02 · Technical Design
How to answer the technical-design questions in a senior engineering-leadership loop: the framework to structure each answer, what the interviewer is really listening for, and where inside Meta to pull the evidence that backs your story.
This area tests one thing: can you own a hard design decision, defend the tradeoff, and build a system that survives scale and failure. Interviewers are not grading whether you can draw boxes — they assume you can. They are grading judgment: did you understand the requirements, consider real alternatives, decide on an explicit axis, design for the failure case, and prove the design held up in production. Every answer below is built on the CARL shape — Context, Actions, Results, Learnings — with most of your words spent on the decisions and tradeoffs only you could have made.
Questions on this page
- How to answer this area — the framework
- Walk me through a system you architected
- A difficult technical tradeoff — how you decided
- Staying technical — and handling disagreement
- A build-vs-buy decision — avoiding lock-in
- A large migration or re-architecture you led
- Raising the technical bar and design reviews
- More questions you might get
- How do you design a system when the requirements are still ambiguous or changing?
- Tell me about a design decision you got wrong. How did you find out, and what did you do?
- How do you choose between consistency and availability for a given system?
- Walk me through how you'd design for 10x the current scale.
- How do you manage and pay down technical debt without stalling delivery?
- Tell me about a time you had to simplify an over-engineered design.
- How do you evaluate a new technology before betting a system on it?
How to answer this area — the technical-leadership framework
Every technical-design question can be answered with the same six-step spine. Walk it in order and you will hit the signals interviewers look for without getting lost in implementation detail.
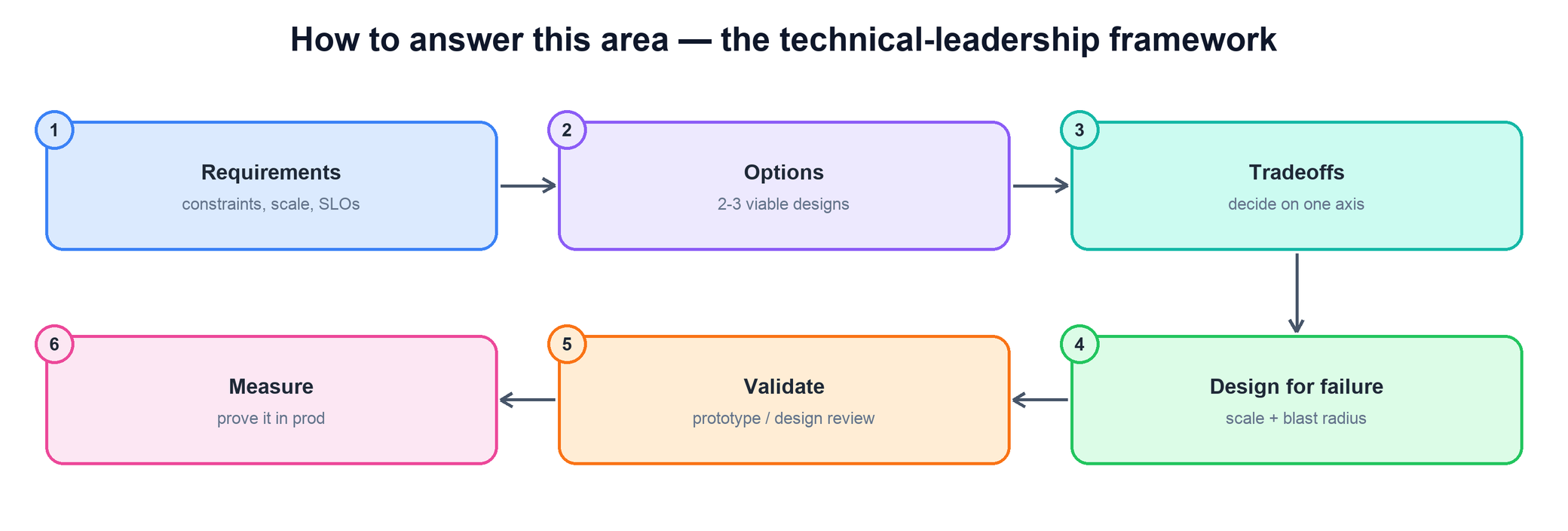
- Requirements first. State the constraints, the scale, and the SLOs before any design. The bar is whether you optimized for the right thing, not the clever thing.
