Apache Kafka — Internal Architecture
A developer's guide to how Kafka actually works under the hood: the distributed commit log, brokers and partitions, on-disk segments, replication and the in-sync replica set, and how records flow from producer to consumer.
Apache Kafka is a distributed, durable, append-only commit log built for high throughput and strict per-partition ordering. It is not a queue in the traditional sense and not a database — it is a replicated log that producers append to and consumers read from at their own pace. Almost every design decision follows from one core abstraction: the partition is an ordered, immutable sequence of records identified by monotonically increasing offsets. Understanding Kafka means understanding how that log is partitioned across brokers, persisted on disk, replicated for durability, and consumed in parallel.
Contents
1. Design Goals and Core Ideas
Every internal decision in Kafka traces back to a small set of goals. Keeping them in mind makes the rest of the architecture predictable.
| Goal | How Kafka achieves it |
|---|---|
| Durability | Records are appended to an on-disk log and replicated to multiple brokers before being acknowledged. Nothing lives only in memory. |
| Strict ordering | Within a single partition, records are stored and delivered in the exact order they were appended. Offsets never go backwards. |
| High throughput | Sequential disk writes, batching, compression, the OS page cache, and zero-copy reads. Disk is treated as a fast sequential medium, not random-access storage. |
| Horizontal scalability | A topic is split into partitions spread across brokers. Partitions are the unit of both parallelism and ordering. |
| Replay & multiple readers | Reading does not consume. The log is retained; each consumer tracks its own offset, so many independent readers can re-read the same data. |
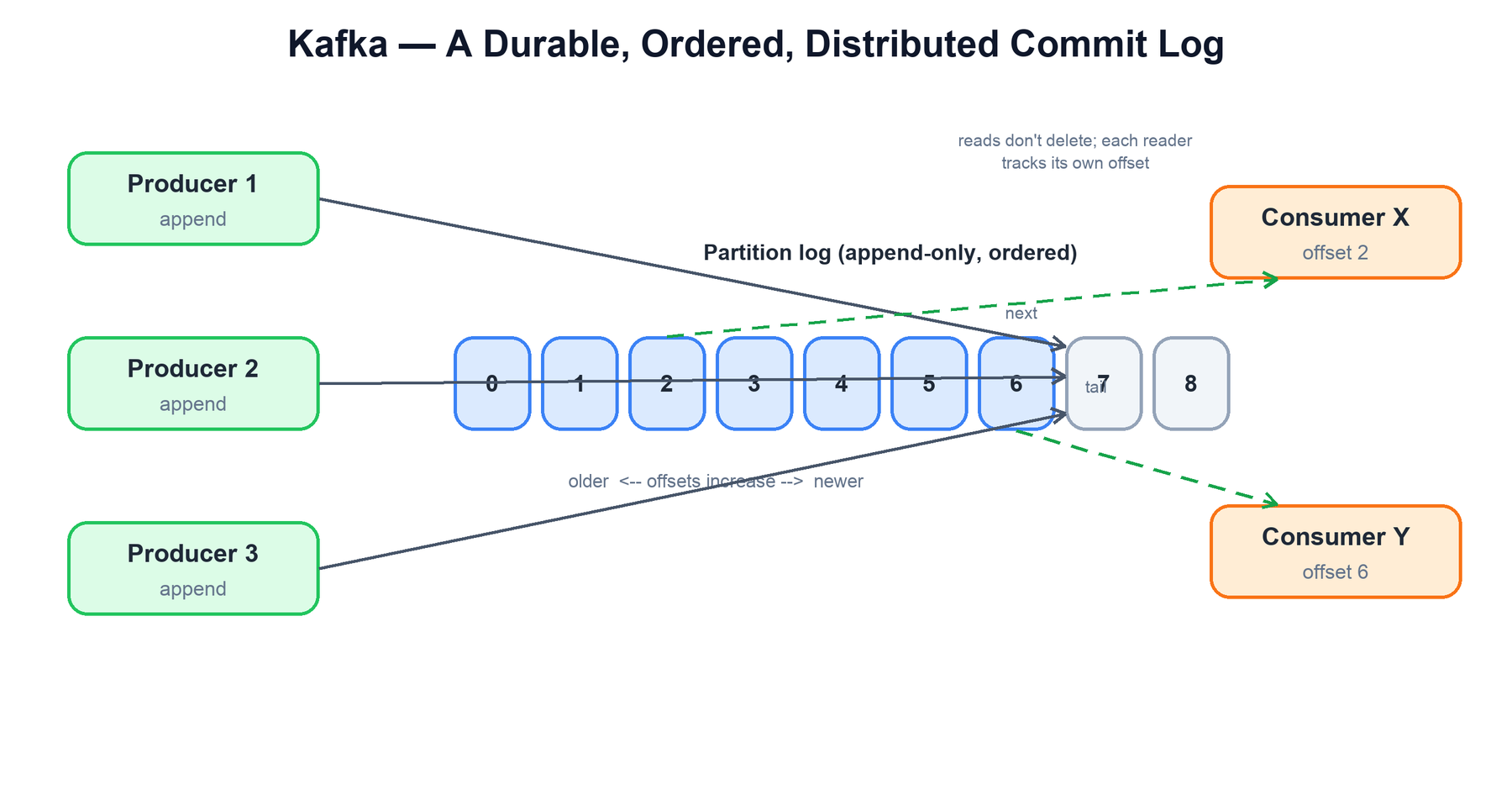
The single most important mental model is the log itself: an append-only, ordered file where each record gets the next integer offset. Producers only ever write to the tail. Consumers read forward from a position they control. Because a read is just "give me records starting at offset N," the same record can be delivered to many consumers, re-read after a failure, or reprocessed days later — as long as it is still within the retention window.
