03 · SRE Partnership
How to answer the reliability and SRE-partnership questions in a senior engineering-leadership loop: the framework to structure each answer, what the interviewer is really listening for, and where inside Meta to pull the evidence that backs your story.
This area tests one thing: can you treat reliability as a feature you budget for, lead calmly through an outage, and make the durable fix instead of the band-aid. Interviewers are not grading whether your systems have ever broken — they assume they have. They are grading judgment: did you set explicit SLOs, spend the error budget on purpose, mitigate before you debugged, run a blameless postmortem, and drive the systemic fix that stopped the page from coming back. Every answer below is built on the CARL shape — Context, Actions, Results, Learnings — with most of your words spent on the decisions and tradeoffs.
Questions on this page
- How to answer this area — the reliability framework
- Reliability thinking and partnering with SRE
- A major incident or outage you led through
- Keeping on-call sustainable and reducing toil
- Setting SLOs and using error budgets
- Justifying a reliability investment against feature pressure
- More questions you might get
- What's the difference between an SLI, an SLO, and an SLA — and how do you use each?
- How do you decide whether a service is reliable enough?
- Tell me about a postmortem that changed how your team operates.
- How do you design alerting that pages on symptoms without drowning on-call in noise?
- How do you handle a chronically unreliable dependency you don't own?
- Describe a time you had to push back on shipping because of reliability risk.
- How do you build a blameless culture when an outage was clearly someone's mistake?
How to answer this area — the reliability framework
Every SRE-partnership question can be answered with the same six-step spine. Walk it in order and you will hit the signals interviewers look for without rambling.
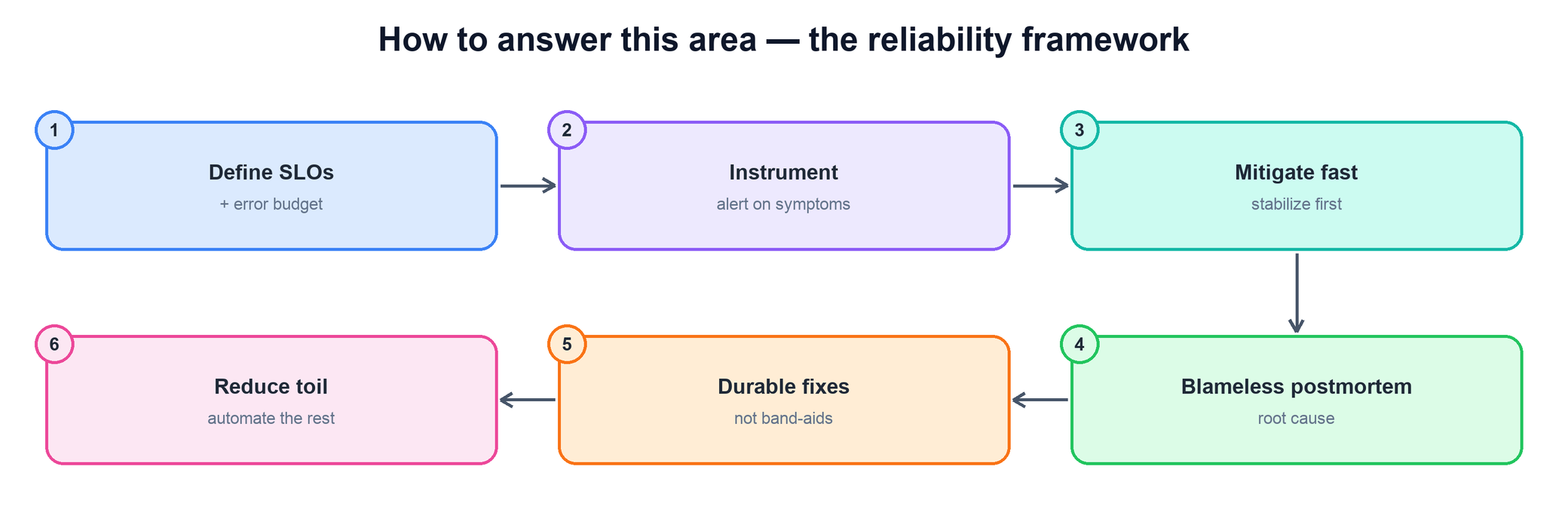
- Define SLOs — set the target, not 100%. Pick user-centric SLIs and an explicit error budget. Reliability is a number you agree to, not perfection you chase.
