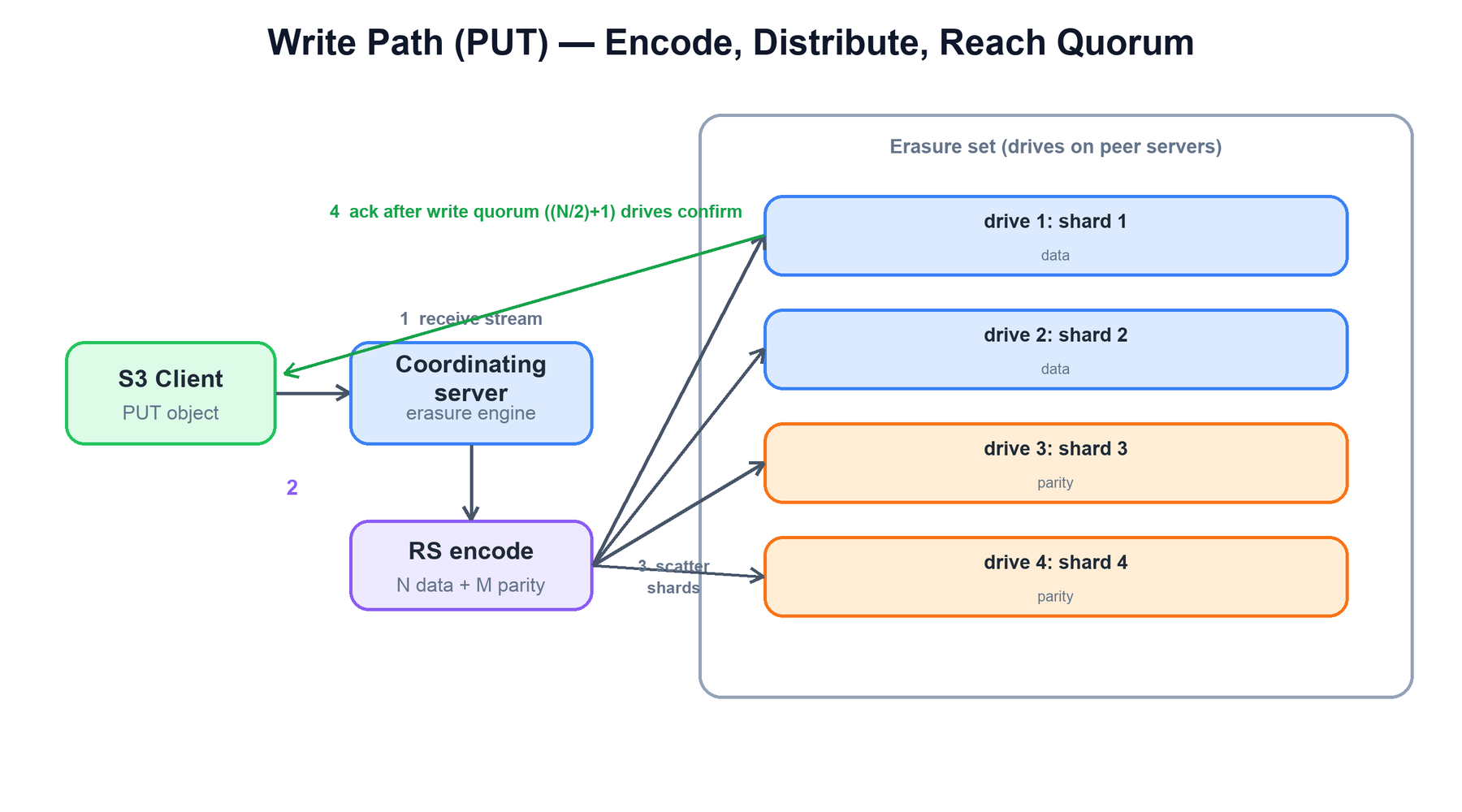
The coordinating server's write logic:
function put(bucket, object, stream):
set = locate_erasure_set(hash(bucket + "/" + object)) # deterministic
N = len(set.drives); M = set.parity # e.g. N=8, M=4
written = 0
for block in stream.chunks(): # stream, don't buffer whole object
shards = reed_solomon_encode(block, N - M, M) # N-M data + M parity
for i, drive in enumerate(set.drives):
if drive.is_online():
shards[i].checksum = highwayhash(shards[i])
drive.append(object, "part.N", shards[i]) # one shard per drive
for drive in set.drives:
if drive.is_online():
drive.write_xl_meta(object, scheme=(N-M, M), checksums)
written += 1
if written < (N // 2) + 1: # write quorum
rollback_partial_write(set, object)
raise QuorumError # all-or-nothing per object
return OK # ETag + version idThere is no read-before-write and no separate metadata transaction: the object data and its xl.meta are written together to each drive. Concurrent writers to the same object are serialized by a distributed lock (see §8) so two PUTs cannot interleave shards.