2. Cluster Architecture
A Kafka cluster is a set of brokers — servers that store partition data and serve produce and fetch requests. Unlike a fully peer-to-peer system, Kafka has explicit roles: one broker is the leader for a given partition while others are followers, and a small controller quorum manages cluster metadata and leader assignment.
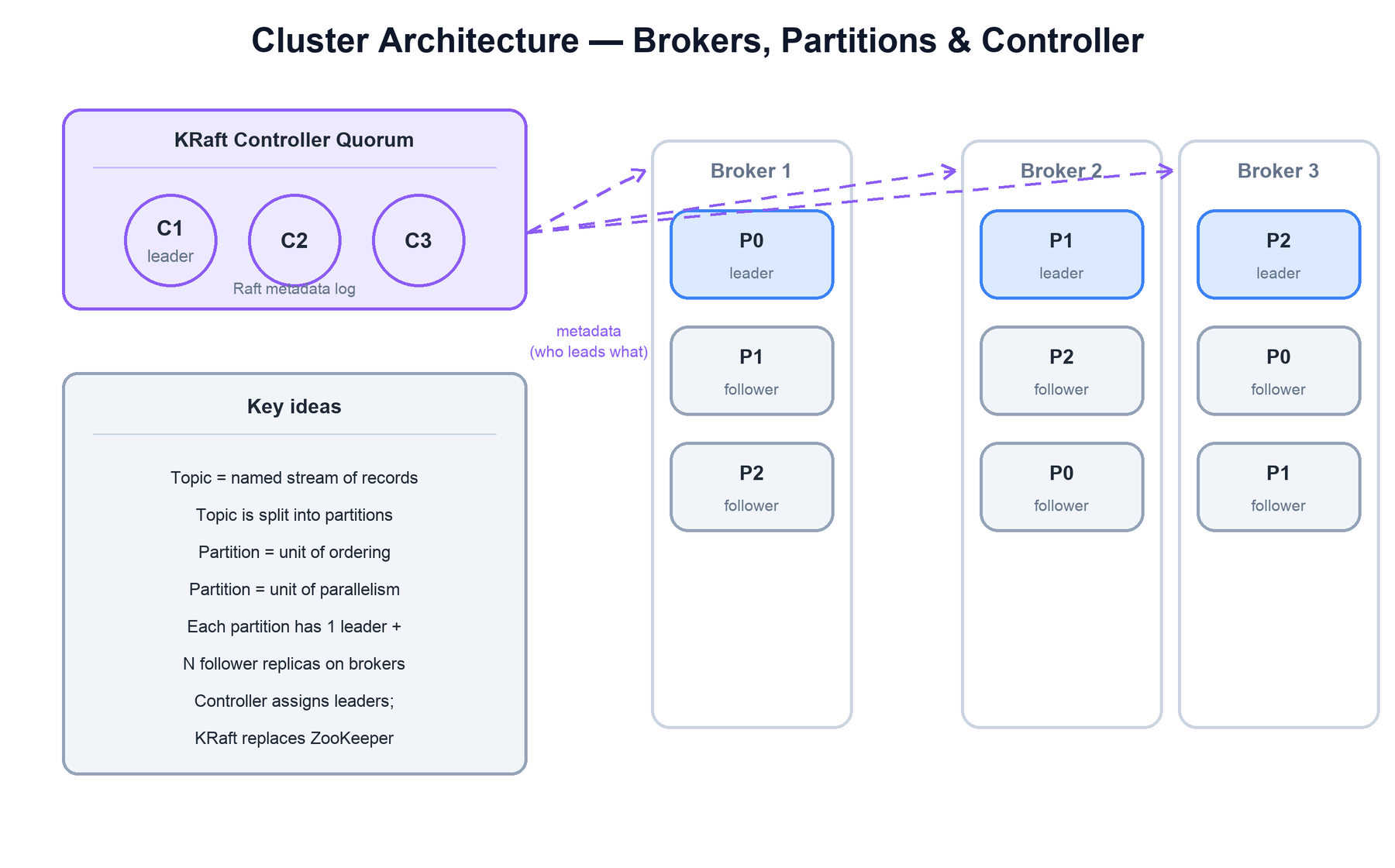
The key components are:
- Topic: a named stream of records. It is a logical category, not a physical thing — the physical units are its partitions.
- Partition: the fundamental unit. Each partition is an independent ordered log. A topic with 12 partitions can be read by up to 12 consumers in a group in parallel, and ordering is guaranteed only within each partition, never across partitions.
- Broker: a server that hosts a subset of partition replicas, persists them to disk, and handles client requests for the partitions it leads.
- Controller: the component responsible for cluster metadata — which broker leads which partition, which replicas are in sync, and how to react when a broker dies. It elects new partition leaders when a leader fails.
KRaft vs legacy ZooKeeper
Historically Kafka stored all cluster metadata (broker membership, topic configs, partition leadership, ISR state) in an external ZooKeeper ensemble, and a single elected controller broker watched ZooKeeper for changes. That added an operational dependency and made metadata changes a bottleneck at large partition counts.
Modern Kafka uses KRaft (Kafka Raft), which removes ZooKeeper entirely. A dedicated set of controller nodes runs a Raft consensus quorum and stores all metadata in an internal, replicated metadata log — the controllers literally use a Kafka-style log to record metadata changes. Brokers subscribe to that metadata log and apply updates as events. The result is faster failover, far higher partition scalability, and one fewer system to operate.