- Instrument — alert on symptoms. Page on what the user feels (latency, errors, availability), not on every internal cause. Noisy cause-based alerts are how on-call burns out.
- Mitigate fast — stabilize before you debug. The first job in an incident is to stop the bleeding — roll back, fail over, shed load — then find the root cause.
- Blameless postmortem — find the systemic cause. Separate the human from the system. The question is what let the failure happen and what made it hard to detect.
- Durable fixes, then reduce toil. Prefer the fix that prevents recurrence over the band-aid, and automate or delete the repetitive operational work that remains.
- Reliability framed as a budgeted tradeoff, not an absolute.
- Mitigate-first instinct — calm under an active outage.
- Blameless culture: systems thinking, not finger-pointing.
- A bias toward durable fixes and automation over heroics.
- "I" for the calls you made, "we" for how the team responded.
- SEV review tool — pull from your SEVs and their postmortems for the timeline, root cause, and action items.
- On-call tool / IcM — pull from page history and MTTR to show detection and recovery times.
- ODS counters + Unidash SLA dashboards — pull from these for SLO attainment and error-budget burn.
- Runbooks on the internal wiki — pull from the runbook you wrote or improved as evidence of operability.
- GSD — pull from your reliability projects and their milestones to show the investment over time.
How do you think about reliability for your systems, and how do you partner with SRE?
The opening philosophy question for this area. They want to hear that you own reliability as a first-class product concern and treat SRE as a shared-ownership partner, not a pager you hand off to.
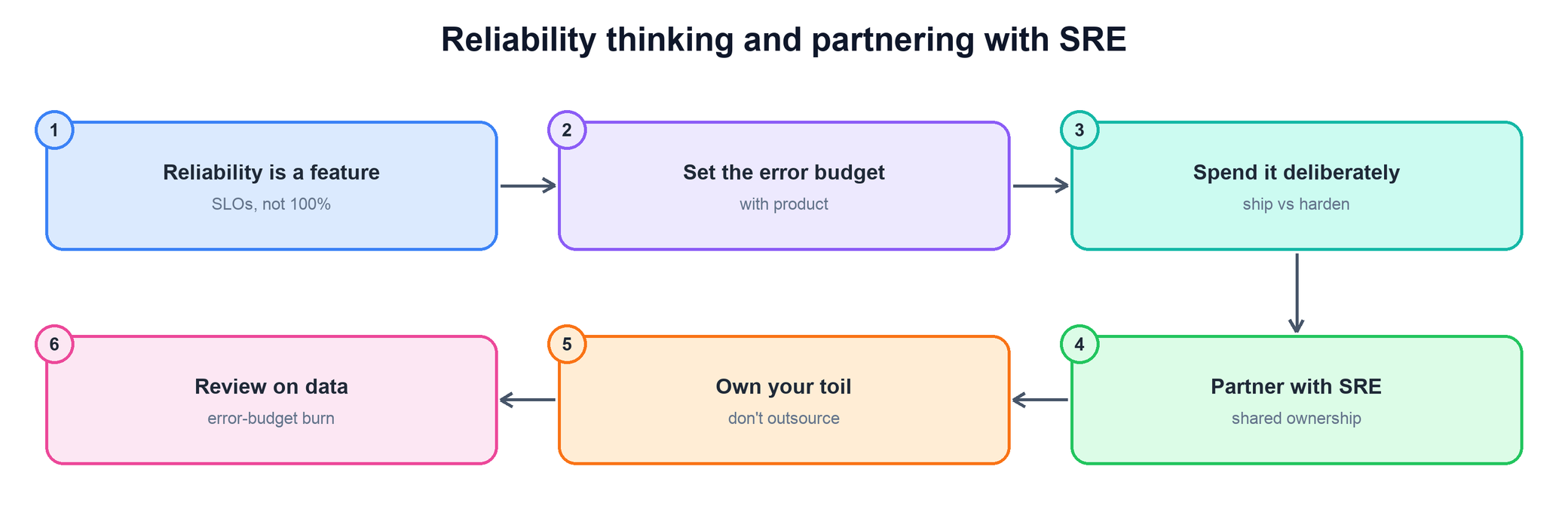
- Open by framing reliability as a feature with a cost, not a goal of 100% — the target is the SLO you can defend.