- Lay out real options. Name two or three viable designs, not one design and two strawmen. Show you saw the genuine forks in the road.
- Decide on one axis. Make the tradeoff explicit — latency vs. consistency, cost vs. flexibility — and say which one you optimized and why.
- Design for failure and scale. Talk through what breaks at 10x, what the blast radius is, and how the system degrades rather than collapses.
- Validate, then measure. De-risk with a prototype or a design review before committing, then prove in production that the design moved the number you cared about.
- Requirements and constraints framed before any solution.
- A real alternative considered and rejected for a stated reason.
- One explicit, costly tradeoff — not "it was the best of both."
- Failure thinking: blast radius, degradation, and recovery, not just the happy path.
- "I" for the design calls you made, "we" for how the team built it.
- Design docs / RFCs — pull from the internal wiki for the written requirements, the options you weighed, and the decision you landed.
- Phabricator — pull from the diffs that implemented the design to anchor scope and timeline.
- Scuba / ODS / Unidash — pull the system metrics (latency, throughput, error rate) that prove the design held under load.
- Design-review notes — pull from the architecture-review record for the hard questions raised and how you answered them.
- GSD — pull from the project for the milestones and the outcome the design was meant to deliver.
Walk me through a system you architected. What were the key design decisions?
The flagship question for this area. They want a system you owned at the design level — driven from requirements, narrowed through real alternatives, and proven in production.
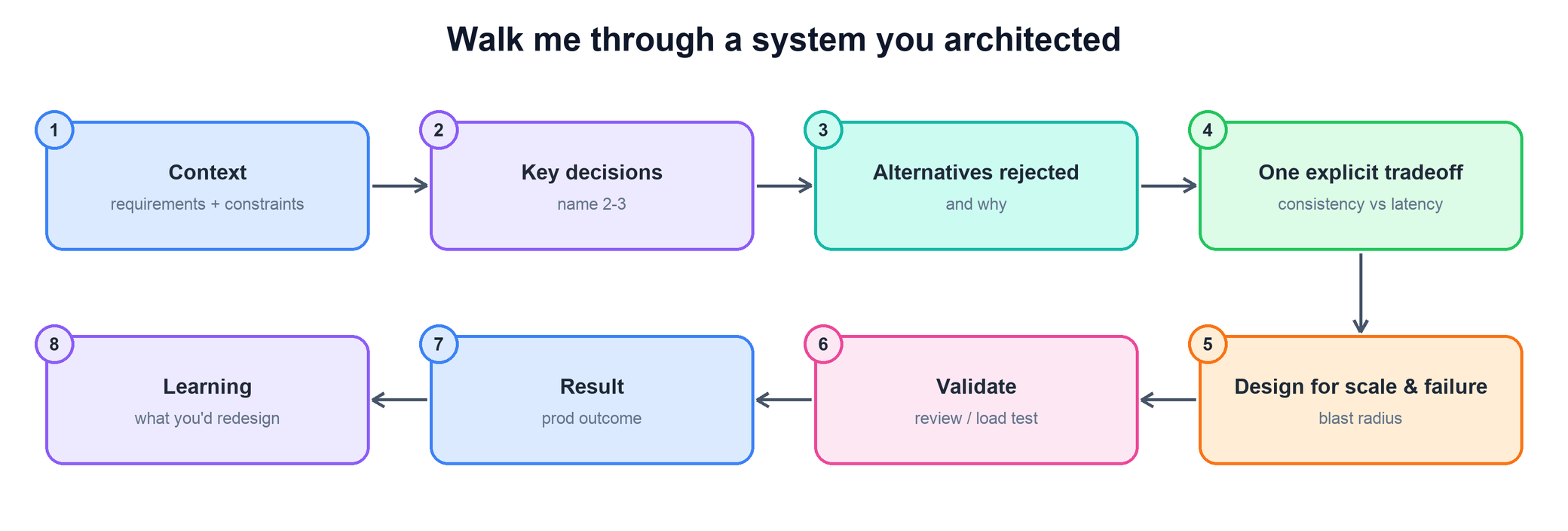
- Open with the requirements and constraints in two sentences: the scale, the SLOs, and what you personally owned in the design.
- Name the two or three key decisions that defined the architecture — the ones the whole design pivoted on.