3. The Log on Disk
Each partition replica on a broker is a directory on disk. The log is not one giant file — it is split into segments, and each segment is accompanied by sparse index files that make random lookups by offset or timestamp cheap.
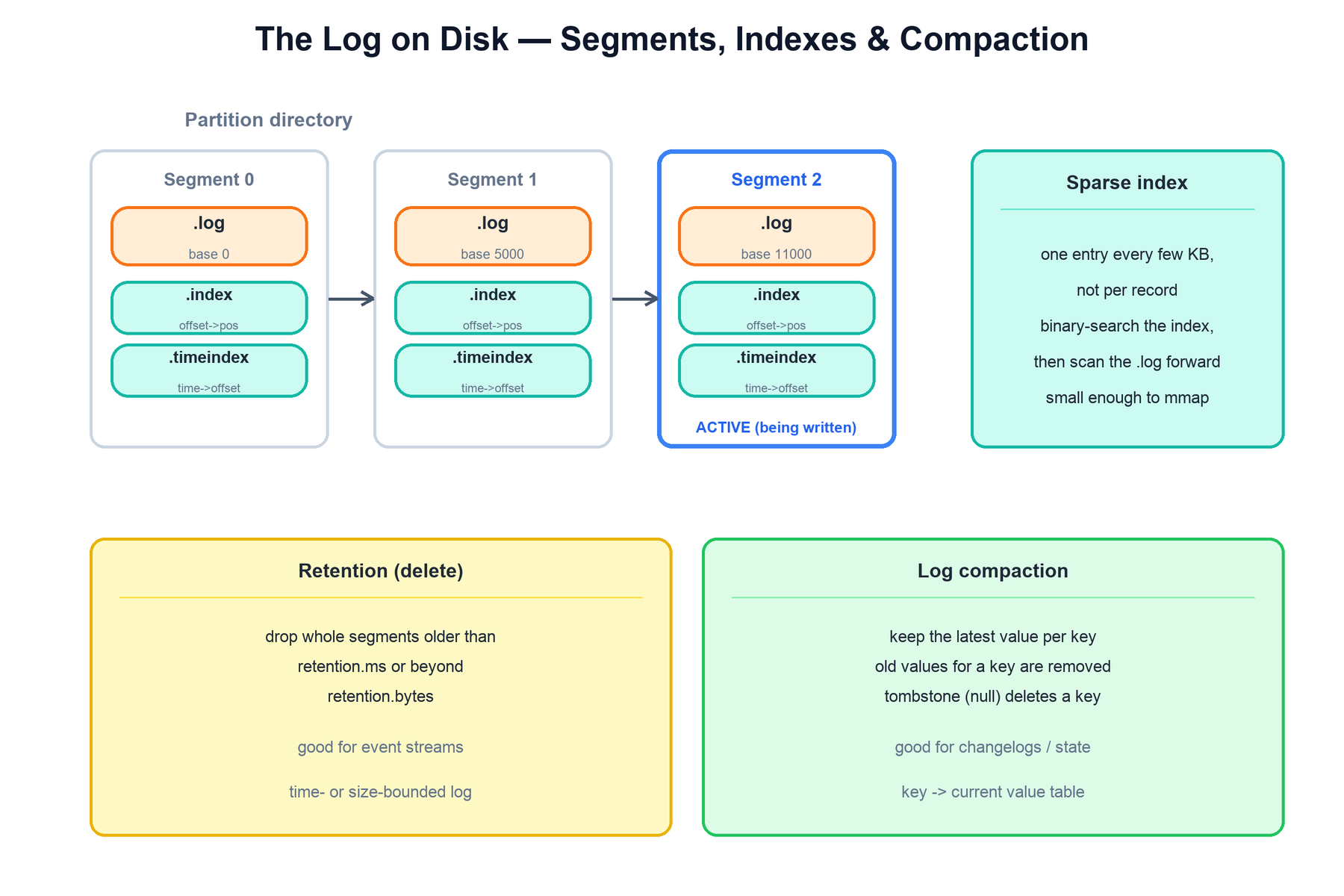
.log plus sparse .index and .timeindex files. Old data is reclaimed by retention (delete) or compaction (keep latest per key).The on-disk structures are:
- Segment
.logfile: the actual records, appended sequentially. The file name is the base offset of the first record it contains. Only the newest segment — the active segment — is written to; older segments are immutable, which makes them safe to read, cache, and delete wholesale. .index(offset index): a sparse map from a relative offset to a byte position in the.logfile. It holds one entry every few kilobytes of data, not one per record. To find offset N, Kafka binary-searches the index for the closest preceding entry, seeks to that byte position, then scans forward in the log. Because it is sparse it is tiny and can be memory-mapped..timeindex(time index): a sparse map from a timestamp to an offset, enabling "give me records from time T" lookups (used by time-based seeks and retention).
Reclaiming space happens in one of two ways, chosen per topic by its cleanup.policy:
| Policy | What it does | Best for |
|---|---|---|
| delete (retention) | Deletes whole segments once they are older than retention.ms or the partition exceeds retention.bytes. Deletion is by segment, never by individual record, which keeps it cheap. | Event streams where only recent data matters. |
| compact (log compaction) | A background cleaner rewrites segments keeping only the latest value per key. Older values for the same key are discarded; a record with a null value (a tombstone) marks a key for deletion. | Changelogs and state — where you want the current value for every key, kept forever. |
4. The Producer
The producer decides which partition each record goes to, batches records for efficiency, and chooses how strong a durability guarantee it wants via the acks setting.
