Designing for Idempotency & Exactly-Once
A system design interview guide to making retried operations safe, so that a request that lands twice never charges a card twice, places two orders, or otherwise double-applies a side effect.
Idempotency is one of those topics that sounds academic until you trace a single failed request through a real distributed system and realize how often "did it actually happen?" has no clean answer. A client sends a request, the network drops the response, and now nobody — not the client, not the server — knows whether the work was done. The client's only safe move is to retry, and that retry is where money gets charged twice and orders get duplicated. This guide builds up the standard defense: client-supplied idempotency keys, a dedup store that records each key's outcome, careful handling of concurrent retries, and the broader idea that you cannot guarantee exactly-once delivery but you can guarantee exactly-once effect. It closes with the transactional outbox pattern and the art of designing operations that are naturally idempotent in the first place.
Contents
1. Why Retries Are Unavoidable
The root cause of every duplicate problem is that a network call has three possible outcomes, not two. It can clearly succeed, it can clearly fail, or — the troublesome third case — it can leave the caller with no answer at all. A request may have reached the server and been fully processed, but the response was lost on the way back. From the caller's chair, a lost response is indistinguishable from a request that never arrived.
Given that ambiguity, the caller has only two choices, and both are bad if the operation is not idempotent. It can give up, risking that a legitimate operation silently never happened. Or it can retry, risking that an operation which already succeeded gets applied a second time. Real systems almost always choose to retry, because losing a customer's order is worse than the rare double, and because timeouts are common enough that a no-retry policy would make the system feel broken. Once you accept that retries are a permanent feature of the landscape, the design question becomes: how do we make a second, third, or tenth identical request harmless?
2. How Retries Create Duplicates
It helps to make the failure concrete. Imagine a checkout endpoint that charges a card and creates an order. The client calls it, the server charges the card and writes the order, and then the connection drops before the success response gets back. The client, seeing only a timeout, retries. The server happily charges the card again and creates a second order. The customer is now out double the money and has two shipments on the way — a failure that is both expensive and deeply eroding of trust.
The same shape appears anywhere a write has a side effect that the world can observe: sending money, placing an order, sending an email, incrementing a counter, provisioning a resource. Note that pure reads are naturally safe — fetching a record twice changes nothing — so the entire problem is confined to writes that do something. The job of an idempotency design is to let those writes be retried as freely as reads.
| Operation | Naively retried | What the user sees |
|---|---|---|
| Charge a card | Charged twice | Double the amount debited. |
| Place an order | Two orders created | Two shipments, two invoices. |
| Transfer funds | Money moved twice | Account balances wrong. |
| Send an email | Duplicate emails | Annoyance, lost trust. |
3. The Idempotency Key Pattern
The standard solution puts the client in charge of identity. Before sending a request that has a side effect, the client generates a single unique value — an idempotency key — that names this one logical request, and attaches it (typically as a header such as Idempotency-Key). The crucial property is that the same key is reused across all retries of the same logical request, but a brand-new logical request gets a brand-new key. A UUID generated once per "user clicked Pay" is the canonical choice.
On the server, the key turns "have I done this already?" from an unanswerable question into a simple lookup. The server records, for each key, the outcome of the request. The first time it sees a key, it executes the operation and stores the result against the key. On any later request bearing the same key, it skips execution entirely and returns the stored result. The client cannot tell whether its request was the one that did the work or a replay — it just gets the same answer, which is exactly what it wanted.