- Describe how you set the error budget with product, so the business owns the reliability target alongside engineering.
- Explain that you spend the budget deliberately: when it is healthy you ship; when it is burning you harden.
- Position SRE as a shared-ownership partner — you don't outsource the pain; the dev team owns its own toil and pages.
- Close on the operating cadence: you review on data — error-budget burn and page load — not on vibes.
- Reliability owned as a product concern, not delegated away.
- Error budgets used to make real ship-vs-harden decisions.
- A true partnership model with SRE, not a thrown-over-the-wall pager.
- The dev team owning its own toil and on-call load.
- ODS counters + Unidash SLA dashboards — pull from these for the SLOs you set and how the budget tracked.
- On-call tool / IcM — pull from page volume to show who carries the load and how it trended.
- GSD — pull from the reliability projects you co-owned with SRE.
- Runbooks on the internal wiki — pull from the shared runbooks as proof of joint ownership.
Tell me about a major incident or outage you led through. What did you do and what changed after?
The flagship question for this area. They want a real outage you led — clear roles, mitigate-first, a blameless root cause, and a durable fix that measurably changed the system after.
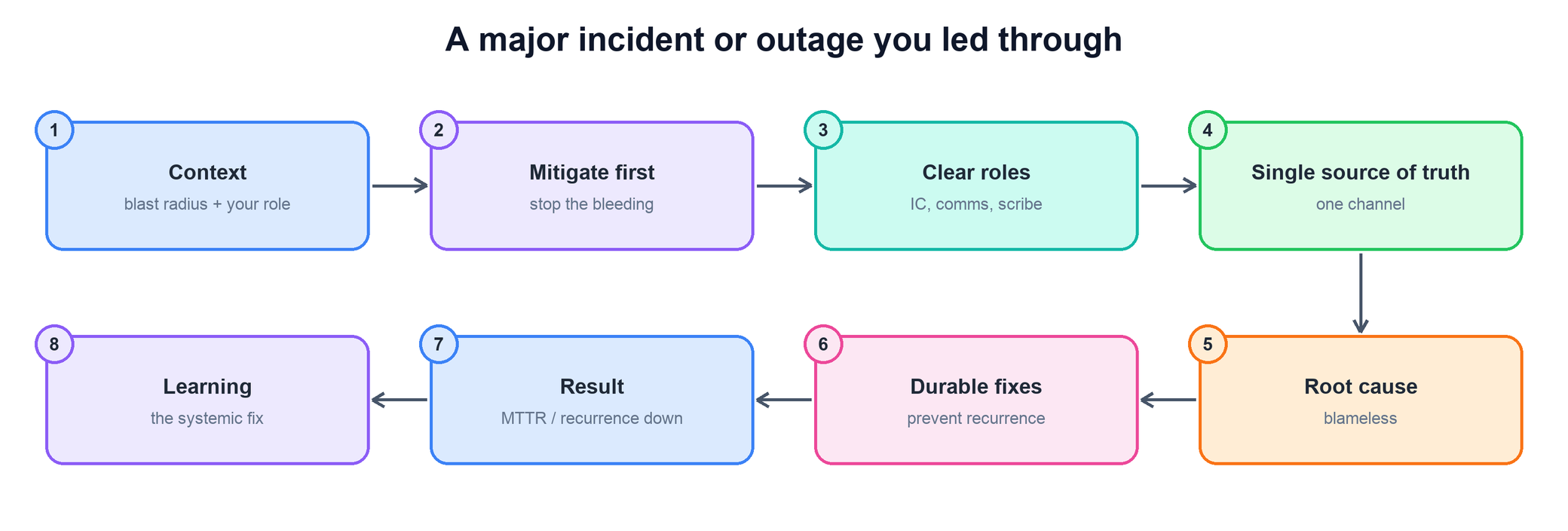
- Open with the context and blast radius in two sentences: what broke, who it hit, and your role in the response.
