06 · Code Review
How to answer the code-review questions in a senior engineering-leadership loop: the framework to structure each answer, what the interviewer is really listening for, and where inside Meta to pull the evidence that backs your story.
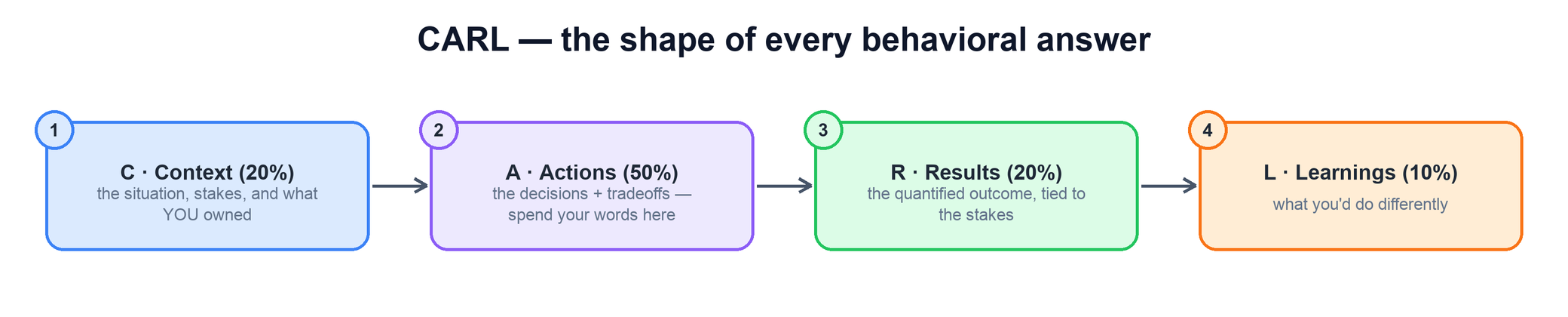
This area tests one thing: can you use code review as a leadership lever — to protect quality and reliability, grow the engineers who write the code, and keep the team fast without turning yourself into a bottleneck or a gatekeeper. Interviewers are not grading whether you know that reviews catch bugs; they assume that. They are grading judgment: do you review for the things that matter, hold a bar without slowing everyone down, give feedback that lands, and turn an escaped defect into a systemic guardrail instead of a scolding. Every answer below is built on the CARL shape — Context, Actions, Results, Learnings — with most of your words spent on the calls and tradeoffs only you could have made.
Questions on this page
- How to answer this area — the framework
- What is code review actually for?
- Raising the code-quality bar on a team
- Keeping code review fast without lowering the bar
- Giving difficult review feedback — and resolving conflict
- A bug slipped through review — what you changed
- Scaling code review as the team grows
- More questions you might get
- How do you review code in an area you're not an expert in?
- How do you handle a senior engineer who resists review feedback — or who over-nitpicks others?
- How do you onboard a new engineer to your team's review standards?
- What's your policy on blocking vs non-blocking (nit) comments?
- How do you balance automated checks (CI, static analysis) against human review?
- As a manager, how do you stay in reviews without becoming the bottleneck?
- How do you think about AI-assisted code review?
How to answer this area — the code-review leadership framework
Every code-review question can be answered with the same six-step spine. Treat review as a system you design and run, not a chore you perform, and you will hit the signals interviewers look for without sliding into a debate about tabs versus spaces.
