Apache Lucene — Internal Architecture
A developer's guide to how Lucene actually works under the hood: the inverted index, immutable segments, the analyzer pipeline, the indexing and search paths, BM25 scoring, deletes and merging, near-real-time reopen, and the on-disk codec files that engines like Elasticsearch and Solr are built on.
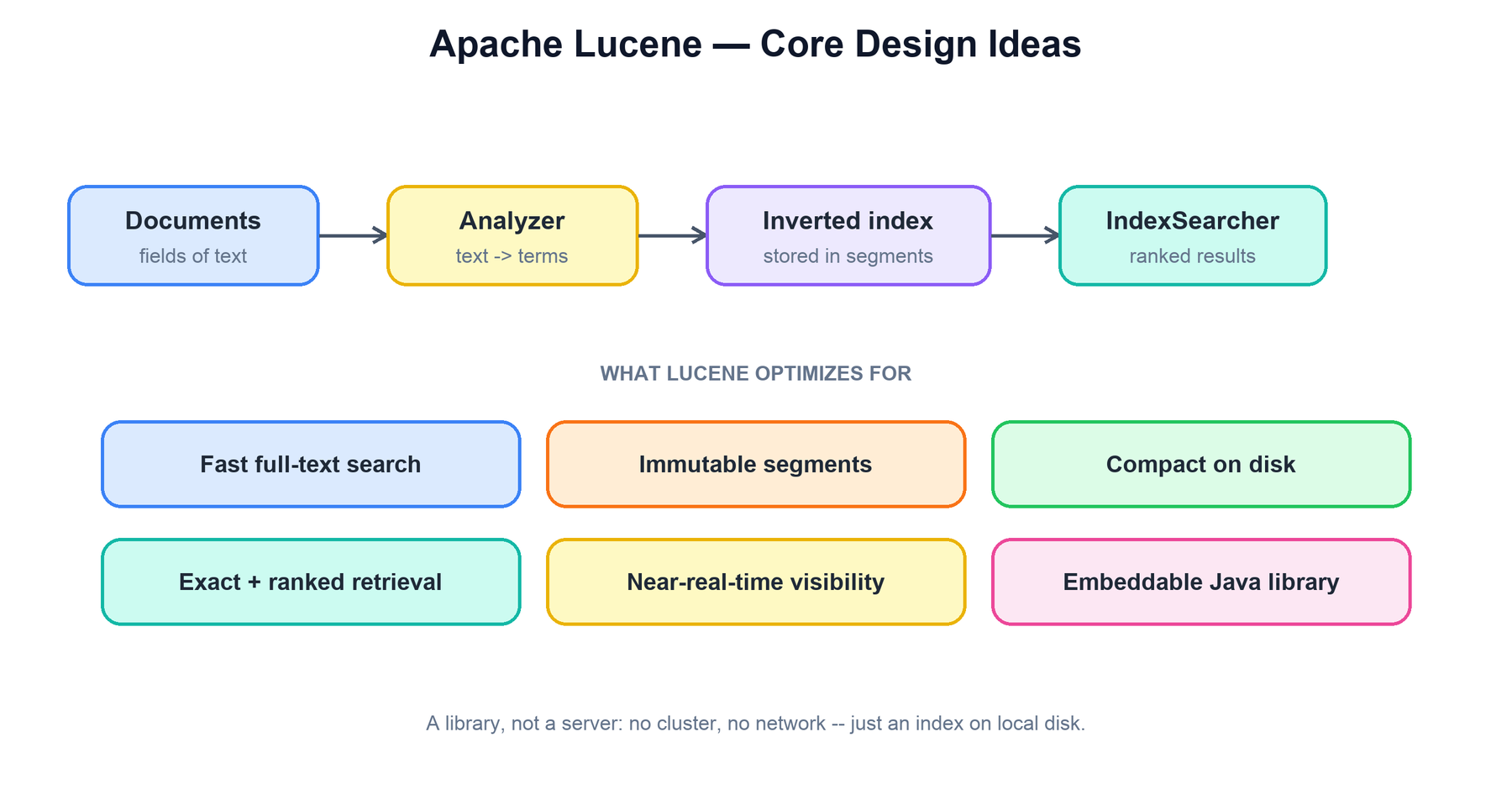
Apache Lucene is a single-machine, embeddable full-text search library written in Java. It is not a server: it has no cluster, no network layer, and no query language of its own — just an API for building an inverted index on local disk and answering ranked queries against it fast. Engines like Elasticsearch and Solr are the distributed half; Lucene is the search engine inside each shard. Almost everything about Lucene follows from two decisions: the core data structure is an inverted index, and that index is stored as a set of immutable segments. Once you understand those two ideas, the indexing path, deletes, merging, and near-real-time search all fall out as consequences.
Contents
1. Design Goals and Core Ideas
Every internal choice in Lucene serves fast, ranked retrieval over large text collections from a single process. Keeping the goals in mind makes the rest of the design predictable.
| Goal | How Lucene achieves it |
|---|---|
| Fast full-text search | An inverted index maps each term directly to the documents that contain it, so a query reads only the postings for its terms — never the whole collection. |
| Write-once, read-many storage | Index data lives in immutable segments. Nothing already written is ever modified in place, which makes reads lock-free and files trivially cacheable. |
| Compact on disk | Terms are stored once in a shared dictionary backed by an FST; postings and doc IDs are delta-encoded and compressed. The index is typically a fraction of the original text size. |
| Exact and ranked retrieval | Boolean queries find the matching set exactly; a similarity model (BM25 by default) scores and ranks those matches by relevance. |
| Near-real-time visibility | New documents become searchable by opening a reader over freshly flushed segments — without a full, durable commit. |
| Embeddable | It is a library you call in-process, not a service you connect to. The distributed concerns (sharding, replication) are left to whoever embeds it. |
2. The Index Model: Documents & Fields
The unit you add to Lucene is a document: an ordered list of fields, where each field has a name, a value, and a type that decides what Lucene does with it. Lucene has no fixed schema — two documents in the same index can carry different fields — but each field's type controls which on-disk structures it populates.