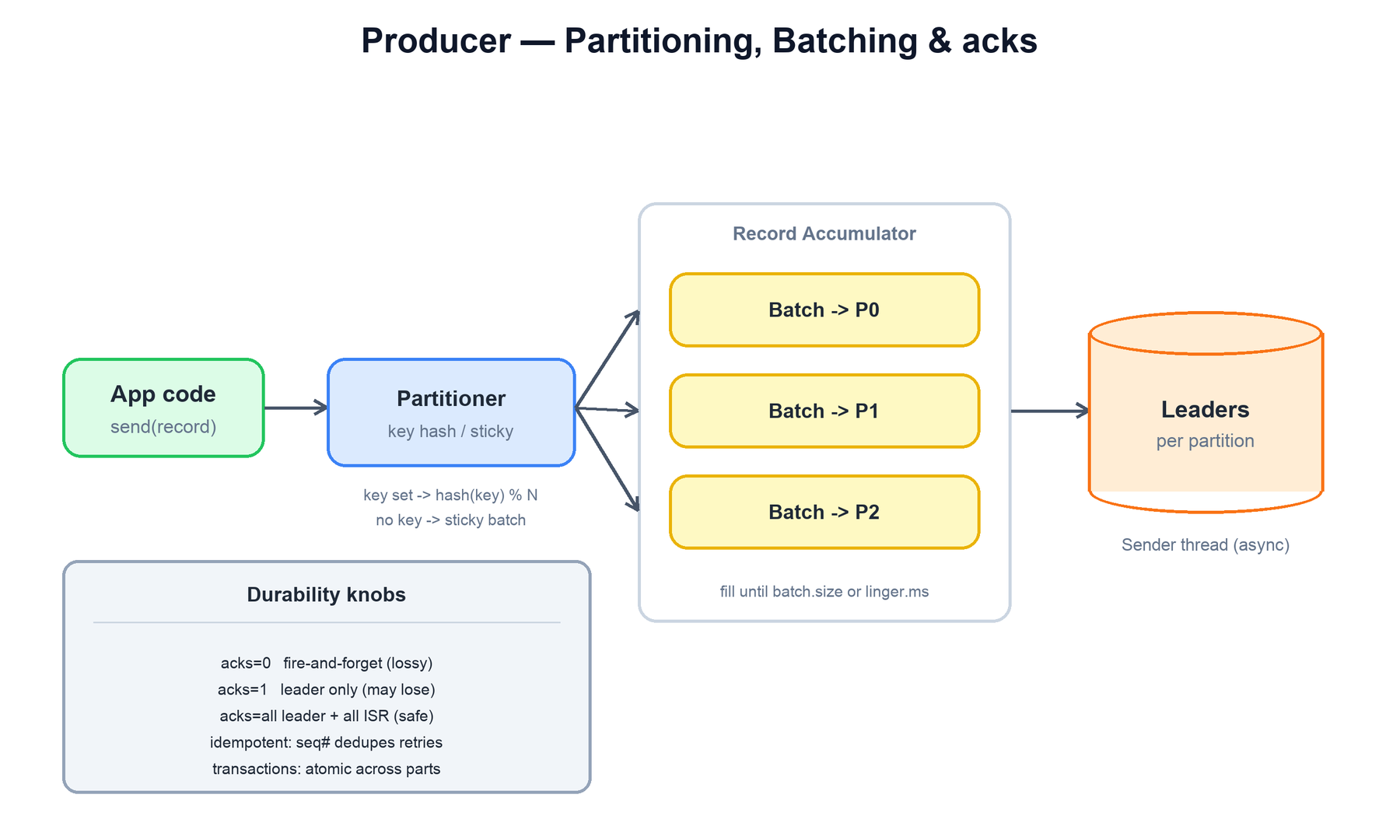
linger.ms elapses.Partitioning
The partitioner maps each record to a partition:
- Keyed records: the partition is
hash(key) % num_partitions(a deterministic murmur2 hash). All records with the same key land in the same partition, which is how Kafka guarantees per-key ordering. - Keyless records: the modern default is the sticky partitioner — the producer fills one partition's batch, sends it, then sticks to a new partition for the next batch. This produces larger, fewer batches and better throughput than naive round-robin per record.
Batching and linger
The producer does not send one record at a time. Records accumulate in per-partition batches in the record accumulator. A batch is sent when it reaches batch.size or when linger.ms elapses — a deliberate small delay that trades a little latency for much larger, more efficient batches (and better compression).
acks and the durability ladder
acks | Who must acknowledge | Trade-off |
|---|---|---|
| 0 | Nobody — fire and forget | Lowest latency, can silently lose data. |
| 1 | The partition leader only | Fast, but a record acked by a leader that then crashes before followers replicate it is lost. |
| all (-1) | The leader and all in-sync replicas | Strongest durability; the record survives as long as one in-sync replica survives. |
Two further guarantees build on top of acks:
- Idempotent producer: each producer is given an ID and each record a sequence number per partition. The broker rejects duplicates, so a network retry no longer writes the record twice. This gives exactly-once semantics for a single producer to a single partition with no application work.
- Transactions: let a producer write to multiple partitions (and commit consumer offsets) atomically — either all the writes become visible or none do. This is what enables exactly-once stream processing (read-process-write) across topics.
function send(record):
if record.key is not None:
partition = murmur2(record.key) % num_partitions # same key -> same partition
else:
partition = sticky_partition() # fill one batch, then switch
batch = accumulator.batch_for(partition)
batch.append(record, seq = next_seq(partition)) # seq# enables idempotence
if batch.full() or batch.age() > linger_ms:
sender.enqueue(batch) # background thread sends to the leader
# on send: broker acks per the acks setting (0 / 1 / all)5. Replication and the In-Sync Replica Set
Durability comes from replication. Each partition is configured with a replication factor — the number of copies. One replica is the leader; the rest are followers that continuously fetch from the leader to stay caught up. All reads and writes for a partition go through its leader; followers exist purely for redundancy and failover.