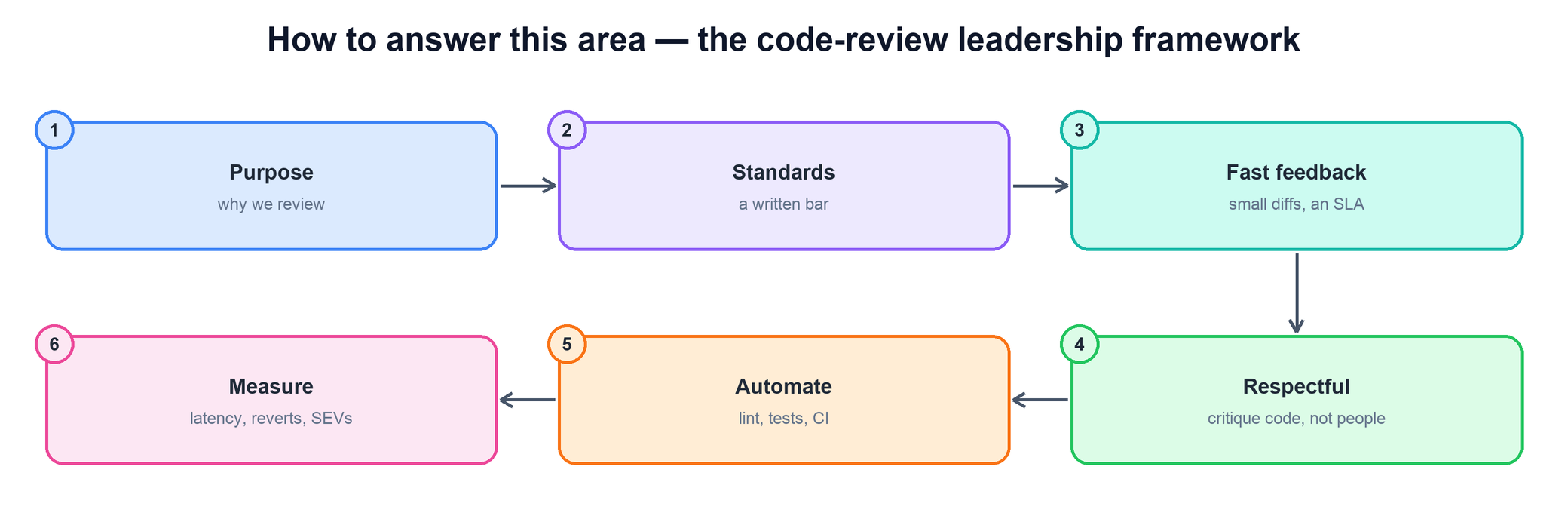
- Purpose first. Review exists to check correctness, design, and shared context — not to hunt for nitpicks. Say what review is for before you say how you run it.
- A written, shared standard. Make explicit what a review actually checks, and what is blocking versus a non-blocking "nit," so the bar is a team property and not one reviewer's mood.
- Fast feedback. Push for small, atomic diffs and a review-latency SLA so that holding a bar never means blocking the team's flow.
- Respectful feedback. Critique the code, not the person; ask questions rather than issue commands; and always explain the why so the author learns, not just complies.
- Automate the mechanical. Push formatting, lint, tests, CI, and static analysis into the pipeline so humans spend their attention on design and correctness.
- Measure and iterate. Watch review latency, revert and SEV rate, and coverage, and tune the process against those numbers rather than against opinion.
- A clear point of view on what review is for — correctness and design over style.
- A bar that lives in writing and tooling, not just in your head.
- Speed and quality treated as a joint constraint, not a trade you shrug at.
- Feedback framed as teaching, with the human relationship protected.
- "I" for the standard and calls you set, "we" for how the team runs the practice.
- Phabricator — pull from diffs and review comments to show the standard you held and the feedback you gave in practice.
- Review-latency dashboards (Scuba / ODS / Unidash) — pull the time-to-first-review and time-to-land numbers that show flow stayed fast.
- SEV / incident records — pull the revert and SEV trend that shows the bar was actually protecting reliability.
- The internal wiki — pull from the written review guidelines or checklist you set for the team.
- GSD — pull from the project for the quality or velocity goal the review practice was meant to move.
How do you think about code review on your team — what is it actually for?
The philosophy question for this area. They want your operating principle, then proof you live by it. The trap is answering "to catch bugs" and stopping — that's the junior answer.