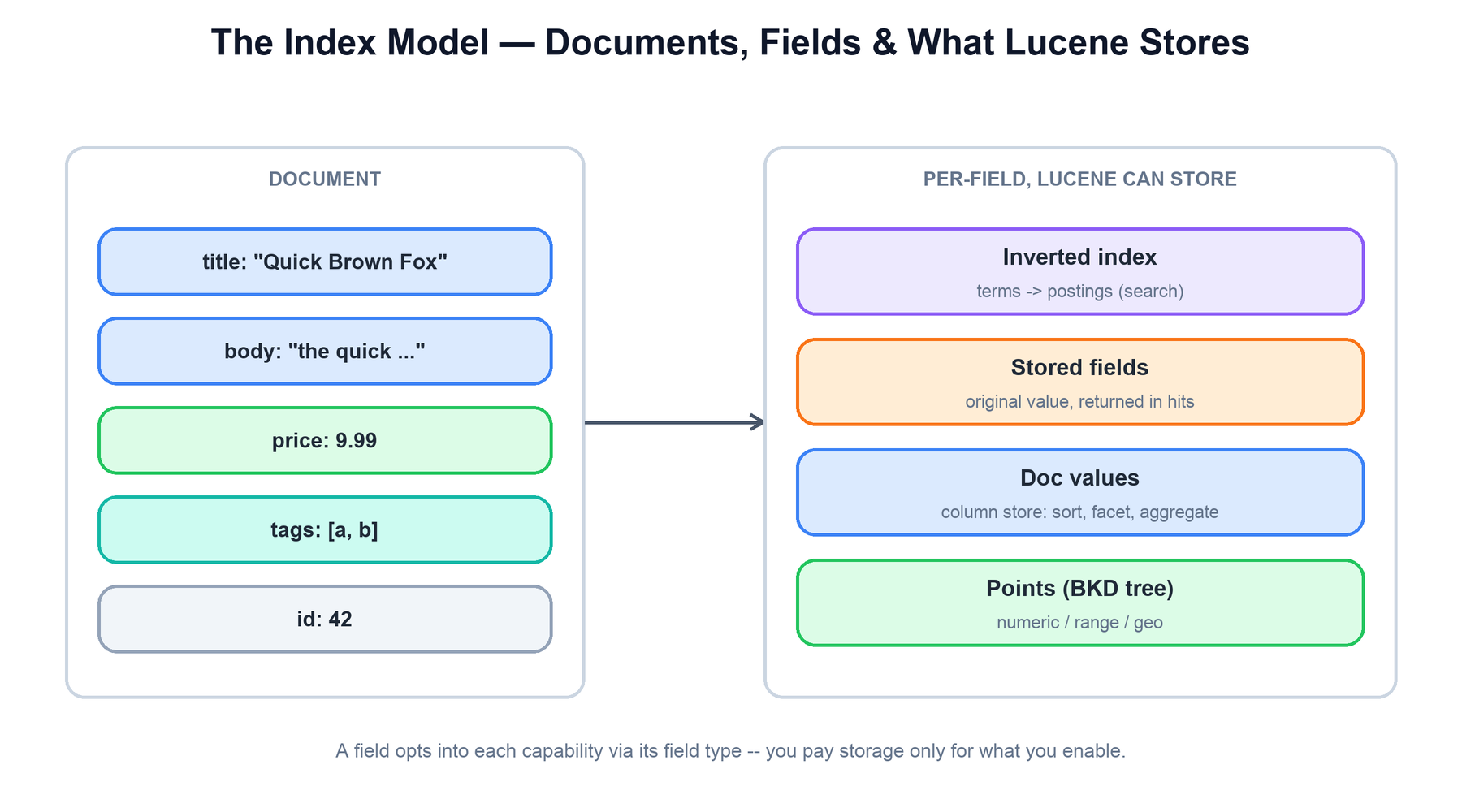
A single field can contribute to up to four different structures, each answering a different kind of question:
- Indexed (inverted) — the field's text is analyzed into terms and added to the inverted index. This is what makes it searchable.
- Stored — the original field value is kept verbatim so it can be returned in a search hit. Storage is for display, not search; stored values are never consulted to match a query.
- Doc values — a per-field column store (document → value) used for sorting, faceting, and aggregations, where you need the value for many documents rather than the documents for a value.
- Points — numeric, date, and geo fields are indexed in a BKD tree (a disk-friendly k-d tree) for efficient range and nearest-neighbor lookups, which an inverted index handles poorly.
The same logical field, say price, is often configured for several of these at once — a point for range filters, a doc value for sorting, and stored for display — because each backs a different access pattern.
3. Analysis: Text to Terms
Text is not indexed as-is. Before it reaches the inverted index it passes through an analyzer, a pipeline that turns a raw string into a stream of normalized terms. The analyzer has three stages.