6. Read Path (GET)
A read is the inverse of a write. The coordinating server reads the shards it needs from the drives of the erasure set, verifies their checksums, and reconstructs the object. It only needs N−M shards, so it can serve the object even when some drives are offline or corrupt.
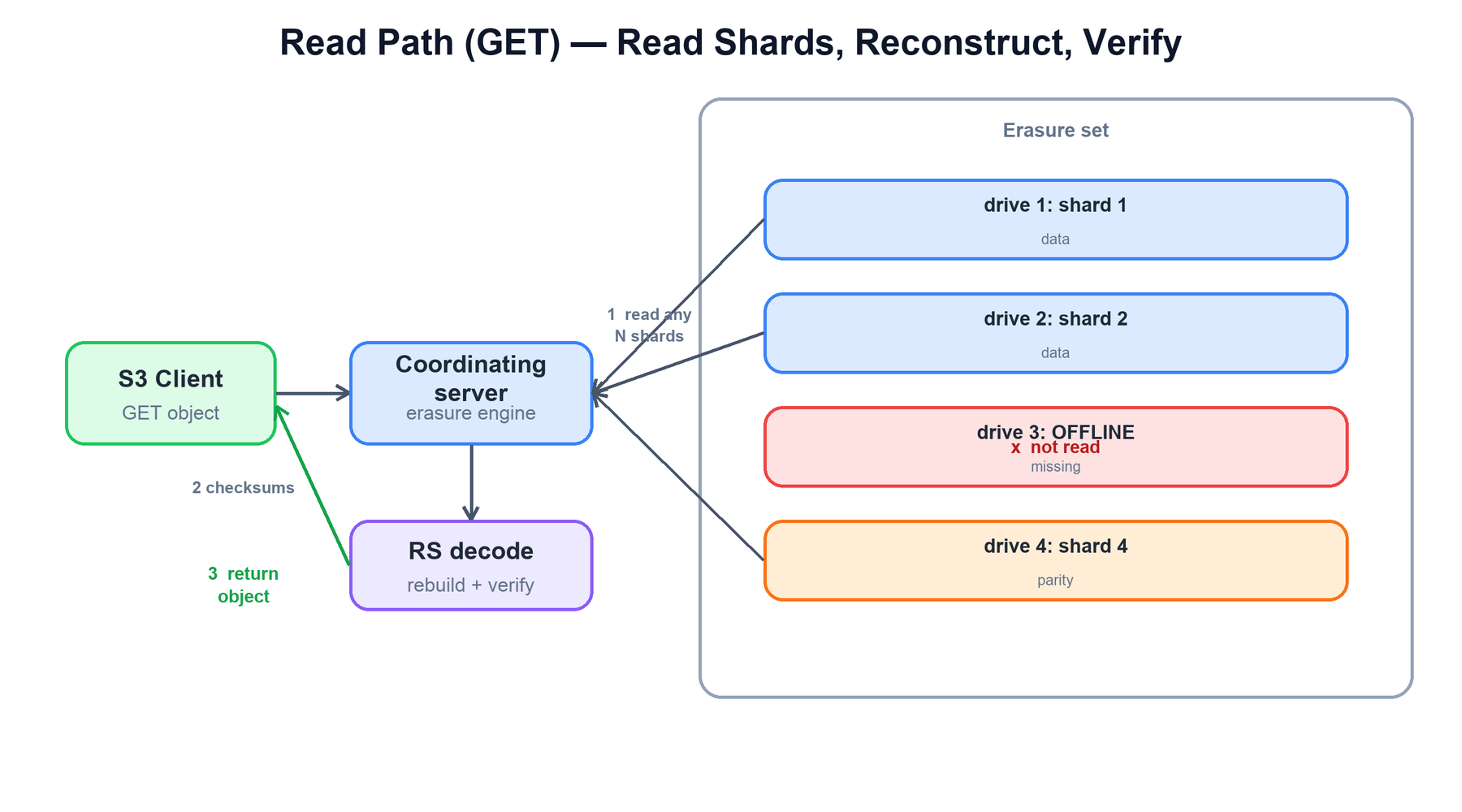
The local read logic:
function get(bucket, object):
set = locate_erasure_set(hash(bucket + "/" + object))
meta = read_quorum_xl_meta(set, object) # newest version, from a quorum
N, M = meta.scheme
shards = []
for drive in set.drives:
if not drive.is_online(): continue
s = drive.read(object, "part.N")
if highwayhash(s) != meta.checksum[drive]: # bitrot detection
continue # treat corrupt shard as missing
shards.append(s)
if len(shards) >= N - M: # read quorum: enough to decode
break
if len(shards) < N - M:
raise QuorumError # too many drives lost
return reed_solomon_decode(shards, N - M, M) # reconstruct missing shardsReed-Solomon decoding regenerates any missing data shards from the surviving data and parity shards, so a GET succeeds transparently even with drives down. If MinIO notices a missing or corrupt shard during a read, it can also trigger an inline heal to rewrite the bad shard (see next section).
