Designing Live Comments / Presence
A system design interview guide to building the real-time comment and presence layer for a live stream, where a single comment must reach hundreds of thousands of concurrent viewers within about a second, and the system must track who is online — all while staying up when the comment volume becomes overwhelming.
Live comments on a popular stream is one of the most demanding real-time problems in the interview canon because the fan-out ratio is brutal: one person types a comment, and that single write has to become hundreds of thousands of reads, delivered almost instantly, to viewers scattered across the world. On top of that sits presence — the running count and roster of who is currently watching — which sounds trivial until you realize that maintaining it exactly for a million viewers is its own distributed-systems headache. And both of these have to degrade gracefully rather than collapse when a stream goes viral and the comment rate spikes by orders of magnitude. This guide builds up a design around persistent connections, a pub/sub broadcast backbone, TTL-based presence, and deliberate load-shedding.
Contents
1. The Fan-Out Challenge
The defining characteristic of live comments is the fan-out ratio. On a stream with 500,000 concurrent viewers, every single comment is one inbound message that must turn into 500,000 outbound deliveries, and the latency budget is roughly one second end to end — slower than that and the chat stops feeling "live" and starts feeling like a delayed transcript. Multiply by even a modest comment rate and the outbound message volume dwarfs the inbound by five or six orders of magnitude.
This asymmetry is what makes the usual request/response web model the wrong tool. You cannot have half a million clients polling for new comments every second; the read amplification would melt any backend, and a poll interval long enough to be affordable would be too slow to feel live. The system has to be push-based: the server holds an open channel to every viewer and pushes new comments down it the instant they arrive. Everything else in the design — persistent connections, a broadcast backbone, presence, load-shedding — exists to make that push fast, cheap, and survivable at scale.
| Dimension | Live comments | Why it is hard |
|---|---|---|
| Write rate | Modest — humans type. | Not the bottleneck. |
| Read fan-out | One write → hundreds of thousands of deliveries. | Massive amplification per message. |
| Latency budget | ~1 second, end to end. | No time for polling or batching. |
| Concurrency | Hundreds of thousands of open connections per stream. | Connection state, not request throughput, is the limit. |
2. Persistent Connections
Because the system must push, each viewer holds a persistent connection to the server rather than making repeated requests. The standard choice is a WebSocket — a full-duplex channel that stays open for the life of the viewing session — with long-polling as a fallback for clients or networks that cannot hold a WebSocket open.
These connections terminate on a fleet of gateway nodes whose entire job is to own connection state. A gateway node accepts thousands of viewer connections, knows which streams each connection is subscribed to, and forwards a comment down every relevant socket the moment it receives one. Separating this gateway tier from the application logic is deliberate and important:
- Connections are the scaling unit. The binding constraint is not CPU or request throughput but the number of simultaneous open sockets and the memory they consume. Isolating that concern in a dedicated, horizontally scalable tier lets you add capacity for connections without touching the comment service.
- The application stays stateless about connections. The comment service does not need to know which physical socket a viewer is on; it just publishes a comment for a stream, and the gateways figure out delivery. This keeps the business logic simple and the gateways dumb but fast.
- Graceful handling of churn. Viewers join and leave constantly. A gateway tier built around connection lifecycle handles connect, disconnect, and reconnect cleanly, which is exactly what presence also depends on.
3. End-to-End Architecture
The architecture is a layered pipeline: viewers hold WebSocket connections to gateway nodes; gateway nodes both publish new comments to and subscribe for broadcasts from a pub/sub backbone; and a comment service sits behind the backbone to order, dedup, and persist comments.