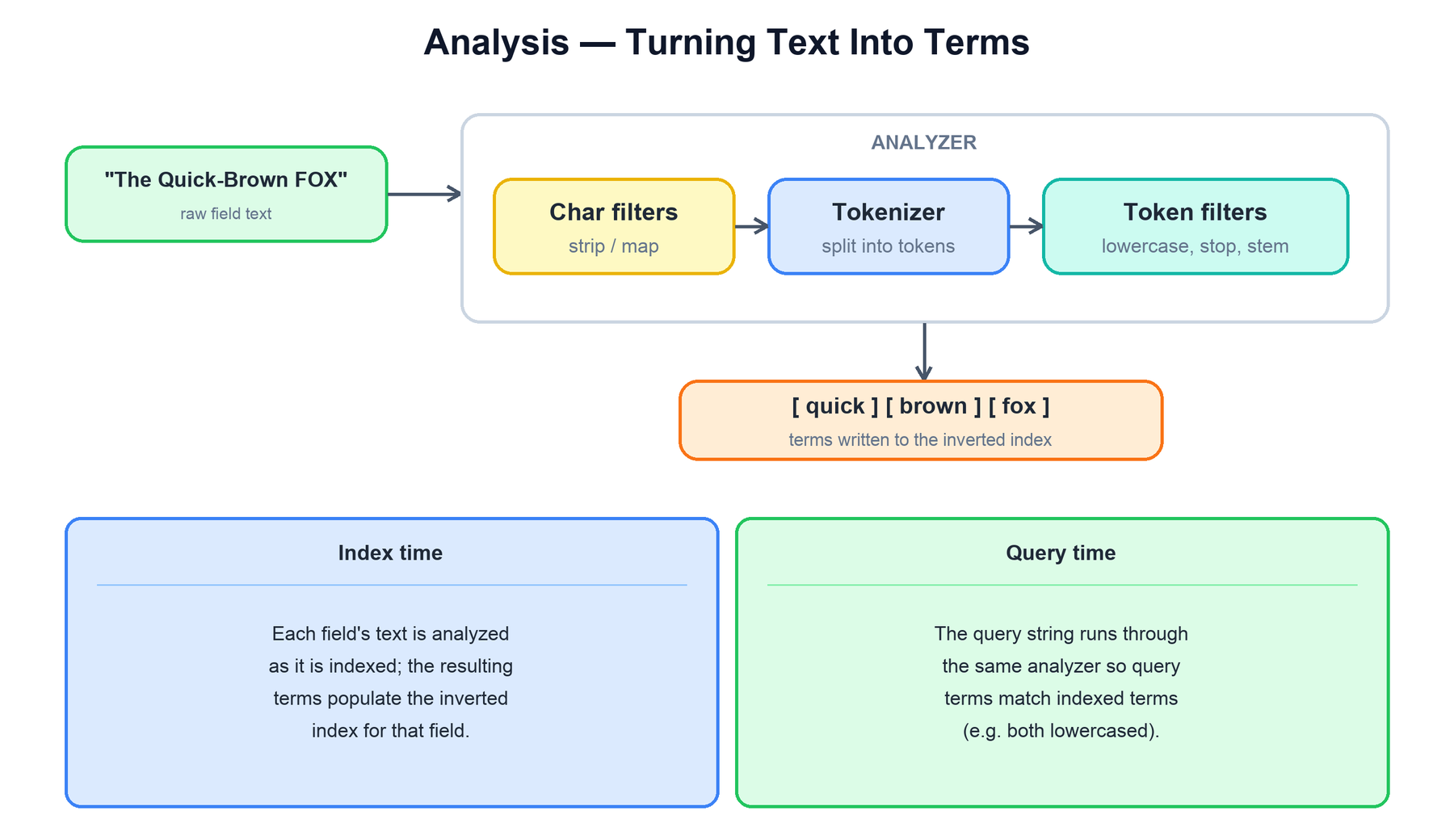
- Character filters preprocess the raw character stream — for example stripping HTML tags or mapping characters.
- The tokenizer splits the stream into tokens, typically on whitespace and punctuation. Each token also carries a position and an offset back into the original text.
- Token filters transform the token stream: lowercasing, removing stop words, folding accents, and stemming words to a root form (
running→run).
function analyze(text, analyzer):
text = analyzer.char_filters.apply(text) # e.g. strip HTML
tokens = analyzer.tokenizer.split(text) # "Quick-Brown" -> Quick, Brown
for f in analyzer.token_filters:
tokens = f.apply(tokens) # lowercase, stop, stem
return tokens # -> [quick, brown, fox]"FOX" is indexed as the term fox, then a search for "Fox" must be analyzed to fox too, or it would never match. Mismatched index- and query-time analysis is the single most common cause of "why doesn't my search find anything?".4. The Inverted Index
The inverted index is the heart of Lucene. Instead of mapping documents to the terms they contain (a "forward" index), it maps each term to the list of documents that contain it — its postings list. Answering a query then means reading a few short postings lists rather than scanning every document.