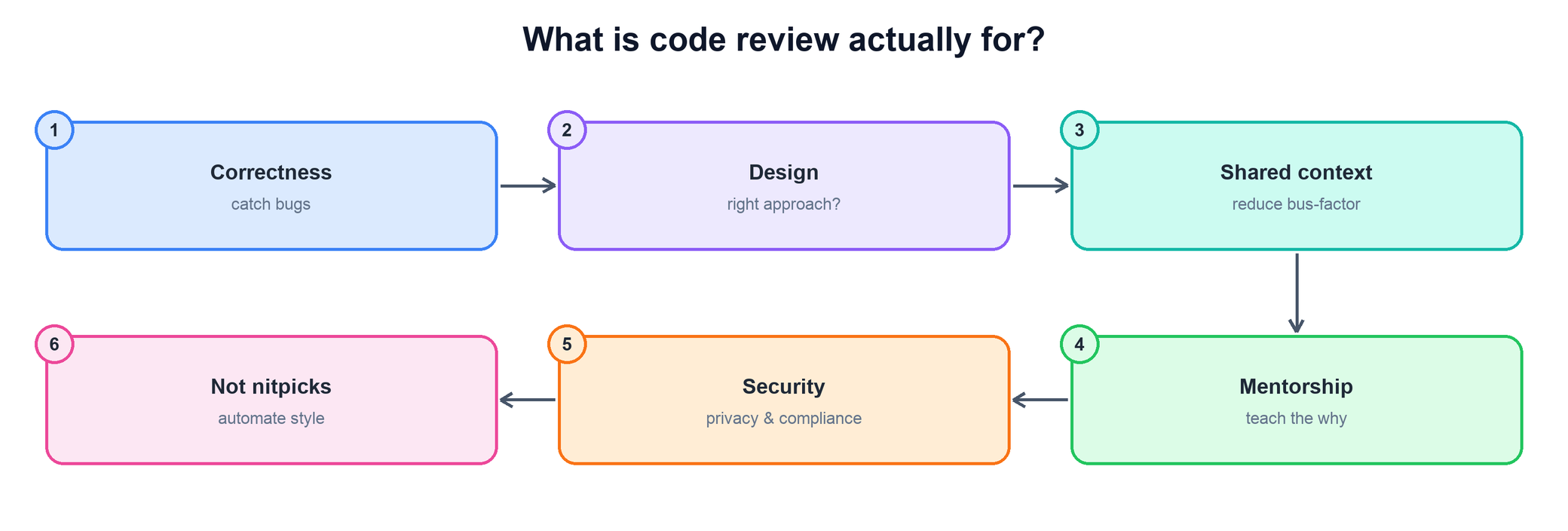
- Lead with correctness: a second set of eyes catches the logic bug, the edge case, and the missing test before it reaches production.
- Elevate to design and approach: the most valuable review question is often "is this the right way to solve this at all," not "is this line correct."
- Name shared context: review spreads knowledge of the codebase across the team and reduces bus-factor, so no single person is the only one who understands a system.
- Call out mentorship: review is your highest-frequency teaching moment — explaining the why is how junior engineers grow into the bar.
- Don't skip security, privacy, and compliance: some classes of risk are exactly what a human reviewer is there to catch. And make the closing point that style should be automated away, not argued — if two people are debating formatting, the linter has failed, not the author.
- A layered answer — correctness and design, context, mentorship, security.
- Review framed as a growth and knowledge-sharing lever, not just a gate.
- A clear instinct to automate style away so humans review substance.
- An operating principle you can then back with a concrete example.
- Phabricator — pull from review comments where you raised a design question or caught a correctness bug, not just a nit.
- The internal wiki — pull from the review guidelines that encode this purpose for the team.
- SEV / incident records — pull an example of a class of bug review is meant to stop.
- Code search — pull from the codebase to show where review spread ownership of a system beyond one author.
Tell me about raising the code-quality bar on a team.
A CARL question. They want a team that was shipping below the bar, a standard you set and made visible, and a measurable drop in reverts or incidents — achieved by raising people, not by blocking them.