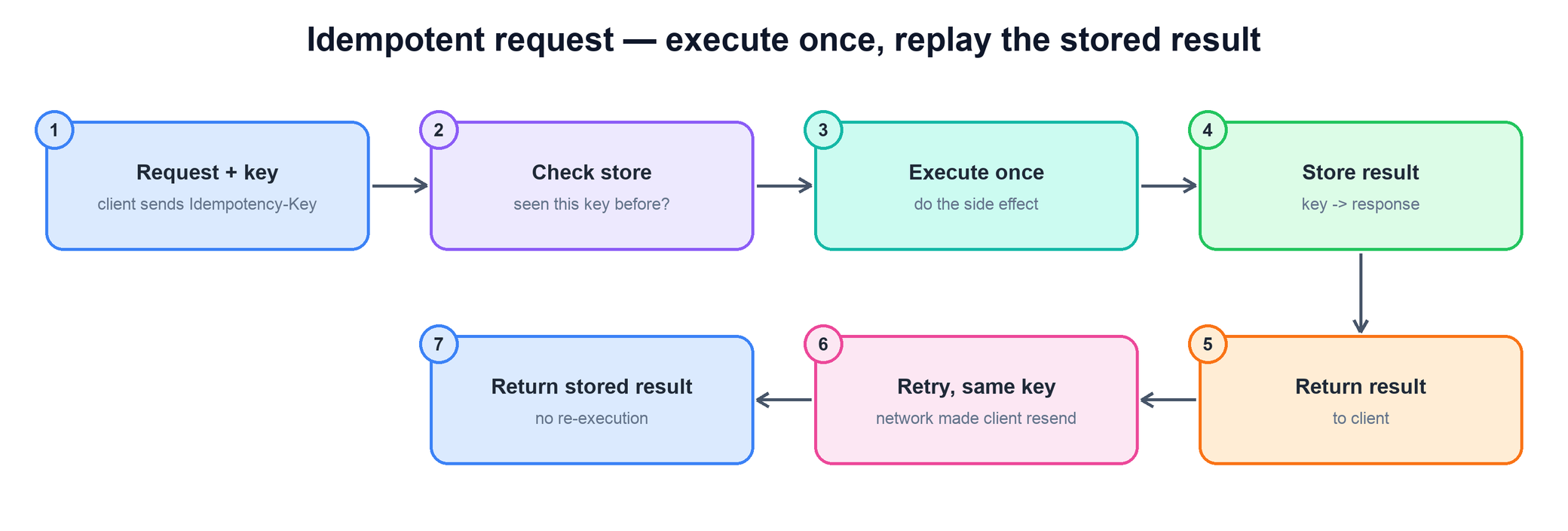
function handle(request, idempotency_key):
existing = store.get(idempotency_key)
if existing and existing.status == "COMPLETED":
return existing.response # replay: do not re-execute
result = do_the_work(request) # the side effect, run once
store.put(idempotency_key, status="COMPLETED", response=result)
return resultThe pattern shifts a small responsibility to the client — it must generate and reuse a key — in exchange for a large guarantee from the server. It also keeps the contract explicit: a key represents one logical intent, so reusing a key for a genuinely different request would be a client bug, not the server's problem to disambiguate.
4. The Dedup Store
The server needs somewhere to remember keys and their outcomes. This dedup store is the heart of the design, and it is conceptually a small table keyed by the idempotency key. Each row records enough to replay the original outcome: the key itself, a status, the stored response body, and a time-to-live after which the row can be reaped.