- State the alternatives you rejected and the concrete reason for each; this is the seniority signal.
- Make one tradeoff explicit (for example consistency vs. latency) and explain how you designed for scale and the failure case — blast radius and degradation.
- Land a production result tied to the opening requirements, and close with what you would redesign with hindsight.
- The design starts from requirements, not from a favorite technology.
- Real alternatives weighed and rejected for stated reasons.
- An explicit tradeoff, owned — not smoothed over.
- Failure and scale thinking, plus a measured production outcome.
- Design doc / RFC — pull from the wiki to quote the decisions and rejected options accurately.
- Scuba / ODS / Unidash — pull the latency, throughput, and error-rate numbers that prove it held in prod.
- Phabricator — pull from the diffs to ground the scope and what you personally drove.
- Design-review notes — pull from the architecture-review record for the questions raised about scale and failure.
Tell me about a difficult technical tradeoff you had to make. How did you decide?
This question tests whether you can name two things that are both genuinely good, choose between them on data, and own what you gave up.
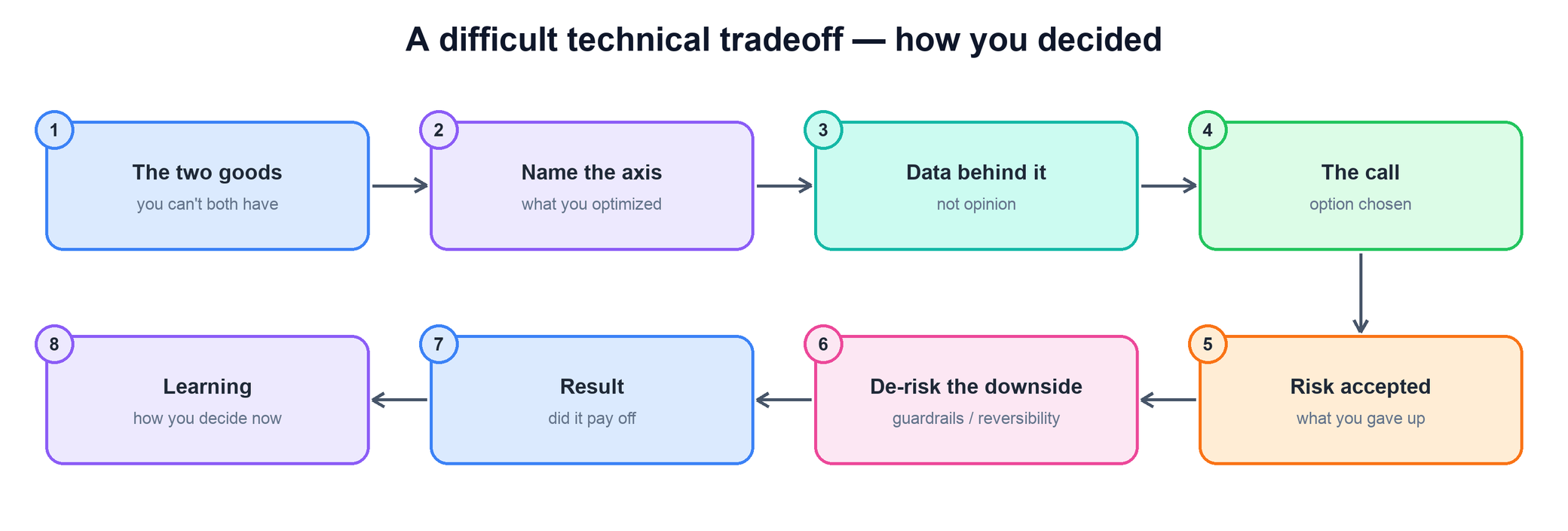
- Frame the two goods you could not have at once — that tension is what made it a real tradeoff.
- Name the axis you optimized and why it was the one that mattered for this system.
- Show the data behind the decision — a benchmark, a cost model, a load test — not opinion.
- State the call you made, the risk you accepted, and how you de-risked the downside with guardrails or a reversible path.
- Close with whether it paid off and the rule of thumb you now use to make this class of decision.
- A genuine tradeoff — two good options, not one obvious one.
- A decision axis made explicit, decided on evidence.
- Ownership of the cost: what you knowingly gave up.
- Risk mitigation and reversibility built into the call.
- Design doc / RFC — pull from the wiki for the written options and the rationale for the axis you chose.