7. Healing
Drives fail, bits rot, and servers come and go. Healing is the process that restores the full set of shards for an object by reconstructing the missing or corrupt ones from the survivors. It is the erasure-coding analogue of repair in a replicated system.
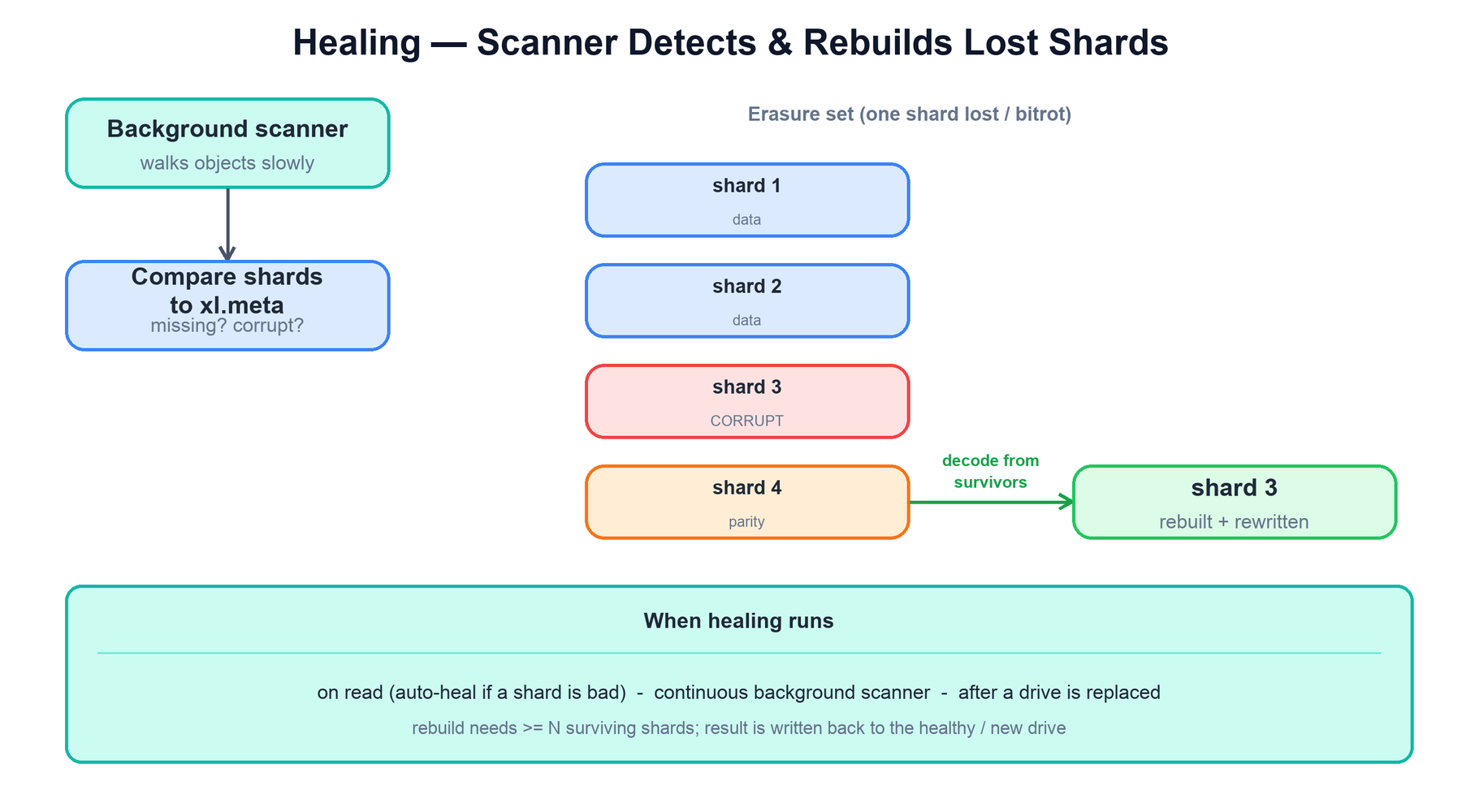
xl.meta; a missing or corrupt shard is rebuilt by decoding from the surviving shards and rewritten.Healing is detected and driven three ways:
| Trigger | When it runs | What it does |
|---|---|---|
| Read auto-heal | During a GET | If a shard fails its checksum or is missing, MinIO reconstructs it from survivors and rewrites it to a healthy drive in the background. |
| Scanner | Continuous, low priority | A background scanner slowly walks every object, compares actual shards to what xl.meta says should exist, and queues anything missing or corrupt for heal. |
| Drive replacement | After a failed drive is swapped | The fresh, empty drive is healed: every object that should have a shard there has it reconstructed and written. |
Reconstruction always uses the same Reed-Solomon decode as a read: as long as at least N−M shards survive, the missing shard's data can be regenerated and re-encoded. The healed shard is written back with a freshly computed checksum, and xl.meta is updated to mark the object whole again.
function heal(set, object):
meta = read_quorum_xl_meta(set, object)
N, M = meta.scheme
good = [drive.read(object) for drive in set.drives
if drive.is_online() and highwayhash(...) == meta.checksum[drive]]
if len(good) < N - M:
log_unrecoverable(object); return # lost too many shards
full = reed_solomon_reconstruct(good, N - M, M) # regenerate every shard
for drive in set.drives:
if drive_shard_missing_or_bad(drive, object):
drive.write(object, full[drive.index]) # rewrite + checksum
drive.update_xl_meta(object)8. Scaling and Replication
MinIO scales capacity by adding server pools rather than rebalancing existing data. You launch a new pool of servers and drives and add it to the deployment; MinIO forms new erasure sets within it and starts directing new writes there, balanced across pools by free space. Existing objects stay where they are, so expansion does not trigger a massive reshuffle.
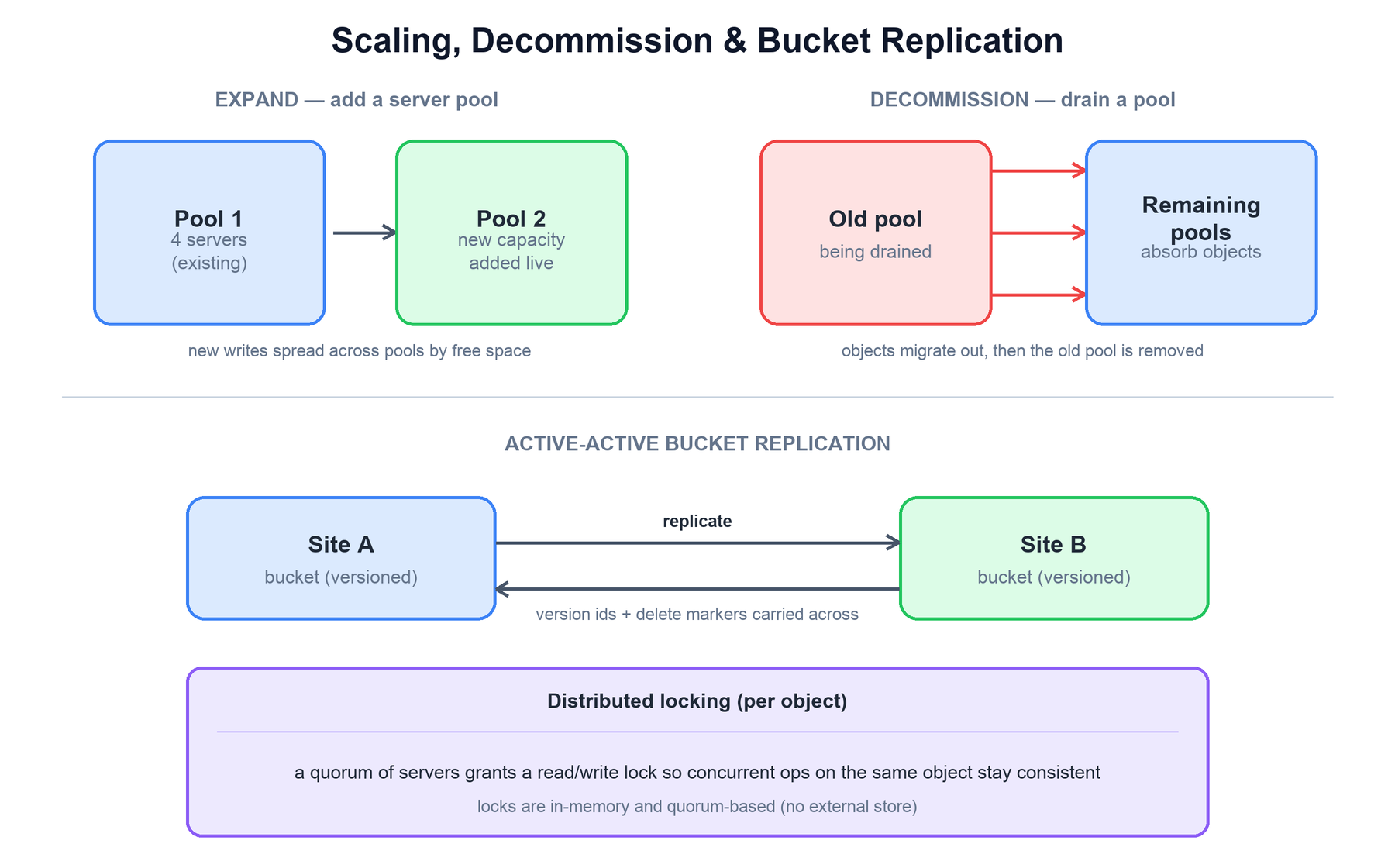
To retire old hardware, you decommission a pool. MinIO drains it by migrating its objects out to the remaining pools, then the empty pool is removed. This is how an old generation of servers is replaced without downtime.
Across sites, MinIO offers bucket replication. With versioning enabled on a bucket, MinIO can replicate objects (including their version ids and delete markers) to one or more remote MinIO deployments. Replication can be one-way or active-active, where two sites replicate to each other so either can take writes — useful for multi-region availability and disaster recovery.
| Operation | What happens |
|---|---|
| Add pool (scale out) | A new server pool joins the deployment. New erasure sets are formed; new writes spread across pools by free space. Existing data is untouched. |
| Decommission (scale in) | An old pool is drained: its objects migrate to the remaining pools, then the pool is removed. No data loss, no downtime. |
| Bucket replication | Versioned buckets replicate objects, version ids, and delete markers to remote sites. Supports one-way and active-active topologies. |