| Column | Purpose |
|---|---|
| key | The client-supplied idempotency key. Primary key / unique index. |
| status | IN_PROGRESS while the work runs, COMPLETED once it has finished. |
| response | The serialized result to replay on a retry (status code and body). |
| ttl | Expiry. Keys do not need to live forever — a day or so usually covers all realistic retries. |
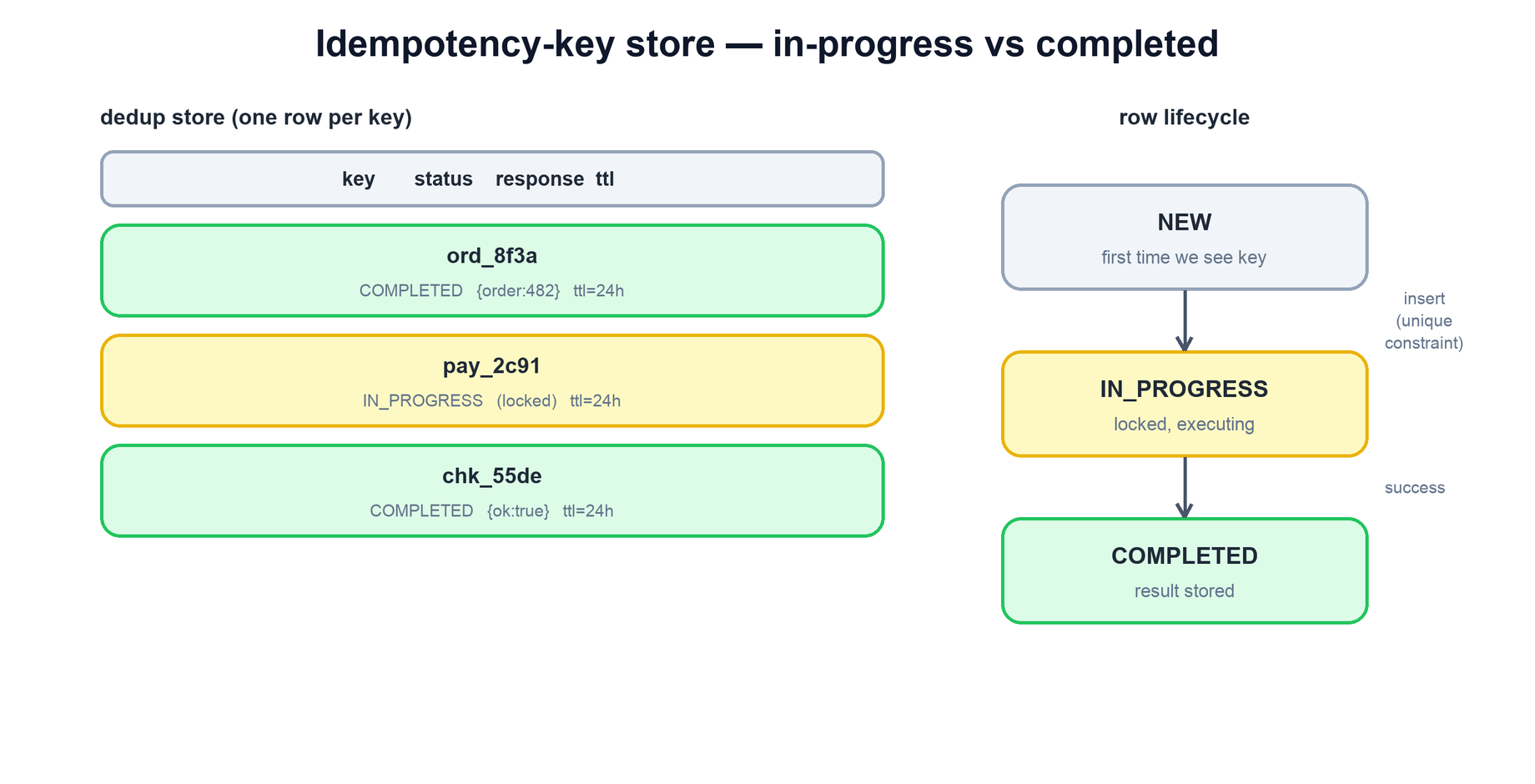
The TTL matters more than it first appears. Without it the table grows without bound, since every distinct request ever made leaves a permanent row. With it, the store stays bounded and the only cost is that a retry arriving after the TTL would be treated as a fresh request — an acceptable trade because legitimate retries happen within seconds or minutes, not days. Choosing the window is a judgement call between safety and storage.
5. Concurrent Retries & Locking
The naive version above has a subtle race. Suppose two copies of the same request arrive almost simultaneously — a client that retried aggressively, or a load balancer that duplicated a request. Both check the store, both find no completed row, and both proceed to execute the side effect. The dedup check did nothing because neither request had finished writing its result when the other looked. This is precisely the double-charge we were trying to prevent, now hiding inside the very mechanism meant to stop it.