- Scuba / ODS / Unidash or a prototype's numbers — pull the benchmark or load-test data that settled it.
- Design-review notes — pull from the review record where the tradeoff was debated.
- Phabricator — pull from the diffs if the de-risking showed up as guardrails or a feature flag.
As a manager, how do you stay technical — and what do you do when you disagree with your team's technical direction?
The signal here is earned technical authority: staying close enough to the work to have a real opinion, going deep selectively, and resolving disagreement on reasoning rather than rank.
- Describe how you stay close to the work — design reviews, reading diffs, taking oncall — so your opinion is grounded.
- Explain that you go deep selectively on the highest-leverage decisions and trust the DRI on the rest.
- When you disagree, get the data first: a prototype or a benchmark beats an argument from authority.
- Then decide or defer — if you are still not convinced you make the call, but you disagree and commit when the team has the better evidence.
- Stress that you earn the call on reasoning, not title, and you follow up to verify the outcome either way.
- Concrete habits that keep you technically current as a manager.
- Selective depth — not micromanaging every decision.
- Disagreement resolved on data and reasoning, not seniority.
- Genuine disagree-and-commit, with follow-through to verify.
- Phabricator — pull from diffs you reviewed or authored to show you stay close to the code.
- Design-review notes — pull from the review record for a decision you shaped or deferred on.
- Design doc / RFC — pull from the wiki for a direction debate where you committed after losing the argument.
- Scuba / ODS / Unidash — pull the metric you used to verify the outcome after the decision.
Tell me about a build-vs-buy decision you made. How did you decide, and how did you keep it from locking you in?
This question tests whether you can tell core from commodity, decide on a rubric rather than a preference, and protect the team's future optionality.
- State the need and constraints — what the system actually had to do and by when.
- Ask the key question: is this core? Differentiating work is worth building; commodity work usually is not.
- Decide on an explicit rubric — total cost of ownership, time to value, and lock-in risk — not a gut preference.
- State the decision (build, buy, or adopt an internal platform) and, critically, how you designed to avoid lock-in: an abstraction layer and a credible exit plan.
- Close with the time or cost outcome and the triggers that would make you revisit the choice.
- A clear core-vs-commodity judgment, not "build everything."
- A decision rubric, including total cost of ownership over time.
- Lock-in addressed deliberately — abstraction and an exit path.
- Awareness of when the decision should be revisited.
- Design doc / RFC — pull from the wiki for the written build-vs-buy rubric and the rationale.
- GSD — pull from the project for the time-to-value and the cost the decision saved or spent.
- Code search — pull from the codebase to show the abstraction layer that contained the lock-in.
- Unidash / ODS — pull the cost or utilization numbers behind the total-cost-of-ownership case.
Tell me about a large migration or re-architecture you led.
A perseverance-and-design question. They want a high-risk change driven incrementally, with the lights kept on and a safe path back at every step.
- Open with the forcing function — why migrate at all, and why now — so the risk is justified.
- Map the surface: the dependencies, the callers, and the highest-risk parts you had to handle first.
- Lay out the incremental plan — strangler pattern, dual-write, or phased cutover — never a big-bang switch.
- Show how you kept the lights on and validated parity with shadow traffic or a backfill before trusting the new path.
- Describe the reversible cut-over and close with the old system retired and the reliability or cost outcome.
- A clear forcing function — migration as a means, not an end.
- Incremental, reversible execution instead of a risky big-bang.
- Parity validation before cut-over — shadow, backfill, or dual-write.
- The old system actually decommissioned, with a measured result.
- Design doc / RFC — pull from the wiki for the migration plan and the rollback strategy.
- GSD — pull from the project for the milestone history and the cut-over dates.
- Phabricator — pull from the diffs that staged the dual-write and the cut-over.
- Scuba / ODS / Unidash — pull the parity and reliability metrics that proved the new path matched the old.
How do you raise the technical bar and run design reviews?
This question tests whether you can scale your own judgment across a team — setting a standard, teaching through review, and making the result show up in fewer incidents.
- Set the standard: make explicit what "good" looks like — clear requirements, considered alternatives, and a failure plan.
- Run design reviews early, on written RFCs, before the code is written and the decision is expensive to change.
- Ask the hard questions — failure modes, scale at 10x, the blast radius — consistently, so people start asking them of themselves.