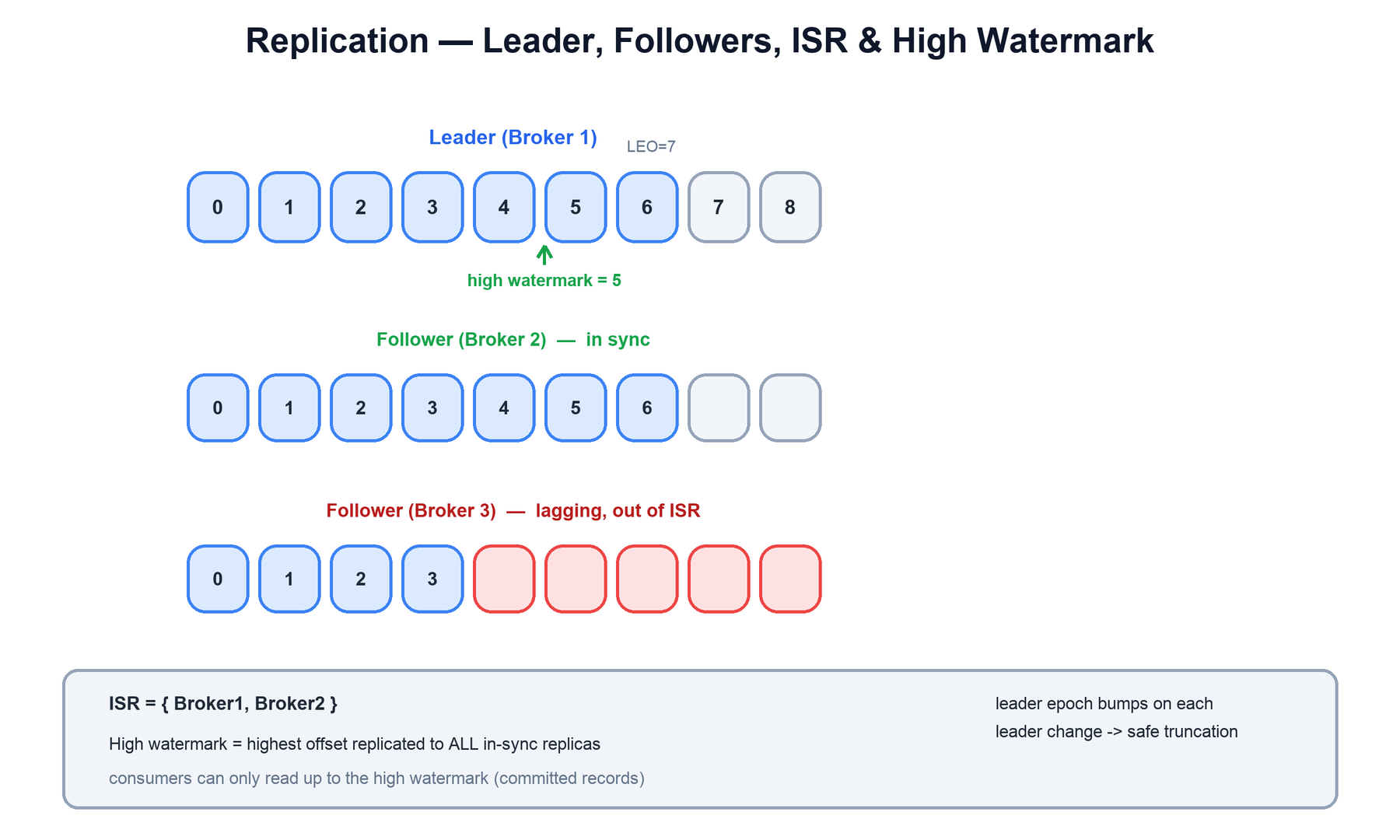
The central concepts are:
- ISR (in-sync replica set): the subset of replicas that are sufficiently caught up with the leader (within
replica.lag.time.max.ms). A follower that falls behind is dropped from the ISR; when it catches up again it rejoins. The leader is always in its own ISR. - LEO (log end offset): the offset of the next record a replica will write — i.e. one past its last record.
- High watermark (HW): the highest offset that has been replicated to every replica in the ISR. This is the boundary of committed data. Consumers can only read records below the high watermark, which guarantees they never see a record that could later be lost if the leader fails.
- Leader epoch: a monotonically increasing number stamped on each leadership term. When leadership changes, the new leader's epoch lets followers detect and truncate any uncommitted records they hold from a previous leader, avoiding divergence.
A write under acks=all is acknowledged only once the high watermark advances past it, which means it is durably on every in-sync replica. The minimum size of the ISR can be enforced with min.insync.replicas: if the ISR shrinks below that, the leader refuses acks=all writes rather than accept data it cannot safely replicate.
6. Write Path
Putting the producer and replication together, here is the full life of a write under acks=all. The key property is that an acknowledgement means the record is committed — durable on every in-sync replica and visible to consumers.