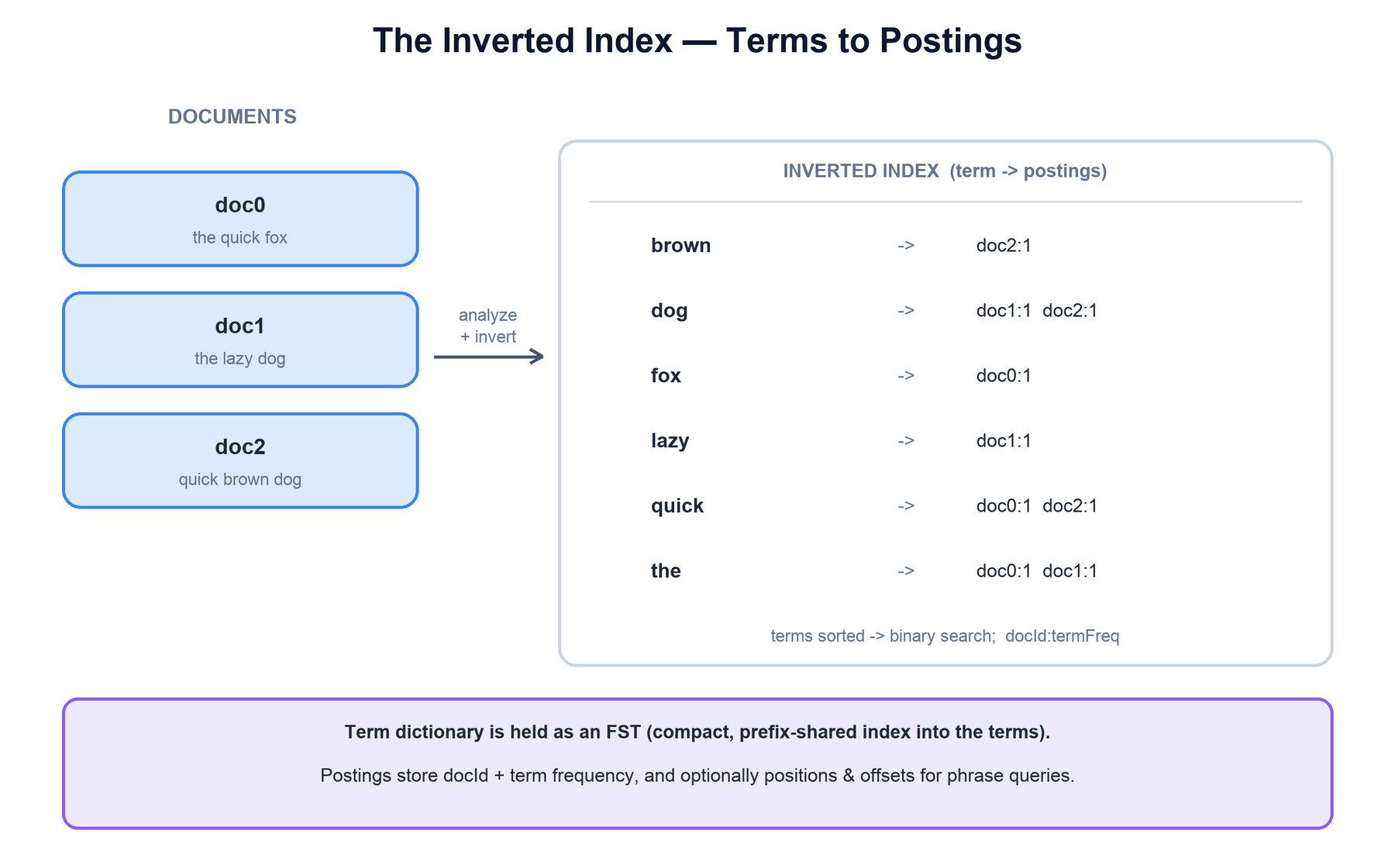
The index has two parts. The term dictionary is the sorted set of all terms in a field; Lucene holds an in-memory index into it as a finite state transducer (FST), a compact, prefix-sharing structure that maps a term to the on-disk location of its postings. The postings themselves store, for each term, the documents that contain it — and optionally the term frequency, positions, and offsets used for ranking and phrase queries.
Because the term dictionary is sorted and postings are stored as ascending document IDs, Boolean queries become efficient list operations. An AND of two terms is a merge-intersection that skips through the shorter list:
function intersect(postingsA, postingsB): # docs containing BOTH terms
result = []
a = postingsA.first(); b = postingsB.first()
while a != END and b != END:
if a.doc == b.doc:
result.add(a.doc); a = postingsA.next(); b = postingsB.next()
elif a.doc < b.doc:
a = postingsA.advance(b.doc) # skip-list jump, not linear scan
else:
b = postingsB.advance(a.doc)
return resultPostings carry skip lists, so advance(target) can jump ahead instead of stepping one document at a time — which is what keeps multi-term queries fast even on long lists.
5. Segments & Commits
A Lucene index is not one big file. It is a directory containing a set of segments, each a small, complete, self-contained inverted index over a subset of the documents. Crucially, a segment is immutable: once written, its files never change.

segments_N) that names the ones currently live.Immutability is the design decision that everything else rests on:
- New documents never modify an existing segment; they accumulate in memory and are written out as a new segment.
- Deletes cannot edit a segment either, so they are recorded separately as a bitset of "live" documents (the
.livfile) layered over the immutable data. - Reads need no locks. Because segment files never change, any number of readers can mmap and cache them freely, and the OS page cache is never invalidated.
What ties the segments together is the commit point: a small file named segments_N that lists exactly which segments are currently part of the index. A commit fsyncs the new segment files and then atomically writes a new segments_N+1. Until that file is written, a crash simply leaves the index at the previous commit — durability is the atomic swap of one tiny file.
6. The Indexing Path
The class that writes to an index is the IndexWriter. Only one may have a given index open for writing at a time (enforced by a write lock). Adding documents flows through an in-memory buffer and out to a new segment.