- Mentor through the review: teach the reasoning rather than gatekeep, so the bar rises by raising people, not by blocking them.
- Make decisions durable by writing them down, and measure the bar over time — fewer SEVs, fewer reworks, better designs landing.
- An explicit, communicated standard — not "I just know good design."
- Reviews used to teach, not to gatekeep.
- Hard questions asked early, when changes are cheap.
- A measurable improvement in the bar over time.
- Design-review notes — pull from the review records that show the questions you consistently raised.
- Design docs / RFCs — pull from the wiki for the template or standard you set for the team.
- Phabricator — pull from review comments to show mentoring through the work.
- Scuba / ODS / Unidash — pull the SEV or incident-rate trend that shows the bar moved.
More questions you might get — Technical Design
All of these reduce to the same spine: start from requirements, weigh real options, decide on one explicit axis, design for scale and failure, and prove it in prod. Have a story ready for each.
How do you design a system when the requirements are still ambiguous or changing?
How to answer- Pin the invariants. Find the few constraints that won't change — the data model, the SLOs — and design those first.
- Defer the reversible. Keep the volatile decisions behind interfaces so a requirement change is a swap, not a rewrite.
- Build to learn. Ship a thin slice to turn the ambiguity into data, then let real usage tighten the spec.
- Name the cost of being wrong. Invest design effort where a wrong guess is expensive; stay cheap and flexible everywhere else.
Tell me about a design decision you got wrong. How did you find out, and what did you do?
How to answer- Own the call. State the decision and the assumption behind it that turned out to be false — no hedging.
- Show the signal. Say how you found out: a metric, an incident, a scaling wall — and that you were watching for it.
- Act, don't sunk-cost. Describe the correction and how you contained blast radius while you fixed it.
- Bank the learning. Close with the rule or guardrail you adopted so this class of mistake can't recur.
How do you choose between consistency and availability for a given system?
How to answer- Start from the business cost. Decide what a stale read or a rejected write actually costs the user — that, not theory, picks the axis.
- Go per-operation. Don't pick one for the whole system; money paths want consistency, feeds tolerate staleness.
- Name the partition behavior. Say explicitly what the system does when the network splits — reject, or serve stale and reconcile.
- Make the weaker side safe. Bound staleness or add idempotency and reconciliation so the relaxed guarantee stays correct enough.
Walk me through how you'd design for 10x the current scale.
How to answer- Find the first bottleneck. Name the component that breaks first at 10x — usually a hot shard, a single writer, or a queue — and design from there.
- Scale horizontally. Show how you partition state and remove single points so capacity grows by adding nodes, not bigger ones.
- Shed load gracefully. Add caching, backpressure, and admission limits so the system degrades instead of collapsing past capacity.
- Validate the model. Back the plan with a load test or a capacity model, not a hunch, and re-check at each multiple.
How do you manage and pay down technical debt without stalling delivery?
How to answer- Make it visible. Track debt explicitly and tie each item to the velocity or risk cost it imposes — not "the code is ugly."
- Pay down the high-interest first. Target the debt that slows the most work or threatens reliability, not the most annoying.
- Bundle with feature work. Refactor along the path of changes you're already making so cleanup ships value, not just risk.
- Stop the bleeding. Set a standard that new code clears the bar, so the debt stops compounding while you pay it down.
Tell me about a time you had to simplify an over-engineered design.
How to answer- Name the over-build. Point to the speculative flexibility or premature abstraction that wasn't earning its complexity cost.
- Tie complexity to pain. Connect it to a real cost — slow onboarding, more bugs, harder ops — to justify the cut.
- Cut deliberately. Describe collapsing layers or removing config back to the actual requirements, with tests guarding behavior.
- Show the payoff. Close with the result: less code, fewer failure modes, faster changes — and the YAGNI rule you now apply.
How do you evaluate a new technology before betting a system on it?
How to answer- Start from the requirement. Evaluate against the problem you actually have, not the technology's hype or your curiosity.
- Prototype the risky part. Spike the hardest use case and the failure modes early — benchmark, don't trust the marketing.
- Weigh the total cost. Score operability, maturity, community, and lock-in, not just the happy-path feature fit.
- Limit the blast radius. Adopt behind an abstraction with a fallback, so a bad bet is contained and reversible.