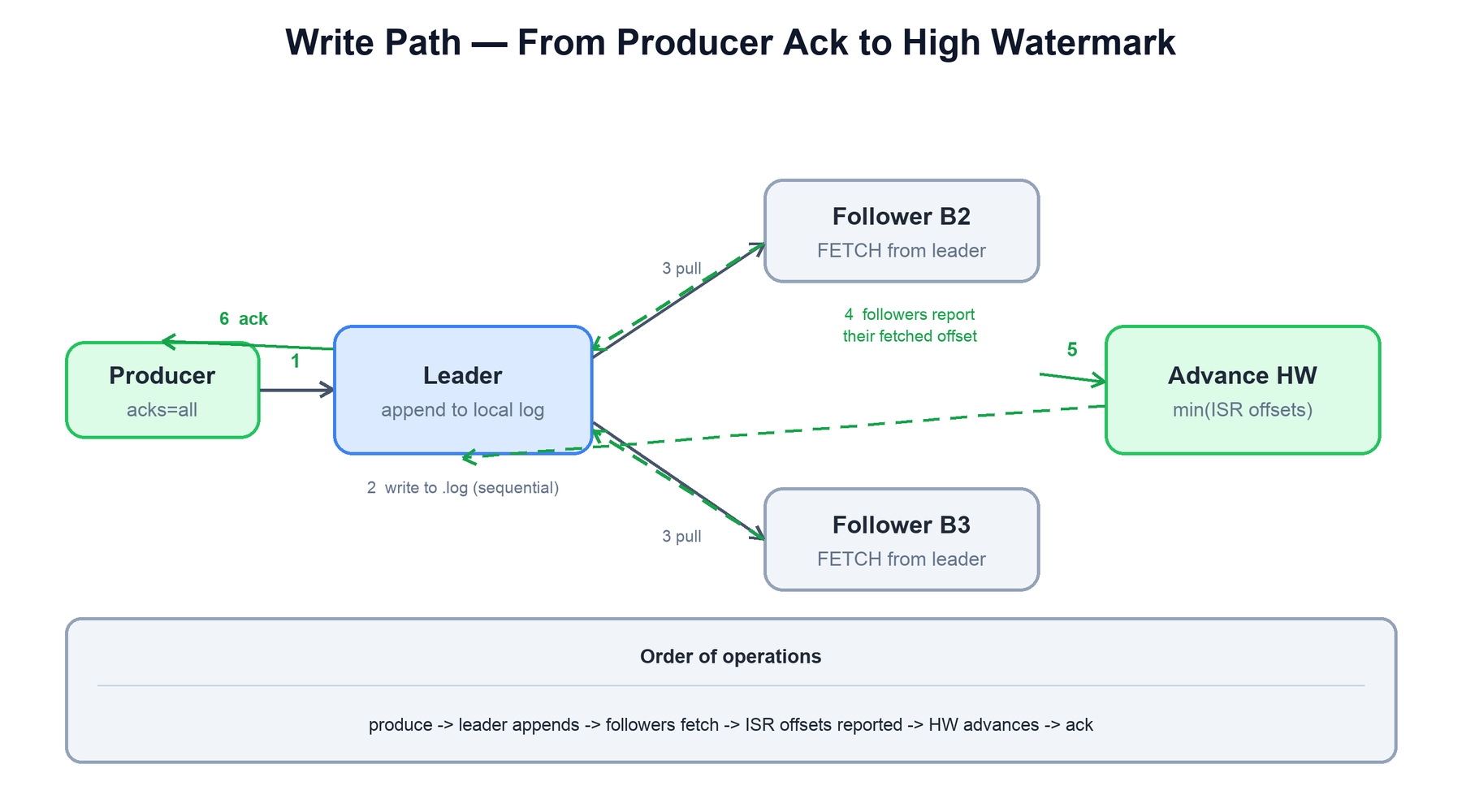
Step by step:
- The producer sends the record (or batch) to the partition's leader broker.
- The leader appends it to its local
.log— a sequential disk write — advancing its log end offset. - Followers continuously fetch from the leader (replication is pull-based, just like a consumer) and append the new records to their own logs.
- Each follower's fetch request tells the leader how far it has replicated. The leader tracks these offsets.
- Once every in-sync replica has the record, the leader advances the high watermark to
minof the ISR's offsets. The record is now committed. - The leader acks the producer (immediately, for
acks=1; after the HW advances, foracks=all).
on leader, produce(record, acks):
leader_log.append(record) # 1-2. sequential write, LEO++
if acks == 1:
ack() # leader durable, may lose on failover
# followers pull in the background:
on follower_fetch(follower, fetch_offset):
follower.offset = fetch_offset # 3-4. report replicated position
new_hw = min(offset of r for r in ISR) # 5. advance only over in-sync replicas
high_watermark = new_hw
if acks == "all" and record.offset <= high_watermark:
ack() # 6. committed on all ISR -> safe7. Consumers and Consumer Groups
Consumers read by issuing fetch requests to partition leaders. The scaling unit is the consumer group: a set of consumers that cooperate to read a topic, with each partition assigned to exactly one consumer in the group. That is how Kafka delivers each record once per group while still reading partitions in parallel.