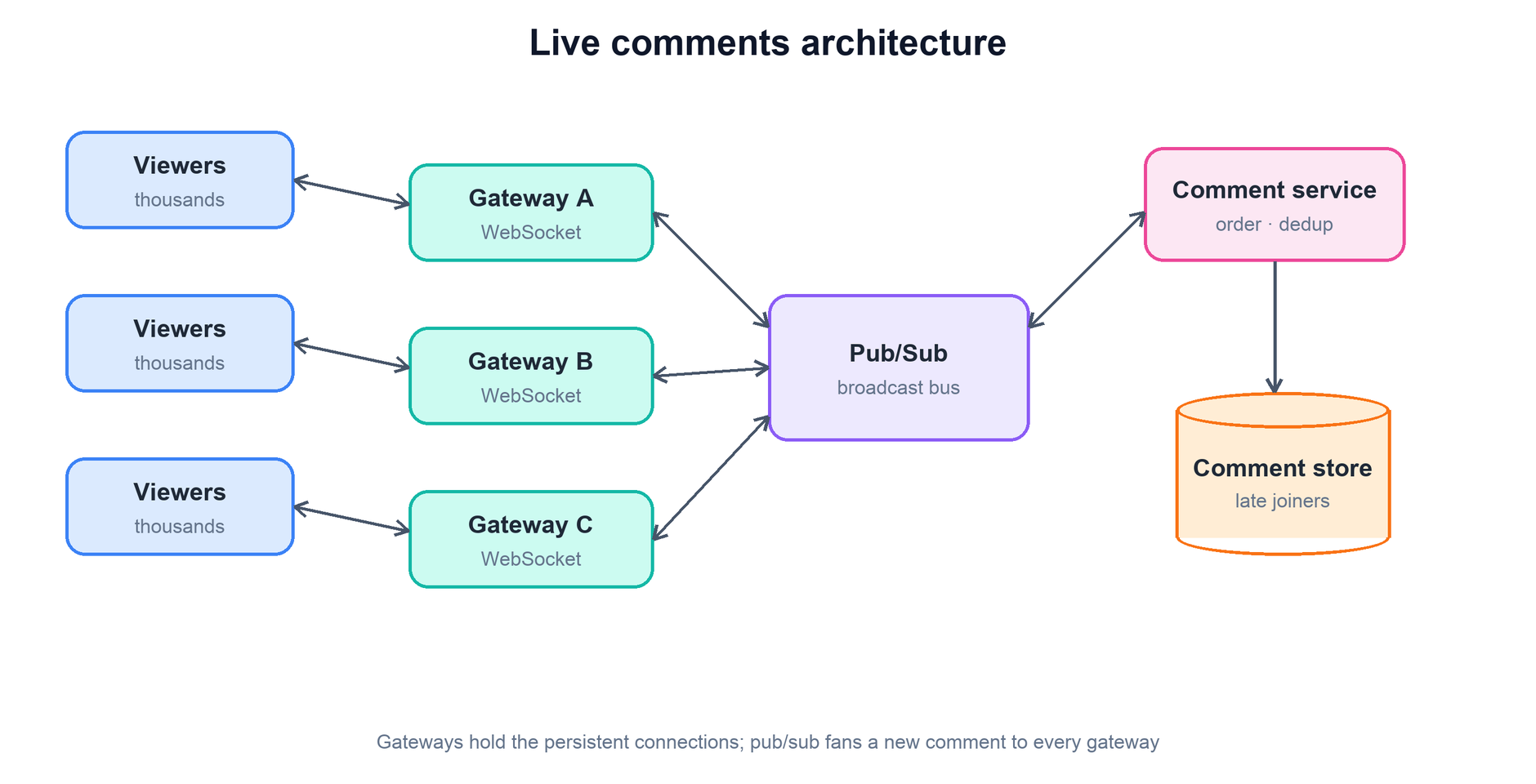
Following a comment through the system:
- Viewers. Each runs a client holding one WebSocket to a gateway. The client sends comments up that socket and renders comments pushed down it.
- Gateway nodes. The connection tier. When a viewer posts a comment, their gateway hands it to the comment service (via the backbone). When any comment for a stream appears on the backbone, every gateway holding subscribers to that stream pushes it down their sockets.
- Pub/Sub backbone. The broadcast bus. A comment published once is delivered to every gateway subscribed to that stream's channel. This is the mechanism that lets a comment reach viewers no matter which gateway they happen to be connected to.
- Comment service. The brain. It assigns ordering, dedups, applies any load-shedding policy, and decides what gets broadcast and persisted.
- Comment store. Durable storage of recent comments, so a viewer who joins mid-stream can backfill the last N comments rather than seeing an empty chat.
4. Broadcasting via Pub/Sub
The crux of the fan-out is this: a comment can be typed by a viewer connected to any gateway, and it must reach viewers connected to every gateway. With dozens or hundreds of gateway nodes, you cannot have each gateway talk to every other gateway directly — that is an N-squared mesh that becomes unmanageable. Instead, a pub/sub backbone decouples publishers from subscribers: a gateway publishes a new comment to the stream's channel exactly once, and the backbone fans it out to all gateways subscribed to that channel.