- Say you mitigated first — rolled back, failed over, or shed load to stop the bleeding before chasing the cause.
- Describe how you set clear roles (incident commander, comms, scribe) and a single source of truth so the response didn't fragment.
- Walk the blameless root cause and the durable fixes — the change that prevents recurrence, not the patch that hides it.
- Land a quantified result (MTTR down, recurrence gone) and close with the systemic learning you carried forward.
- Calm command under pressure — a mitigate-first instinct.
- Clear incident structure: roles, comms, one channel of truth.
- A blameless, systems-level root cause — no scapegoats.
- Durable fixes that measurably changed reliability afterward.
- SEV review tool — pull from the SEV and its postmortem for the timeline, root cause, and action items.
- On-call tool / IcM — pull from the page and MTTR to quantify detection and recovery.
- ODS counters + Unidash — pull from the metric graphs that show the impact and the recovery.
- Runbooks on the internal wiki — pull from the runbook you created or updated as a direct outcome.
How do you keep on-call sustainable and reduce operational toil for your team?
This question tests whether you protect your people from burnout — measuring the operational load, attacking the worst of it at the root, and keeping the rotation humane.
- Start by measuring the load — pages per shift and hours of toil — so the problem is a number, not a feeling.
- Use Pareto to find the top few pages driving most of the pain, and attack those first.
- Automate or delete the repetitive work by fixing the root cause — auto-remediation, better defaults, or removing the alert entirely.
- Set a sustainable rotation with a load budget; if a rotation blows the budget, that is a signal to invest, not to push harder.
- Protect people from hero culture — reward the durable fix, not the all-nighter — and close with the drop in pages per week.
- Toil treated as a measurable, fixable engineering problem.
- Root-cause attacks on the noisiest pages, not just triage.
- A humane rotation with an explicit load budget.
- Genuine care for the team — no glorifying of heroics.
- On-call tool / IcM — pull from page counts per rotation to show the load before and after.
- SEV review tool — pull from recurring SEVs to identify the top sources of toil.
- GSD — pull from the toil-reduction or automation projects you drove.
- Runbooks on the internal wiki — pull from the runbooks you automated away or simplified.
How do you set SLOs and use error budgets to make decisions?
A focused mechanics question. They want to see that you can define meaningful SLIs, set defensible targets, and actually use the error budget to gate decisions — not just put a number on a dashboard.
- Start from user-centric SLIs — latency, availability, correctness — the things a user actually experiences, not internal proxies.
- Set SLO targets that are realistic and agreed with product, so the number has buy-in and can be defended.
- Derive the error budget as one minus the SLO, and treat it as the currency for risk-taking.
- Alert on burn rate with both fast and slow windows, so you catch sudden cliffs and slow leaks without paging on noise.
- Let the budget gate releases — freeze risky changes when it is spent — and review ship-vs-harden with product on the data.
- SLIs that map to real user experience, not vanity metrics.
- Targets set with product buy-in, not chosen unilaterally.
- Error budgets that actually change behavior — release gates, not decoration.
- Burn-rate alerting that balances sensitivity against noise.
- ODS counters + Unidash SLA dashboards — pull from these for the SLIs, SLO attainment, and budget burn.
- On-call tool / IcM — pull from burn-rate alert history to show the alerting actually fired meaningfully.
- GSD — pull from the project where you stood up or tightened the SLOs.
- Internal wiki — pull from the SLO definition or reliability spec where the targets are written down.
Tell me about a reliability investment you had to justify against feature pressure.
An influence-and-tradeoff question. They want to see you make the case for reliability work when the roadmap is loud — quantifying the risk, framing reliability as a feature, and sequencing the bet alongside delivery.
- Set the context: the reliability risk you saw and the feature-roadmap pressure pushing against fixing it.
- Quantify the risk in terms leadership feels — SEV cost, hours of toil, or error-budget burn — not "it feels fragile."