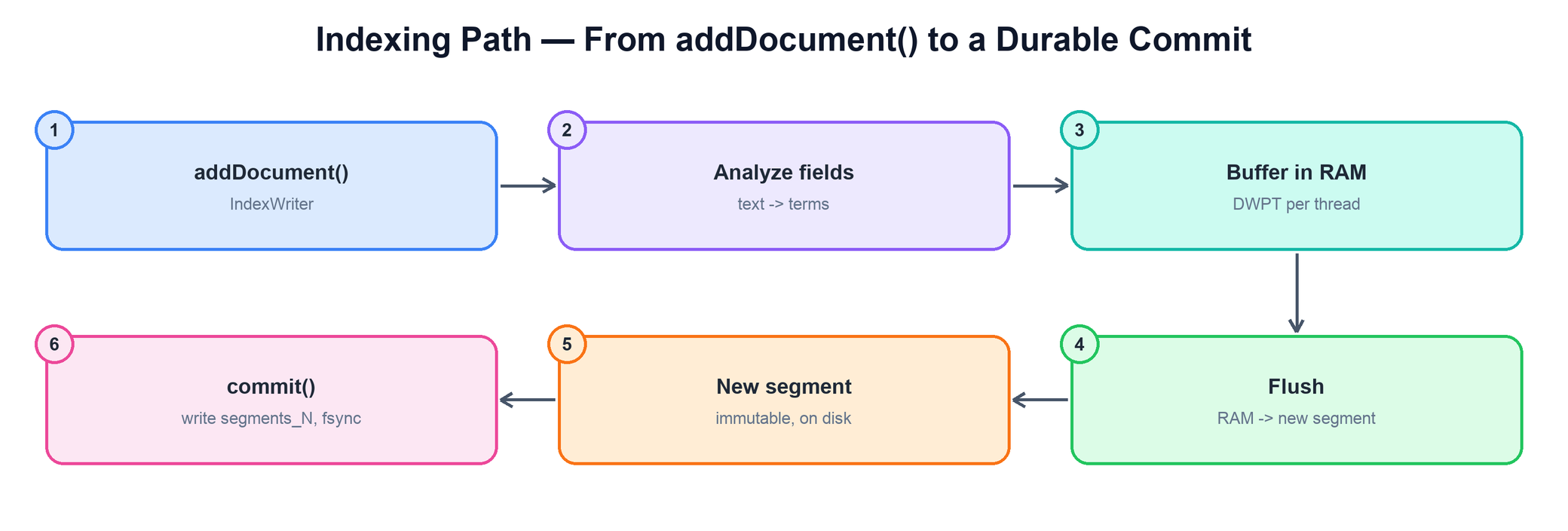
Step by step:
- Buffer. Each indexing thread fills its own DocumentsWriterPerThread (DWPT) — an in-memory mini-index. Per-thread buffers avoid contention so many threads can index in parallel.
- Flush. When a buffer fills (by RAM budget or document count), it is flushed: its in-memory inverted index is serialized to disk as a brand-new segment. After a flush the segment exists, but a crash could still lose it.
- Commit. A commit fsyncs the flushed segments and writes a new
segments_N, making everything since the last commit durable.
writer = IndexWriter(directory, config)
for doc in source:
writer.addDocument(analyze(doc)) # into this thread's DWPT (RAM)
if dwpt.ram_used > flush_threshold:
segment = dwpt.flush_to_disk() # new immutable segment, not yet durable
writer.commit() # fsync + write segments_N (durable)
writer.close()7. The Search Path
Reading is done through a DirectoryReader, which opens one leaf reader per segment, wrapped by an IndexSearcher. A query is not executed directly; it is compiled into objects that know how to iterate postings and produce scores.
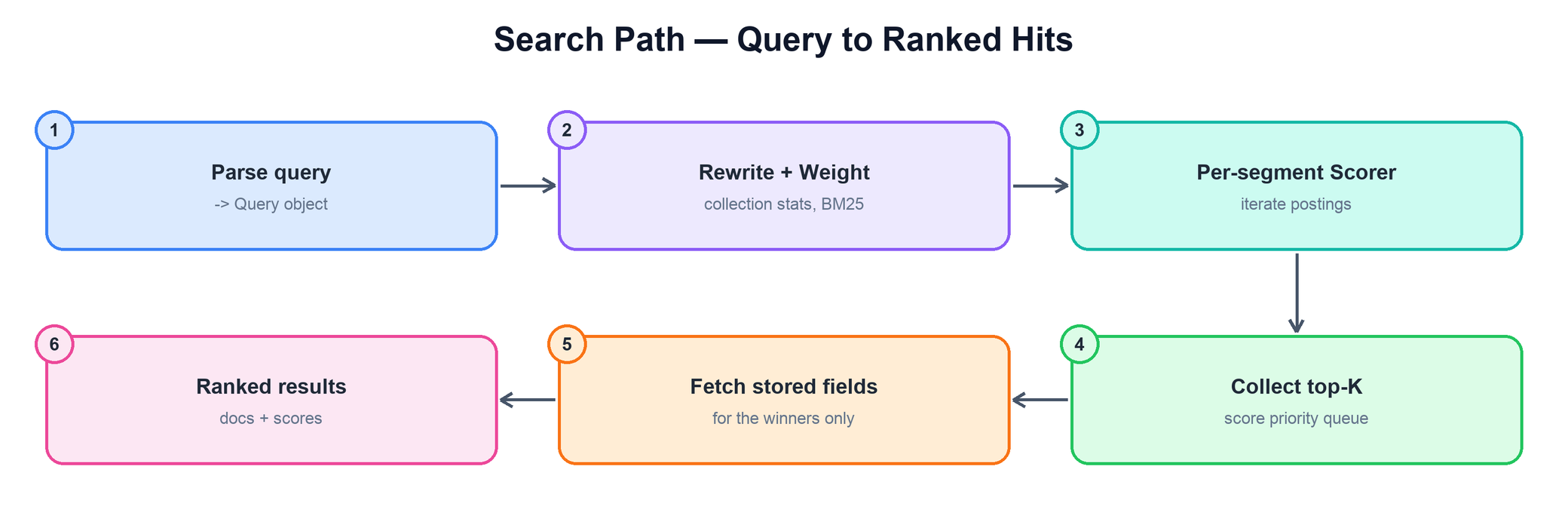
The pipeline is:
- Query → Weight. The
Queryis rewritten (e.g. a wildcard expands to the terms it matches) and turned into aWeightthat captures collection-level statistics for scoring. - Weight → Scorer, per segment. For each segment the Weight produces a
Scorerthat walks the relevant postings, yielding matching document IDs and their scores. Segments are searched independently — and can be searched concurrently. - Collect. A
Collector(typically a bounded min-heap / priority queue) keeps only the top-K highest-scoring hits, so the engine never sorts the full match set. - Fetch. Only for the K winners does Lucene read stored fields to hydrate the result. The expensive disk reads happen for a handful of documents, not the whole match set.