The fix is to claim the key before doing the work, atomically. The first request to arrive inserts a row in the IN_PROGRESS state; a unique constraint on the key column ensures that only one insert can win. The loser of that race — the concurrent duplicate — gets a constraint violation and knows another request already owns this key. It can then wait for the in-progress request to complete and return its stored result, or return a "request in progress" response telling the client to retry shortly. Either way, exactly one execution happens.
function handle(request, key):
try:
store.insert(key, status="IN_PROGRESS") # unique constraint claims the key
except UniqueViolation:
return wait_for_result(key) # another request owns it; replay its result
result = do_the_work(request)
store.update(key, status="COMPLETED", response=result)
return resultOne loose end is the crash that strikes after the IN_PROGRESS row is written but before the work completes. That key is now stuck claimed forever. A short lease on the in-progress state — or treating a sufficiently old in-progress row as abandoned and reclaimable — handles this, so a crashed request does not permanently block retries of its own key.
6. Delivery vs Effect
It is worth being precise about what is and is not achievable, because the phrase "exactly-once" is thrown around loosely. Exactly-once delivery is impossible over an unreliable network. The sender can never know for certain that a message arrived without an acknowledgement, and the acknowledgement itself can be lost — so to be safe the sender must be willing to resend, which means the message can arrive more than once. No protocol escapes this; it is a consequence of the two-generals problem, not a missing feature.
What is achievable is exactly-once effect. You combine at-least-once delivery — keep retrying until you get an acknowledgement, accepting that duplicates will occur — with deduplication on the receiver using an idempotency key. The network may deliver the same logical operation several times, but the receiver applies its effect exactly once. This is the only honest meaning of "exactly-once" in a distributed system: not that the message travels once, but that its consequence happens once.
| Guarantee | Achievable? | How |
|---|---|---|
| Exactly-once delivery | No | Impossible over an unreliable network — lost acks force resends. |
| At-least-once delivery | Yes | Retry until acknowledged; duplicates are expected. |
| Exactly-once effect | Yes | At-least-once delivery + dedup on an idempotency key. |
7. The Transactional Outbox
Idempotency on the receiver handles duplicates, but there is a matching problem on the sender: how do you reliably publish an event exactly when a database change commits, with no chance of the two diverging? The tempting approach — write to the database, then publish to the message broker — has a fatal gap. If the process crashes between the two steps, you have committed the data but never announced it, and downstream systems never learn. Publish first and the opposite happens: you announce a change that the database then fails to commit.
The transactional outbox closes the gap by making the event part of the same database transaction as the business write. In one atomic transaction you write the business row and insert a row into an outbox table describing the event. Because they commit together, you can never have one without the other. A separate relay process then polls the outbox, publishes each pending event to the broker, and marks it sent. If the relay crashes mid-publish, it simply republishes on restart — which is harmless precisely because the consumers are idempotent on the event id.