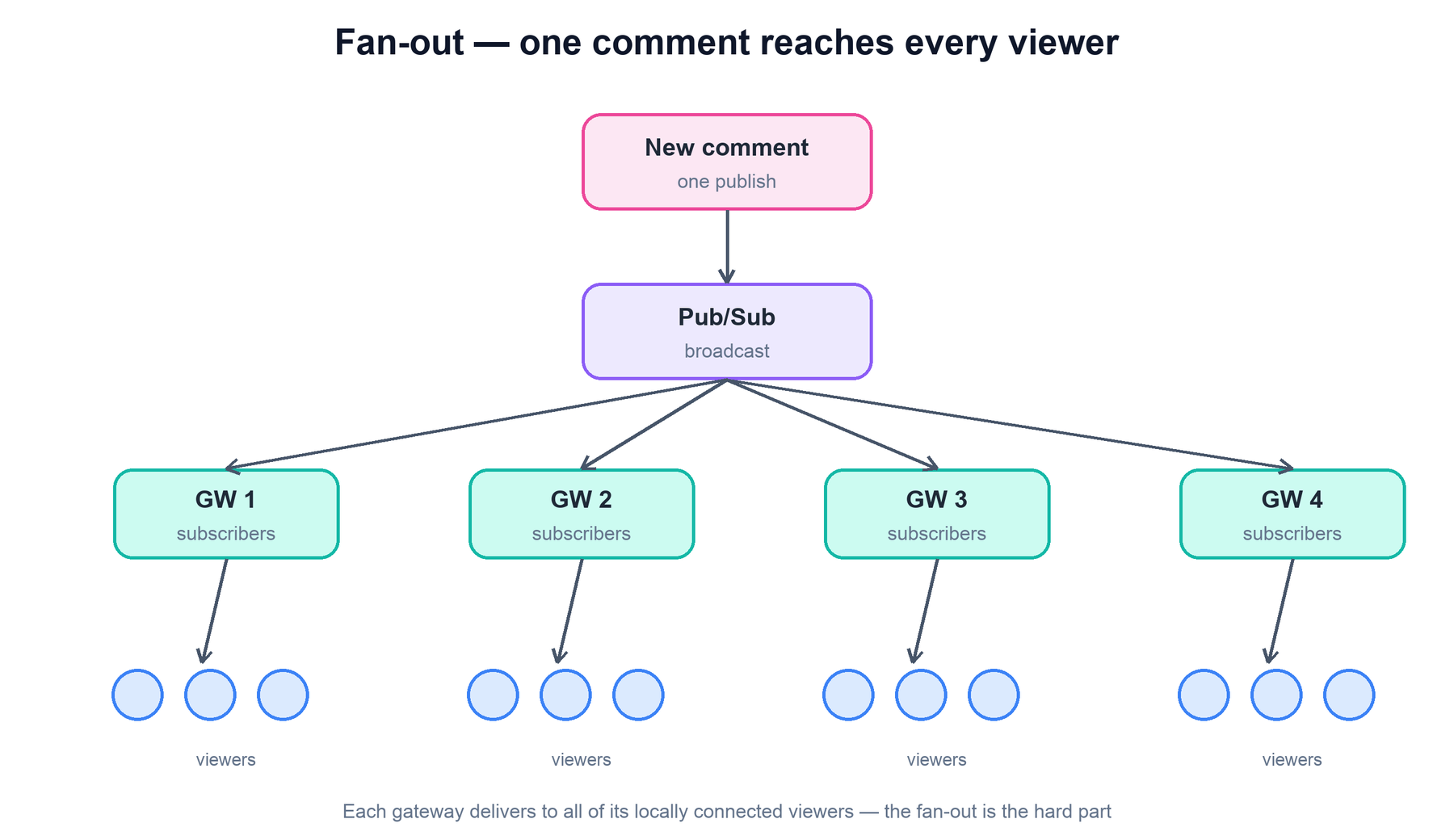
The win is a two-stage fan-out. The first stage (backbone → gateways) is small: there are only as many gateways as you run, perhaps a few hundred. The second stage (gateway → sockets) is large but local: each gateway pushes to its own few thousand connected viewers, in memory, with no cross-network coordination. The expensive fan-out happens at the edge, in parallel, on hardware sized exactly for it.