- Frame it as a tradeoff: reliability is a feature with ROI, and shipping on a system that is burning its budget is borrowing against the future.
- Make the bet — scope the investment to the smallest version that meaningfully moves the risk — and sequence it alongside delivery rather than blocking it.
- Land the result (incidents down, budget recovered) and close with the learning: fund the fix before the SEV forces your hand.
- Risk quantified in business terms, not engineering anxiety.
- Reliability framed as a tradeoff with ROI, not a tax.
- A scoped, sequenced bet — not "stop everything to fix it."
- Influence: you won the investment without owning the roadmap.
- SEV review tool — pull from past SEVs to quantify the cost of not investing.
- ODS counters + Unidash SLA dashboards — pull from these for the budget burn that justified the work.
- On-call tool / IcM — pull from page load to show the human cost of the status quo.
- GSD — pull from the reliability project you scoped and sequenced, and its outcome.
More questions you might get — SRE Partnership
All of these reduce to the same spine: set a defensible SLO, spend the error budget on purpose, mitigate before you debug, fix the system not the symptom, and protect your people. Have a story ready for each.
What's the difference between an SLI, an SLO, and an SLA — and how do you use each?
How to answer- SLI is the measurement — a user-centric signal like latency, availability, or correctness.
- SLO is the target you set on that SLI internally — the line you agree to defend, never 100%.
- SLA is the contract — the externally promised number with consequences; keep it looser than the SLO so you have headroom.
- Use them as a stack: measure the SLI, gate decisions on the SLO and its error budget, and protect the SLA from ever being threatened.
How do you decide whether a service is reliable enough?
How to answer- Anchor on the user, not perfection — "enough" is the SLO where extra nines stop being worth the cost.
- Watch the error budget: if it is consistently underspent you are over-investing and could ship faster.
- Set the target with product so reliability is a budgeted business tradeoff, not an engineering preference.
- Revisit on data — re-tune the SLO when usage, dependencies, or user expectations change.
Tell me about a postmortem that changed how your team operates.
How to answer- Context: name the incident in two sentences — what broke and why the postmortem mattered.
- Actions: ran it blameless, separated human from system, and dug to the systemic cause and the detection gap.
- Results: the durable change it produced — a new guardrail, alert, or process — with a metric like recurrence gone or MTTR down.
- Learnings: the operating habit it left behind — how the team reviews or builds differently now.
How do you design alerting that pages on symptoms without drowning on-call in noise?
How to answer- Page on symptoms, what the user feels — latency, errors, availability — not every internal cause.
- Tie pages to the SLO via burn-rate alerts: fast windows for sudden cliffs, slow windows for quiet leaks.
- Every page must be actionable — if there's no human action, it's a dashboard or a ticket, not a page.
- Audit noise relentlessly — review the noisiest alerts and tune, automate, or delete them at the root.
How do you handle a chronically unreliable dependency you don't own?
How to answer- Quantify the impact first — how much of your error budget the dependency burns — so the conversation is data, not blame.
- Defend your boundary: timeouts, retries with backoff, circuit breakers, and graceful degradation so its failures don't become yours.
- Make it the owner's problem with evidence — an SLO expectation backed by your burn data, escalated through the right channel.
- Have a fallback plan — cache, secondary path, or feature flag — for when it fails anyway.
Describe a time you had to push back on shipping because of reliability risk.
How to answer- Context: the change under pressure to ship and the concrete reliability risk it carried.
- Actions: framed it on the error budget — shipping while the budget is spent is borrowing against the future — and proposed a scoped path to ship safely.
- Results: the outcome — a guardrail added, rollout staged, or release gated — and the incident you avoided.
- Learnings: show influence without authority — you won on data and tradeoffs, not by blocking.
How do you build a blameless culture when an outage was clearly someone's mistake?
How to answer- Reframe the question: ask what let one person's action take the system down, not who did it.
- Fix the system — the missing guardrail, review, or safety check — so the same mistake can't recur.
- Model it as the leader: people surface failures honestly only when they're safe, which is how you find real root causes.
- Separate accountability from blame — learning is shared and systemic; punishment just drives the next failure underground.