searcher = IndexSearcher(DirectoryReader.open(directory))
weight = searcher.createWeight(query) # stats for scoring
topk = PriorityQueue(maxsize = K) # keep best K by score
for leaf in searcher.leaves(): # one per segment
scorer = weight.scorer(leaf)
for doc in scorer: # skip-list iteration over postings
if leaf.live_docs.get(doc): # skip deleted docs
topk.insert(doc, scorer.score())
return [fetch_stored_fields(hit) for hit in topk.sorted()] # only the K winners8. Relevance Scoring (BM25)
Boolean matching decides which documents qualify; a similarity decides their order. Lucene's default is BM25, which scores a document for a query term from three intuitive signals.
| Signal | Meaning | Effect on score |
|---|---|---|
| Term frequency (tf) | How often the term appears in the document. | More occurrences raise the score, but with diminishing returns — the tenth occurrence adds far less than the second. |
| Inverse document frequency (idf) | How rare the term is across the whole index. | Rare terms are more discriminating, so they count for more; common terms count for little. |
| Field length | Length of the field, vs. the average length. | A match in a short field is worth more than the same match buried in a long one (length normalization). |
score(doc, query) = Σ over query terms t:
idf(t) · ( tf(t,doc) · (k1 + 1) )
/ ( tf(t,doc) + k1 · (1 - b + b · docLen / avgDocLen) )
idf(t) = ln( 1 + (N - n_t + 0.5) / (n_t + 0.5) ) # N = #docs, n_t = #docs with t
k1 ≈ 1.2 # tf saturation: higher = tf matters longer
b ≈ 0.75 # length normalization: 0 = ignore length, 1 = fullThe two tunables are k1 (how quickly extra term occurrences stop helping) and b (how strongly long fields are penalized). The idf values come from the collection statistics captured in the Weight, which is why scoring needs that rewrite step before iteration.
9. Deletes & Updates
Since segments are immutable, Lucene cannot physically remove a document on request. Instead a delete is recorded as a tombstone: the document's bit is cleared in the segment's live-docs bitset (.liv). The data stays on disk; searches simply skip any document whose live bit is off (the live_docs.get(doc) check in §7).
An update is therefore not an in-place edit at all. updateDocument(term, doc) is exactly a delete-by-term followed by an add: the old document is tombstoned and a new version is written into the current in-memory buffer, landing in a future segment.
function updateDocument(term, newDoc):
deleteDocuments(term) # mark old doc's bit off in .liv
addDocument(newDoc) # new version -> RAM buffer -> new segmentLucene also supports soft deletes, where the tombstone is a doc-values marker rather than a hard removal, so the old version can be retained (for example to support point-in-time or change-tracking use cases) until a retention policy lets it be merged away.
10. Segment Merging
Flushing constantly produces new, small segments, and deletes leave dead documents behind. Left alone, an index would drift toward thousands of tiny segments — and every query has to visit every segment. Merging is the background process that keeps this in check by combining several segments into one larger segment.
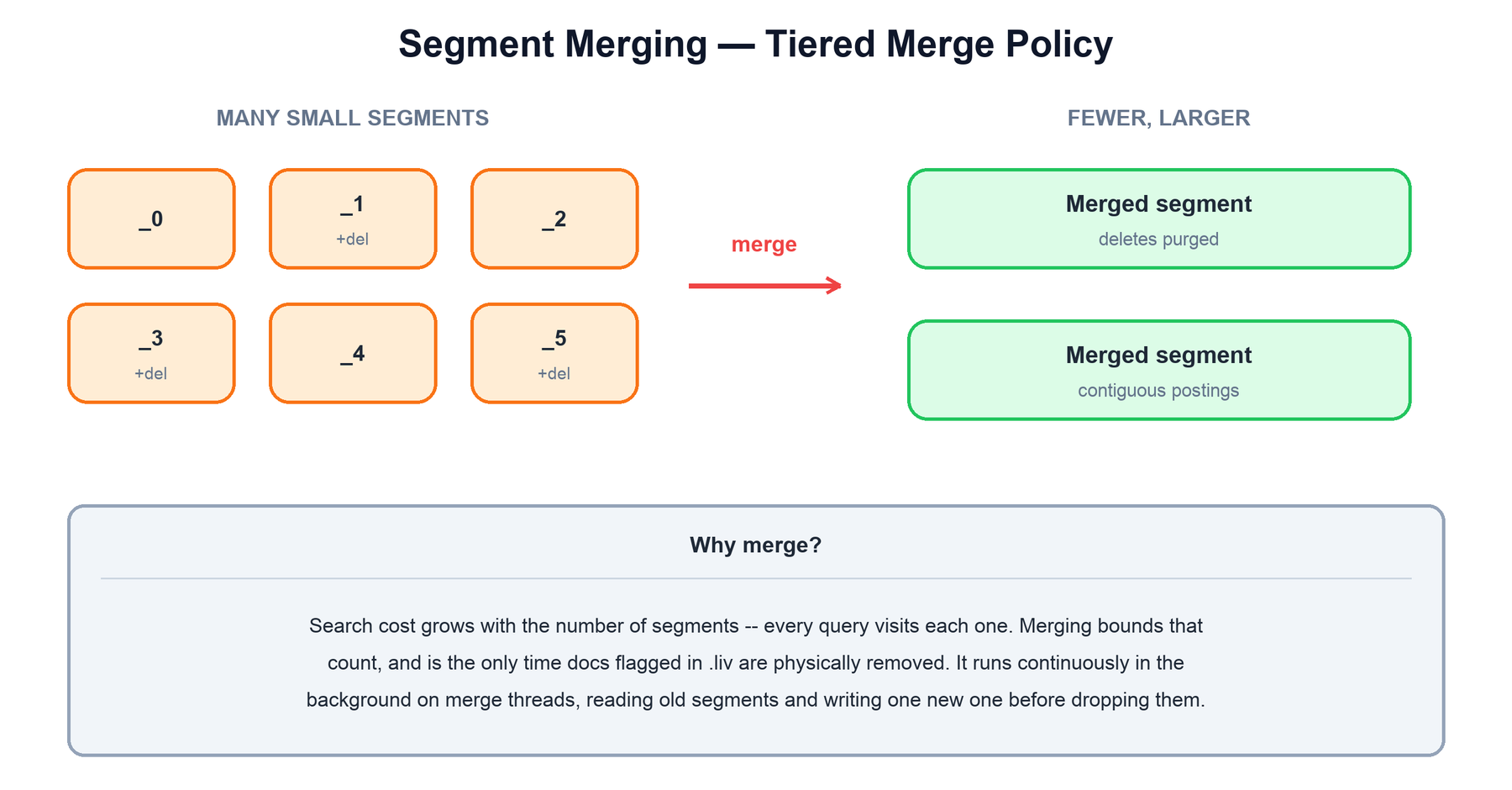
.liv are physically dropped in the process.Merging does two things at once:
- Bounds the segment count. Fewer segments means fewer postings lists to open and intersect per query, so search stays fast as the index grows.