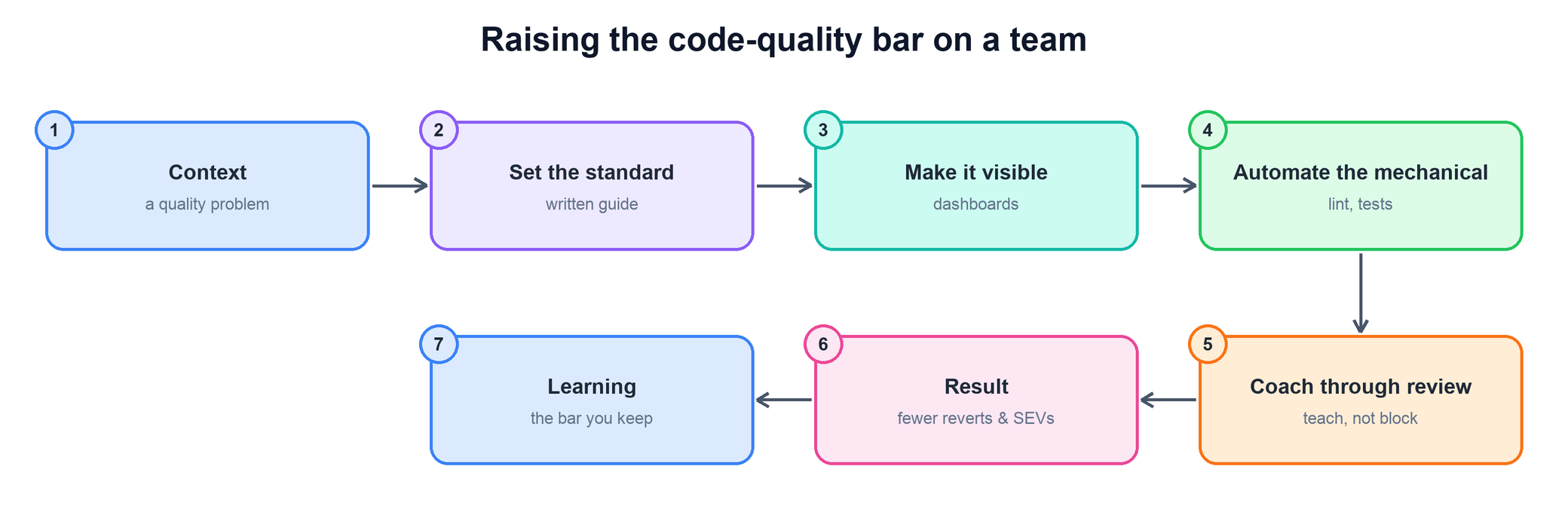
- Open with the context: the quality problem you saw — frequent reverts, flaky tests, inconsistent designs, or an incident that traced back to thin review.
- Set an explicit written standard: publish what "good" means — tests required, design considered, checks green — so the bar is shared, not implicit.
- Make quality visible: put revert rate, test coverage, and review latency on a dashboard so the team can see the bar and its own trend against it.
- Automate the mechanical and coach through review: let CI enforce style and tests, and use your review comments to teach the reasoning rather than to block — the bar rises because people rise.
- Land a result tied to the opening problem — fewer reverts and SEVs — and close with the learning: the standard you now keep and how you keep it from eroding.
- A standard that is explicit and written, not "I just have high standards."
- Quality made visible and measured, not asserted.
- The bar raised by teaching and tooling, not by gatekeeping.
- A measured outcome — reverts or SEVs down — plus a durable habit.
- The internal wiki — pull from the written standard or checklist you published for the team.
- SEV / incident records — pull the revert and SEV-rate trend before and after you raised the bar.
- Review-latency dashboards (Scuba / ODS / Unidash) — pull the coverage and latency numbers you made visible.
- Phabricator — pull from review comments that show you coached rather than gatekept.
How do you keep code review fast without lowering the bar?
This is the core tension of the area: speed versus rigor. The senior answer refuses the trade and attacks both at once — smaller units of work, an SLA, and automation that moves the bar into the pipeline.
- Start with small, atomic diffs: the single biggest lever on review speed and quality is size — a reviewable diff gets a real review fast; a giant one gets a rubber stamp.
- Set a review SLA — roughly one business day to first response — so authors aren't blocked and reviewing doesn't slip behind "real work."
- Automate the gates: formatting, lint, tests, and static analysis run in CI, so humans never spend a review cycle on something a machine should catch.
- Make reviewing a first-class priority, not the thing you do when idle — and default to async, with a sync escalation (a quick call or pairing) the moment a thread stalls or a design disagreement loops.
- Close with the result: latency down while the bar held — ideally with the revert or SEV rate flat or better to prove you didn't buy speed with quality.
- Refusal to treat speed and quality as a straight trade.
- Diff size named as the primary lever — the seniority tell.
- An SLA and a norm that reviewing is real, prioritized work.
- A result showing latency improved with the bar intact.
- Review-latency dashboards (Scuba / ODS / Unidash) — pull the time-to-first-review and time-to-land trend that shows flow got faster.
- Phabricator — pull from diffs to show the shift toward smaller, atomic changes.
- SEV / incident records — pull the revert or SEV rate to prove the bar held while speed improved.
- The internal wiki — pull from the written SLA or review norms you set.
Tell me about giving difficult review feedback, or resolving a code-review conflict.