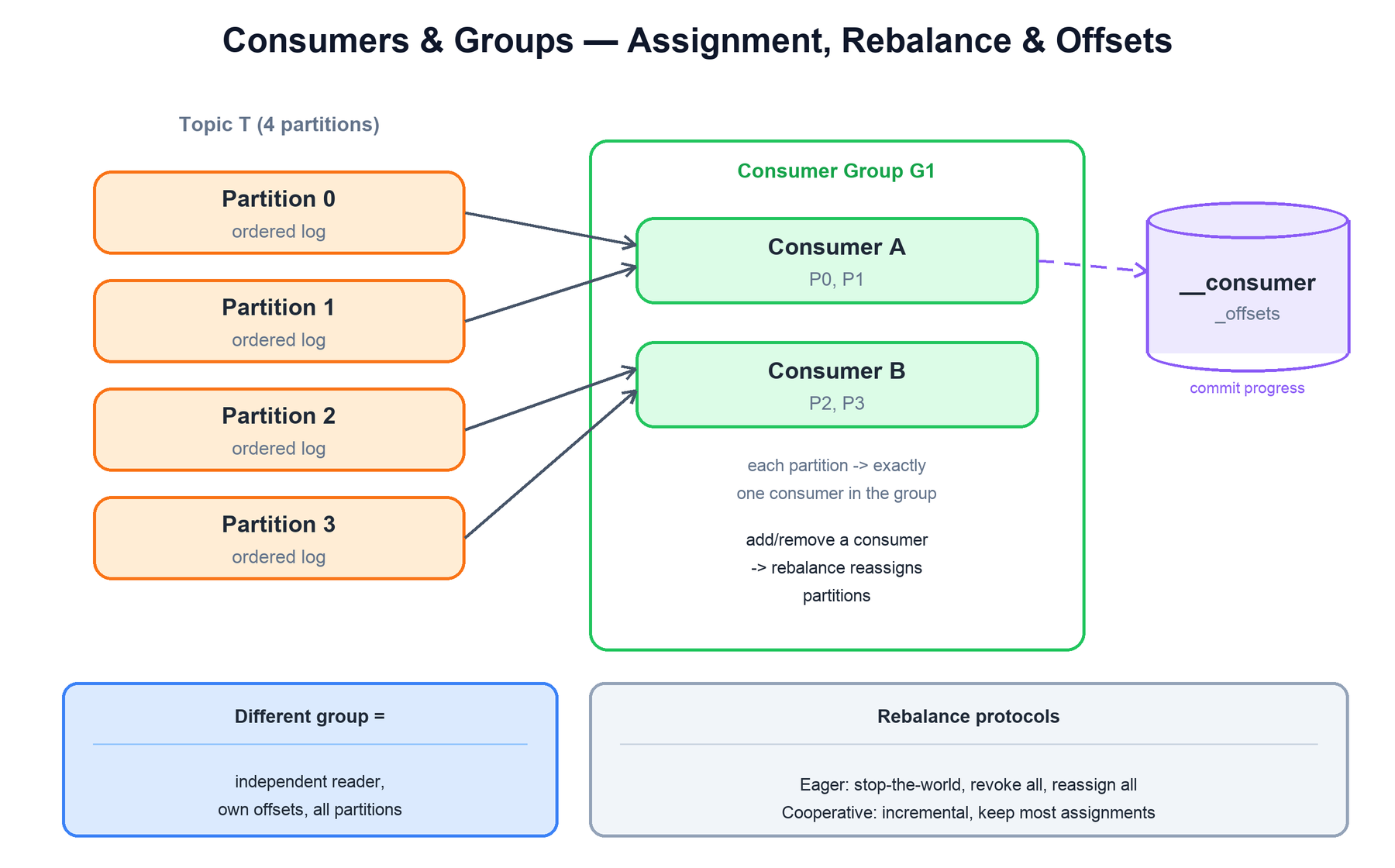
__consumer_offsets topic.The mechanics:
- Group assignment: a group coordinator (a broker) assigns partitions to the consumers in a group. With N partitions and C consumers, each consumer owns roughly N/C partitions. More consumers than partitions means some sit idle — partition count is the ceiling on group parallelism.
- One partition, one consumer: because a partition is an ordered log and only one consumer in the group reads it, per-partition ordering is preserved end to end.
- Independent groups: a different group is a completely separate reader with its own offsets. Two groups subscribed to the same topic each receive every record — this is the pub/sub fan-out.
Rebalancing
When a consumer joins, leaves, or dies, the group must reassign partitions — a rebalance. There are two protocols:
| Protocol | Behavior |
|---|---|
| Eager | Stop-the-world: every consumer revokes all its partitions, then the coordinator reassigns everything. Simple, but the whole group pauses during the rebalance. |
| Cooperative (incremental) | Only the partitions that actually need to move are revoked; consumers keep processing the partitions they retain. Much smaller disruption, now the default for most workloads. |
Offset commits
A consumer records how far it has read by committing offsets. These are written to an internal compacted topic, __consumer_offsets, keyed by (group, topic, partition) — so the latest commit per partition is always retained. On restart or after a rebalance, a consumer resumes from its last committed offset. Committing after processing gives at-least-once delivery; committing before processing gives at-most-once. The offset is just data in a Kafka topic, which is why it survives broker restarts with no extra machinery.
consumer in group G subscribed to topic T:
partitions = coordinator.assign(G, me) # my share of T's partitions
for p in partitions:
pos[p] = committed_offset(G, p) or reset_policy # resume point
loop:
records = fetch(leader_of(p), pos[p]) # pull from each partition leader
process(records)
pos[p] += len(records)
commit(G, p, pos[p]) # write to __consumer_offsets
# on member change: coordinator triggers a rebalance (eager or cooperative)8. Read Path and Performance
A consumer fetch is served entirely by the partition leader. The reason Kafka can saturate network cards on commodity hardware is that the read path barely touches user space at all — it leans on the operating system.