- Reclaims deleted space. A merge reads only the live documents from the input segments, so tombstoned documents are physically dropped — this is the only time deleted data actually leaves the disk.
A MergePolicy decides which segments to merge and when. The default, TieredMergePolicy, groups segments into size tiers and merges within a tier, preferring segments with many deletes. Merges run on background threads, reading the inputs and writing one new segment before the old ones are dropped at the next commit — so search continues uninterrupted while a merge is in flight.
function maybeMerge(segments, policy): # runs continuously in background
candidates = policy.findMerges(segments) # by size tier + delete ratio
for group in candidates:
new_seg = merge(group.live_documents()) # dead docs excluded here
atomically_replace(group -> new_seg) # visible at next commit11. Near-Real-Time Search
A new document is searchable as soon as it is in a segment — and a flush creates a segment without a durable commit. Near-real-time (NRT) search exploits that gap: instead of committing (an fsync, which is slow), you open a reader over the just-flushed segments straight from the OS file cache.
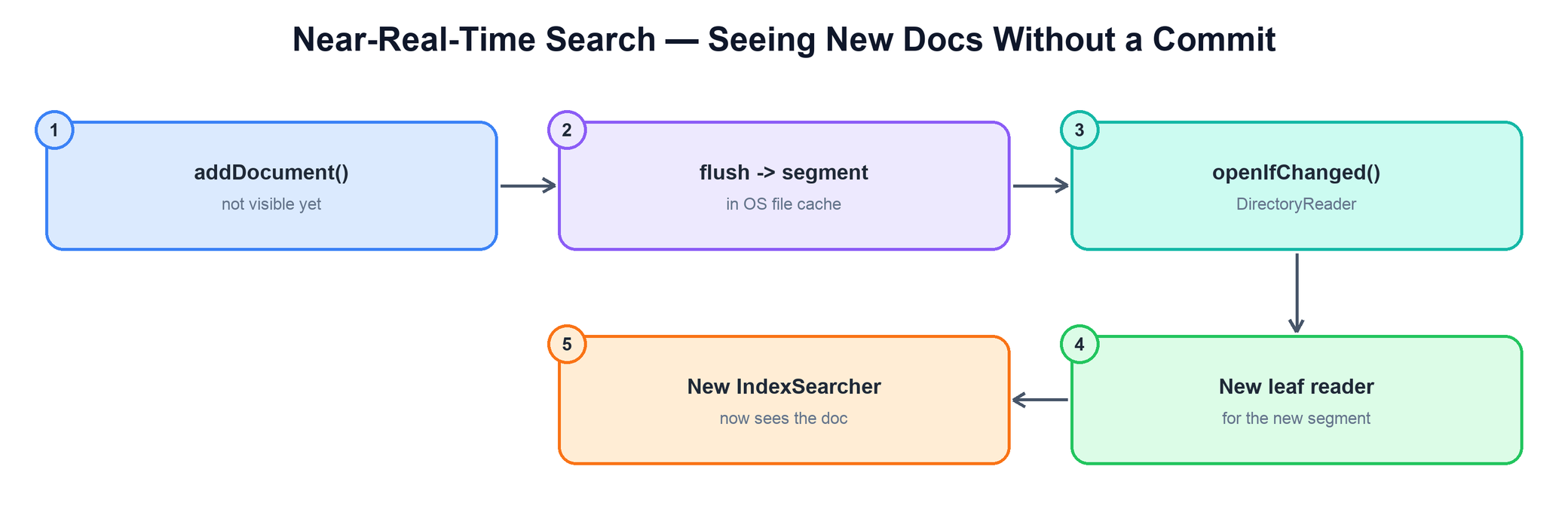
The mechanism is reader reopen. Rather than building a fresh reader from scratch, DirectoryReader.openIfChanged(oldReader) returns a new reader that reuses the leaf readers for unchanged segments and only opens leaves for the new ones. Because segments are immutable, this sharing is safe and cheap.
reader = DirectoryReader.open(writer) # NRT reader tied to the writer
... index more documents ...
newReader = DirectoryReader.openIfChanged(reader) # picks up flushed segments
if newReader != null:
reader.close() # old leaves not reused are released
reader = newReader
searcher = IndexSearcher(reader) # now sees the new documents12. Segment Files & Codecs
A single segment is physically a group of files that share one base name (_0.tim, _0.doc, …), each holding one part of the inverted index. The component that reads and writes these files is the Codec, and it is pluggable.