To keep concurrent operations consistent, MinIO uses distributed locking. Before mutating an object (or reading one that must be consistent), the coordinating server acquires a read or write lock that is granted by a quorum of servers. The locks are held in memory and are quorum-based — there is no external lock service — so two clients writing the same object cannot interleave their shards, and a reader never observes a half-written object.
function locked_put(bucket, object, stream):
lock = acquire_write_lock(object) # needs ack from a quorum of servers
if not lock.granted:
raise Busy # another writer holds it
try:
put(bucket, object, stream) # §5 write path
finally:
lock.release() # quorum releases the lock9. Summary
The whole system is built from a few reinforcing ideas:
| Concern | Mechanism |
|---|---|
| How do clients talk to it? | Native S3 REST API on every server; any server answers, no master. |
| Where does an object live? | Deterministic hash of bucket/object picks a pool and one erasure set; the object is sharded across that set's drives. |
| How is it kept durable? | Reed-Solomon data + parity shards (EC:M); survives M drive/server losses at far less than 3x cost. |
| How is metadata stored? | xl.meta on every drive of the set — scheme, checksums, versions — so metadata shares the data's quorum. |
| How are writes consistent? | Write quorum (N/2)+1; all-or-nothing per object; serialized by a quorum-based distributed lock. |
| How does it survive failures? | Read needs only N−M shards; healing rebuilds missing/corrupt shards from survivors; HighwayHash catches bitrot. |
| How does it scale & replicate? | Add pools to grow, decommission to drain; active-active bucket replication with versioning across sites. |