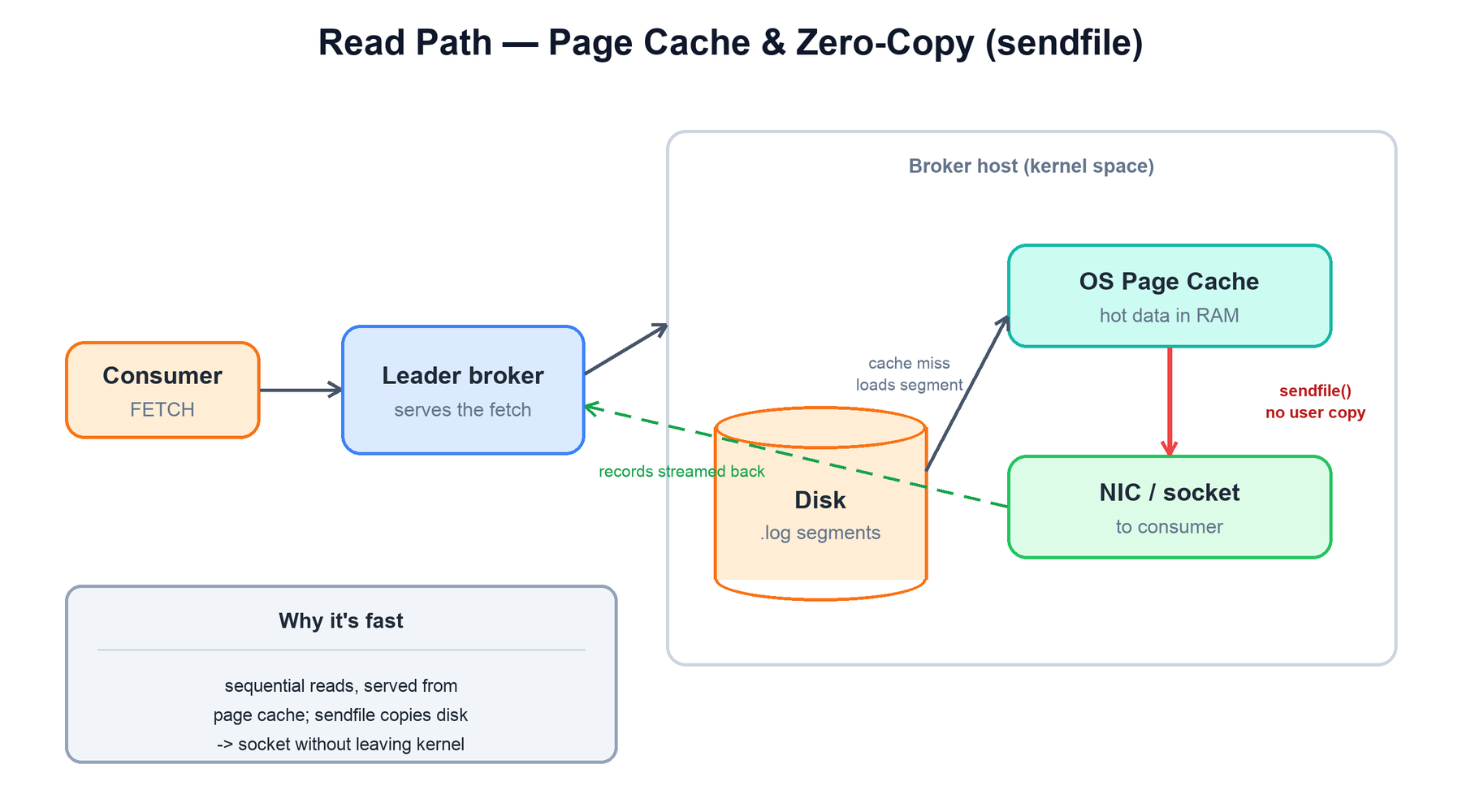
sendfile() copies data straight from page cache to the network socket without ever entering the broker's user-space memory.Two operating-system features do the heavy lifting:
- OS page cache: Kafka does not maintain its own record cache in the JVM heap. It writes to and reads from files, and the operating system keeps recently used file pages in RAM. Because consumers typically read near the tail — data that was just written and is still hot in cache — most fetches are served from memory with no disk seek. The page cache is shared, survives broker process restarts, and is managed by code far more optimized than anything Kafka could write itself.
- Zero-copy with
sendfile(): normally, sending a file over a socket copies bytes from the kernel page cache into a user-space buffer, then back into a kernel socket buffer. Kafka instead uses thesendfilesystem call, which tells the kernel to copy the requested bytes directly from the page cache to the network socket. The data never enters the JVM, eliminating two copies and the associated CPU and garbage-collection cost.
This works precisely because records are stored on disk in exactly the wire format consumers expect — no per-record deserialization or transformation is needed on the broker, so the bytes can be streamed untouched. Combined with sequential reads (consumers march forward through the log) and large batched fetches, the broker mostly acts as a fast pipe from page cache to socket.
on leader, fetch(partition, offset, max_bytes):
pos = index.lookup(offset) # sparse index -> byte position
# the OS page cache already holds hot (tail) segments in RAM
return sendfile(log_file, pos, max_bytes, socket)
# kernel copies page cache -> socket directly; bytes never enter the JVM9. Summary
The whole system is built from a few reinforcing ideas:
| Concern | Mechanism |
|---|---|
| What is the core abstraction? | An append-only, ordered, offset-indexed commit log, split into partitions. |
| How does it scale and order? | Partitions: the unit of parallelism and the unit of ordering. Order holds within a partition, never across. |
| How is data stored and reclaimed? | Immutable segments with sparse offset/time indexes; reclaimed by retention (delete) or compaction (latest per key). |
| How do producers control durability? | acks 0/1/all, batching with linger.ms, idempotent IDs, and optional transactions. |
| How is data made durable? | Leader/follower replication; the ISR plus the high watermark define what is committed and readable. |
| How do many readers share work? | Consumer groups assign one partition to one consumer; offsets are committed to __consumer_offsets. |
| How is it so fast? | Sequential I/O, the OS page cache, and zero-copy sendfile from cache straight to the socket. |
| How do brokers coordinate? | A KRaft (Raft) controller quorum holds metadata and assigns leaders — no more ZooKeeper. |