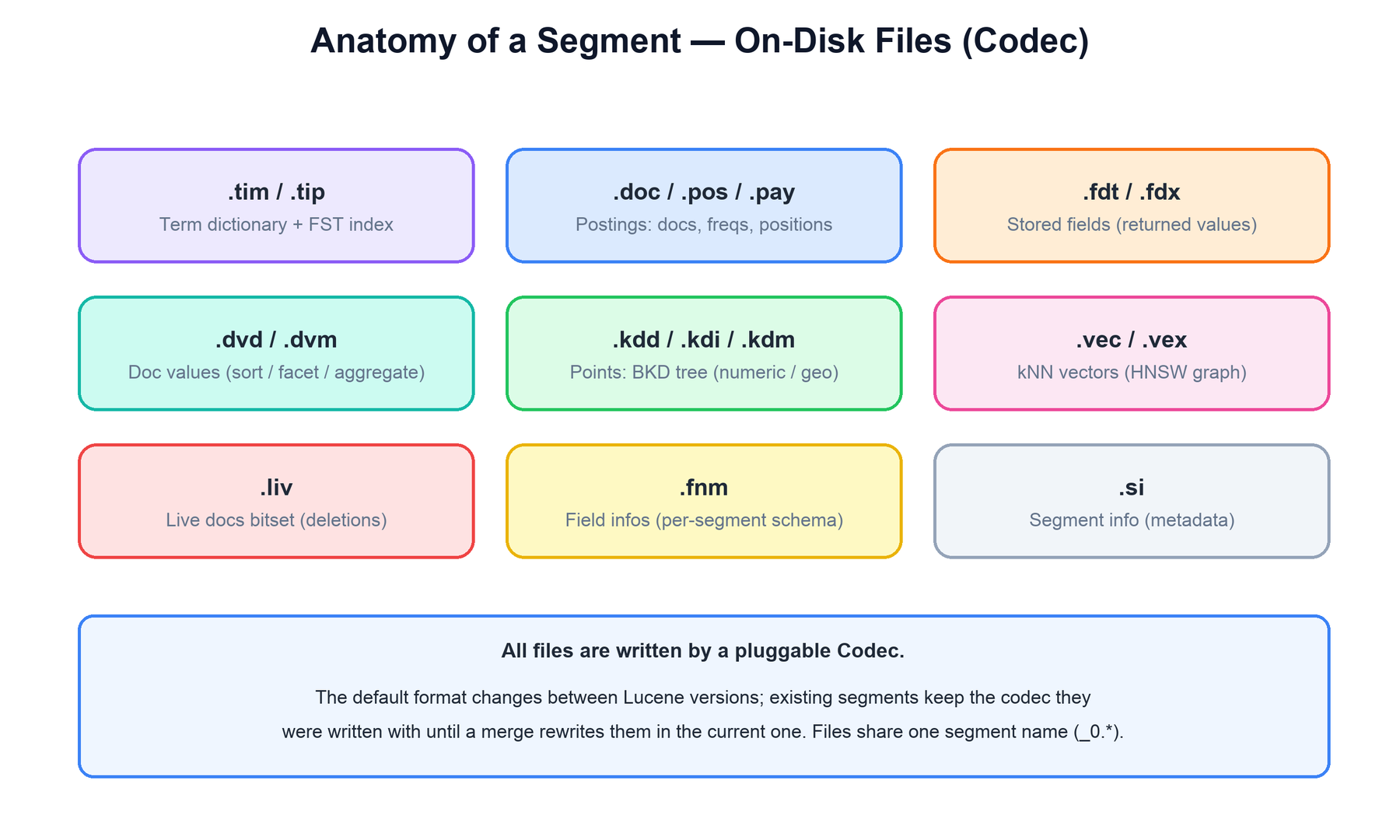
| Files | Hold |
|---|---|
.tim / .tip | Term dictionary and its FST term index. |
.doc / .pos / .pay | Postings: document IDs and frequencies, term positions, and payloads/offsets. |
.fdt / .fdx | Stored field values and their index (returned in hits). |
.dvd / .dvm | Doc values: the per-field column store for sort, facet, and aggregate. |
.kdd / .kdi / .kdm | Points: the BKD tree for numeric, date, and geo fields. |
.vec / .vex | kNN vector values and the HNSW graph for nearest-neighbor search. |
.liv | Live-docs bitset recording deletions for this segment. |
.fnm | Field infos: the per-segment record of which fields exist and how they were indexed. |
.si | Segment info: metadata such as document count and the codec used. |
Because the codec is recorded per segment, an index can hold segments written by different codec versions at once. When Lucene upgrades its default format, existing segments keep the codec they were written with until a merge rewrites them in the current one — which is why merging is also how a format upgrade physically happens.
13. Summary
Lucene is a small set of ideas that compose into fast, ranked, durable search on a single machine:
| Concern | Mechanism |
|---|---|
| What makes search fast? | An inverted index: each term points straight to a postings list of its documents, read with skip lists. |
| How is the index stored? | As immutable segments — small, complete sub-indexes — named by an atomic commit point (segments_N). |
| How does text become searchable? | An analyzer (char filters → tokenizer → token filters) turns it into terms, with the same analysis at index and query time. |
| How are documents written? | IndexWriter buffers them per thread (DWPT), flushes to a new segment, and commits to make them durable. |
| How are results ranked? | BM25 scoring from term frequency, inverse document frequency, and field-length normalization. |
| How do deletes and updates work? | Tombstones in a live-docs bitset; an update is a delete-by-term plus an add. Space is reclaimed only on merge. |
| How does the index stay fast over time? | Background merging bounds the segment count and physically drops deleted documents. |
| How are new documents seen quickly? | Near-real-time reopen over flushed segments, reusing unchanged leaf readers — visibility without an fsync. |
| How is the on-disk format defined? | A pluggable per-segment codec writing one file group per structure (terms, postings, stored, doc values, points, vectors). |