An interpersonal question wearing a technical hat. They want to see you deliver a hard critique that lands, and resolve a stalemate, without damaging the working relationship.
- Critique the code, not the person: keep every comment about the change itself — "this path can deadlock," never "you always miss locking."
- Ask, don't command: framing a concern as a question ("what happens if this retries?") invites the author to reason rather than to defend, and often surfaces context you lacked.
- Explain the why: give the reasoning behind the ask, not just the verdict — feedback backed by a principle teaches; feedback backed by taste breeds resentment.
- Label nits versus blocking clearly so the author knows what must change to land and what is optional — and if you're genuinely stuck, escalate to the code owner or tech lead for a tiebreak rather than letting the diff rot.
- Close on disagree-and-commit: once the call is made, get behind it fully — and make the point that the relationship stayed intact, because trust is what makes the next hard review possible.
- Feedback aimed at the code, framed as questions, backed by reasons.
- Clear signal on what blocks the land versus what's optional.
- A path out of stalemate — escalation to an owner, not a war of attrition.
- Genuine disagree-and-commit with the relationship preserved.
- Phabricator — pull from the review thread where you delivered the hard feedback or resolved the conflict.
- The internal wiki — pull from the code-review etiquette or nit-labeling convention you followed or set.
- Design-review notes — pull from the record if the disagreement escalated to a design or owner decision.
- GSD — pull from the project if the resolution unblocked a milestone.
A bug or incident slipped through review — what did you change?
A systems-thinking question. They want to see you grade the process, not the reviewer, and turn one escaped defect into a guardrail so the whole class can't recur.
- State the miss plainly — what shipped, what broke — without softening it.
- Set a blameless frame immediately: the question is why the system let this through, not which reviewer to blame. A bug that a human was expected to eyeball-catch is a process gap, not a character flaw.
- Root-cause why review missed it: was the diff too large to review well, the risk invisible, the test missing, the reviewer lacking context in that area?
- Apply a systemic fix matched to the root cause — a new automated check or lint rule, a required test, a checklist item, or a code-owner requirement for that path — so a machine or a rule catches it next time, not vigilance.
- Close with the result (the class hasn't recurred) and the learning — the guardrail you added and the instinct to fix the system, not scold the person.
- A blameless reflex — grade the process, not the reviewer.
- A real root cause, not "we'll be more careful."
- A systemic, durable fix — a check, test, or checklist — over exhortation.
- Evidence the class of bug actually stopped recurring.
- SEV / incident records — pull from the postmortem for the root cause and the review gap it identified.
- Phabricator — pull from the diff that introduced the bug and the diff that added the guardrail.
- The internal wiki — pull from the checklist or review-standard update that came out of it.
- Review-latency dashboards (Scuba / ODS / Unidash) — pull the recurrence rate showing the class dropped after the fix.
How do you scale code review as the team and codebase grow?
A leverage question. As headcount and surface area grow, a review process that leaned on a few heroes collapses. They want a system with clear ownership, a broad reviewer pool, and the mechanical work automated.
- Establish clear ownership: code-owners rules route each diff to people accountable for that surface, so reviews land with the right eyes automatically.
- Grow the reviewer pool: deliberately spread review capability beyond a few seniors — pair newer reviewers with experienced ones — so review load scales with the team and doesn't concentrate on heroes.
- Lean on written guidelines so the bar is one shared standard across many reviewers, not N inconsistent personal bars.
- Automate the mechanical hard — the larger the team, the more expensive it is to have humans argue style — and onboard new engineers to the bar explicitly so growth doesn't dilute quality.
- Close on measure and tune: track review latency and quality as you scale, and adjust ownership, pool size, and automation against the numbers.
- Ownership routed by code-owners, not tribal knowledge.
- A widened reviewer pool — no dependence on a couple of heroes.
- One written bar plus automation holding quality constant as headcount grows.
- Onboarding to the bar and measurement to keep the system honest.
- Code search — pull from the code-owners configuration that routes reviews by ownership.
- Review-latency dashboards (Scuba / ODS / Unidash) — pull the latency and reviewer-distribution trend as the team grew.
- The internal wiki — pull from the written guidelines and onboarding docs for the review bar.
- Phabricator — pull from review data showing load spread across a wider pool rather than concentrating.