# a viewer posts a comment
function on_comment(stream_id, comment):
pubsub.publish(channel=stream_id, message=comment) # publish ONCE
# every gateway runs this for streams its viewers watch
function on_broadcast(stream_id, comment):
for sock in local_subscribers(stream_id): # local, in-memory
sock.push(comment) # the big fan-out, at the edge5. Presence with Heartbeats
Presence answers "who is watching right now?" — both the live count and, sometimes, the roster. The challenge is that there is no clean "I left" signal you can rely on: viewers close laptops, lose signal, and drop off without a graceful disconnect. So presence cannot be a simple add-on-join, remove-on-leave set. The standard solution is heartbeats with a TTL.
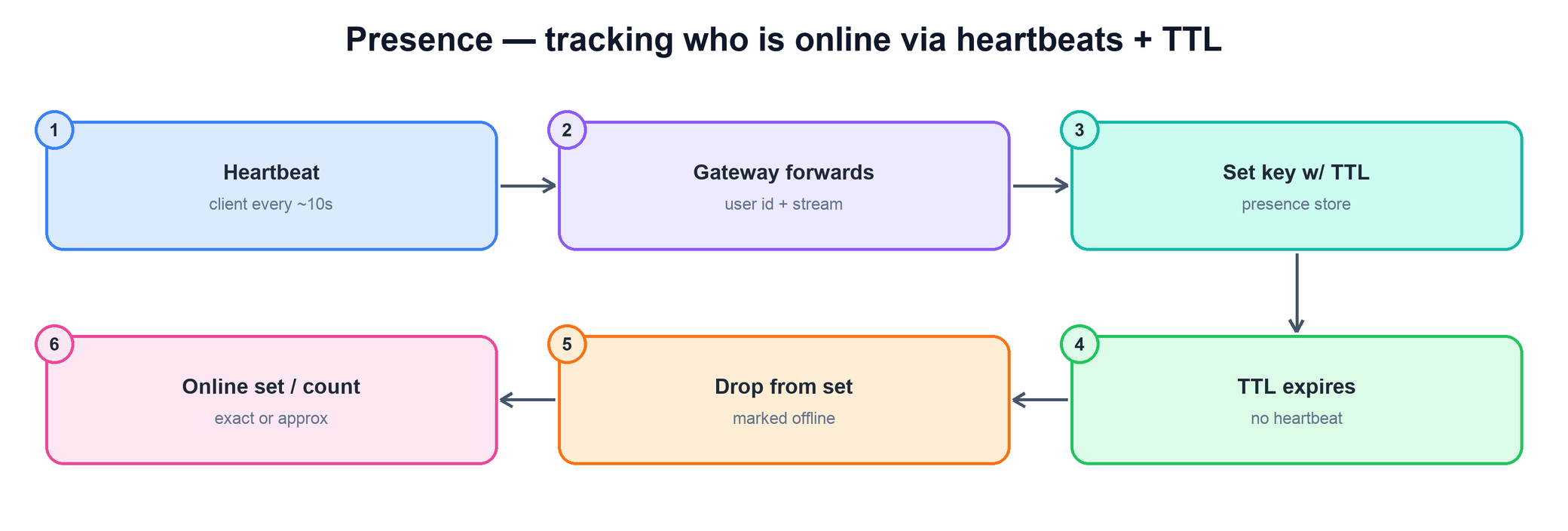
The mechanism is simple and robust: each client sends a heartbeat (say every 10 seconds); on each heartbeat the presence store records the viewer's id under the stream with a TTL slightly longer than the interval (say 30 seconds). As long as heartbeats keep coming, the key keeps getting refreshed and the viewer counts as online. The moment heartbeats stop — for any reason — the key expires on its own and the viewer silently drops out. Crashes, network drops, and clean exits all converge to the same correct outcome without a reliable disconnect signal.
function on_heartbeat(stream_id, user_id):
presence.set(key=(stream_id, user_id), ttl=30s) # refresh on each beat
function online_count(stream_id):
return presence.count(stream_id) # keys not yet expiredAt scale, exact presence becomes expensive. Maintaining and querying a precise set of a million live keys, updated every few seconds, is a heavy write and memory load. The usual trade is to relax precision where it does not matter:
- Approximate counts. Showing "1.2M watching" does not require an exact integer. A probabilistic counter (such as a HyperLogLog-style estimator) gives a close-enough number at a fraction of the memory.
- Sampled or sharded heartbeats. Aggregate heartbeats per gateway and report partial counts upward, rather than tracking every individual in one global set.
- Exact only when needed. Reserve a precise roster for small contexts (a private room, the host's view of named participants) where the cost is bounded and the exactness is a real feature.