More questions you might get — Code Review
All of these reduce to the same spine: review for correctness and design over style, hold a written bar, keep feedback fast and respectful, automate the mechanical, and turn misses into guardrails. Have a story ready for each.
How do you review code in an area you're not an expert in?
How to answer- Review what you can judge. You can always assess clarity, tests, error handling, interfaces, and whether the change matches its stated intent — even without domain depth.
- Ask, don't approve blindly. Turn your gaps into genuine questions; a good "why this way?" often surfaces a real issue and teaches you the area.
- Pull in an owner. For the parts that need domain expertise, route to a code-owner rather than rubber-stamping — scaling review means knowing when you're not the right reviewer.
- Learn from it. Treat unfamiliar reviews as a way to spread context and reduce bus-factor, which is one of review's real purposes.
How do you handle a senior engineer who resists review feedback — or who over-nitpicks others?
How to answer- Anchor on the shared standard. Bring the conversation back to the written bar so it's not your opinion versus theirs — the standard is the arbiter.
- Separate blocking from taste. For a resister, make clear which comments actually block a land and why; for an over-nitpicker, ask them to label true nits as optional and let authors decide.
- Address it directly, in private. Handle a persistent pattern in a 1:1, not in the review thread — frame it around team velocity and morale, with concrete examples.
- Redirect senior energy. Point strong reviewers at design and correctness where their judgment adds the most, and let automation own the style they're tempted to fight over.
How do you onboard a new engineer to your team's review standards?
How to answer- Point at the written bar. Start them on the review guidelines and checklist so expectations are explicit from day one, not absorbed by osmosis.
- Have them shadow reviews. Let them read strong exemplar diffs and follow along on reviews before they own them, so they see the bar applied.
- Pair on their first diffs. Give thorough, teaching-oriented feedback on their early changes — explaining the why — so they internalize the standard quickly.
- Bring them into reviewing early. Have them review alongside an experienced reviewer to grow the pool and to cement the bar by teaching it.
What's your policy on blocking vs non-blocking (nit) comments?
How to answer- Block only correctness, design, and risk. A comment blocks a land when it's about a bug, a design flaw, a security or reliability concern — the things review exists for.
- Label everything else "nit." Preferences and polish are explicitly optional, and the author decides whether to take them — this keeps flow fast and lowers friction.
- Automate the recurring nits away. If the same style nit keeps appearing, it belongs in a linter, not in a human comment — a repeated nit is a tooling gap.
- Make the convention team-wide. A shared nit-labeling norm means authors always know what must change to land, which is a big lever on both speed and goodwill.
How do you balance automated checks (CI, static analysis) against human review?
How to answer- Machines own the mechanical. Formatting, lint, type checks, tests, and known anti-patterns belong in CI and static analysis — they're faster, consistent, and never tire.
- Humans own judgment. Design, correctness of intent, readability, and security tradeoffs need a person — automation frees that attention rather than replacing it.
- Make green a precondition. Checks should pass before human review starts, so reviewers never burn a cycle on something a gate should have caught.
- Feed misses back into tooling. When review keeps catching the same class of issue, encode it as a check so the human bar keeps rising to new problems.
As a manager, how do you stay in reviews without becoming the bottleneck?
How to answer- Review selectively. Weigh in on high-leverage or high-risk diffs and design-level changes; trust code-owners and the team on the routine.
- Grow reviewers, don't hoard reviews. Your job is to build a pool that can hold the bar without you — measure success by the team's independence, not your queue depth.
- Set the standard, then let it run. A written bar and good automation let the team self-serve quality, so being out for a week doesn't stall anyone.
- Watch your own latency. If diffs are waiting on you, that's a signal to delegate ownership, not to work later — a manager who blocks flow is failing the team.
How do you think about AI-assisted code review?
How to answer- Great for the mechanical layer. AI is a strong first pass on obvious bugs, missing tests, style, and boilerplate feedback — the same tier you'd want automated anyway.
- Not a replacement for judgment. It doesn't own design intent, business context, or accountability; a human still signs off on correctness and security.
- Use it to speed humans, not skip them. Let it triage and pre-comment so reviewers focus their attention on the hard, contextual calls — a lever on latency, not a lowering of the bar.
- Verify, don't trust blindly. Treat its suggestions as input to be validated; keep a human owner responsible for what lands, and watch for confident-but-wrong feedback.