6. Ordering and Dedup
Two correctness issues follow from a distributed, push-based pipeline. First, ordering: comments originate on different gateways and traverse the backbone, so without care they can arrive at different viewers in different orders, making a conversation read incoherently. Second, dedup: retries on the client (a resend after a flaky connection) or at-least-once delivery in the backbone can cause the same comment to appear twice.
Both are handled in the comment service, the one place every comment passes through. Assigning each comment a sequence number per stream at the point of acceptance gives a single authoritative order that clients can use to render consistently and to detect gaps. Giving each comment a unique id (client-generated) lets the service drop duplicates before broadcasting, so a client resend never produces a double-posted comment.
function accept(stream_id, comment):
if seen.contains(comment.client_msg_id): # dedup client retries
return DUPLICATE
comment.seq = next_seq(stream_id) # authoritative order
seen.add(comment.client_msg_id)
store.append(stream_id, comment)
pubsub.publish(stream_id, comment)
return comment.seqPerfect global ordering across a massive distributed fan-out is neither achievable nor necessary — what matters is that every viewer sees a consistent order, which the per-stream sequence number provides, and that nobody sees the same comment twice, which the id-based dedup guarantees.
7. Load Shedding at Extreme Volume
When a stream goes truly viral, comment volume can outrun the rate at which it is even meaningful — thousands of comments per second on a chat no human can read that fast. Pushing all of them would saturate the backbone, the gateways, and the clients, and would degrade the experience for everyone. The right response is deliberate load-shedding: serve a representative, readable subset rather than collapsing under the full firehose.
Several policies, often combined, keep the system within budget:
- Sampling. Above a threshold rate, broadcast only a fraction of comments — enough to keep the chat lively and representative without overwhelming clients. The author still sees their own comment, so it feels delivered.
- Rate limiting per author. Cap how many comments a single user can post per window, blunting spam and floods at the source.
- Per-stream caps. Bound the total broadcast rate for a stream; excess is dropped (and still persisted for history, if desired) rather than fanned out.
- Prioritization. Preferentially deliver higher-signal comments — from the host, moderators, or verified accounts — when shedding the rest.
function should_broadcast(stream_id, comment):
rate = stream_rate(stream_id)
if rate > SHED_THRESHOLD:
if is_high_priority(comment): return True # host / mods always
return sample(SAMPLE_FRACTION) # keep a readable subset
return True8. Persistence for Late Joiners
A viewer who joins a stream that is already in progress should not see an empty chat. To make that work, the comment service writes accepted comments to a comment store, and a newly connected client backfills the most recent N comments before it starts receiving the live push stream.
The access pattern is narrow and predictable, which makes the store easy to design: it is almost entirely "give me the last N comments for this stream, in order," keyed by stream and sequence number. That favors an append-optimized store with a tail-read path, and it pairs naturally with the per-stream sequence numbers from the ordering layer — backfill returns comments up to the latest sequence, and the live stream picks up from there with no gap and no duplication. Older comments can roll off to cheaper storage or be trimmed entirely, since the live experience only ever needs the recent tail.
function on_join(stream_id, client):
recent = store.tail(stream_id, n=50) # backfill recent history
client.send(recent)
gateway.subscribe(client, stream_id) # then attach to live push9. Summary
Live comments and presence is fundamentally a broadcast problem: turning one write into a near-instant fan-out to a huge audience, while tracking who is online and surviving extreme volume. The design is a set of reinforcing decisions:
| Concern | Mechanism |
|---|---|
| What makes this hard? | The fan-out: one comment must reach hundreds of thousands of viewers within ~1 second. |
| How do we push to viewers? | Persistent WebSocket (or long-poll) connections terminated on a dedicated gateway tier. |
| How does a comment reach every gateway? | A pub/sub backbone: publish once, broadcast to all subscribed gateways. |
| How is the big fan-out kept cheap? | Two-stage fan-out — small backbone-to-gateway step, large but local gateway-to-socket step. |
| Who is online? | Heartbeats with a TTL; presence keys self-expire. Approximate counts at scale. |
| How do we keep comments coherent? | Per-stream sequence numbers for order, unique ids for dedup. |
| What about a viral firehose? | Load-shedding: sampling, per-author and per-stream rate caps, prioritizing high-signal comments. |
| What do late joiners see? | A comment store holding the recent tail, backfilled before attaching to the live push. |