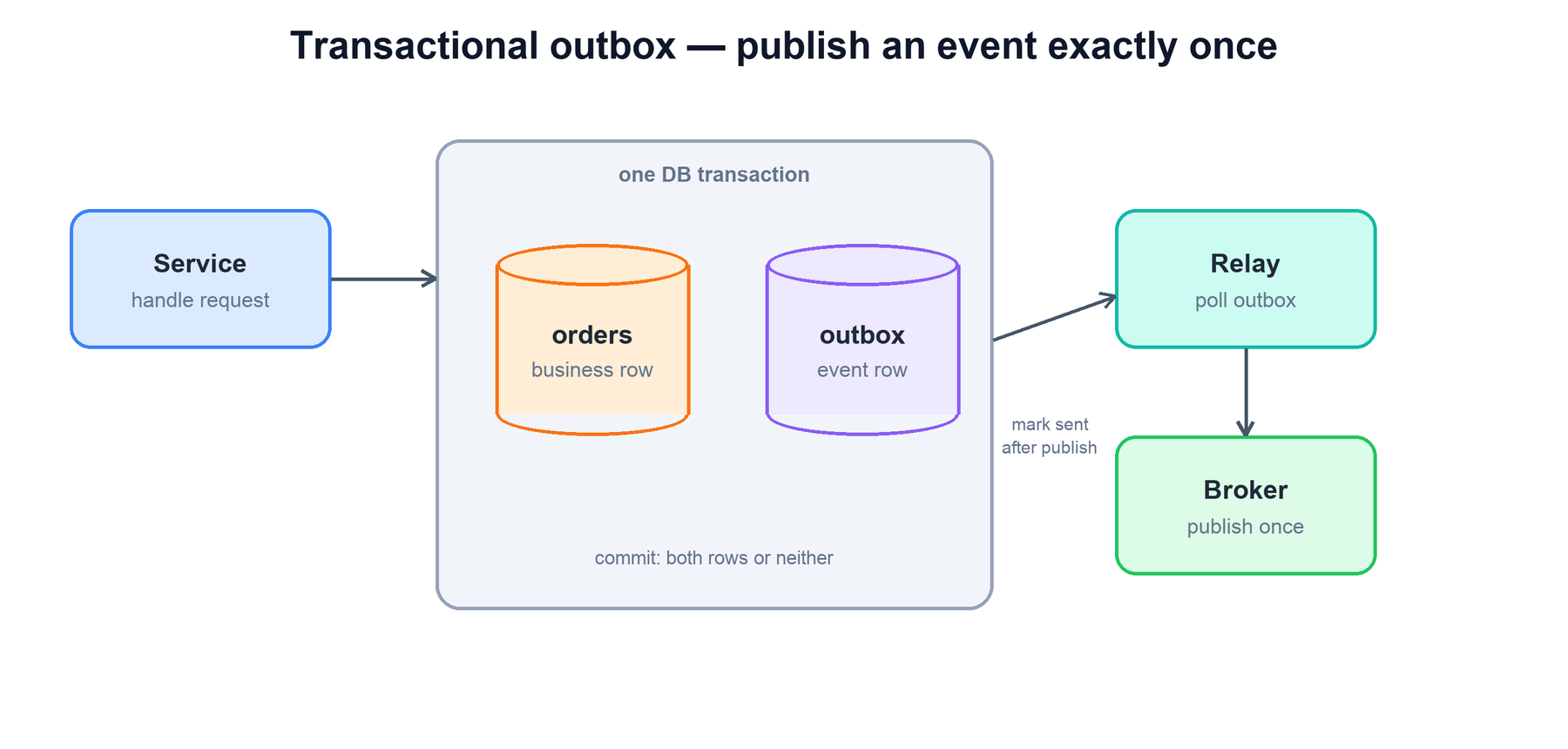
# inside one DB transaction
begin()
orders.insert(order) # the business change
outbox.insert(event="order_placed", payload=order, status="PENDING")
commit() # both rows, or neither
# relay, running separately
for event in outbox.where(status="PENDING"):
broker.publish(event) # at-least-once; consumers dedup
outbox.mark(event.id, status="SENT")8. Naturally Idempotent Design
The cheapest idempotency is the kind you do not have to bolt on, because the operation is idempotent by construction. Whenever you can express a write so that applying it twice yields the same end state as applying it once, you sidestep the whole machinery of keys and dedup stores. Several common shapes have this property.
- Upserts. "Set this record to this value" is naturally idempotent — running it again writes the same value and changes nothing. Contrast with "insert a new record," which duplicates on retry. Where the data model allows it, prefer set-to-state over append-new.
- Conditional writes. "Update only if the current version is N" (compare-and-set) makes a retry a no-op: the first write moves the version to N+1, so the retried write's condition no longer holds and it does nothing. This also guards against lost updates from concurrent writers.
- Deterministic identifiers. Deriving a record's primary key from the request content — rather than auto-generating one — means a retried create collides with the existing row instead of making a second one, turning the database's uniqueness into your dedup.
# naturally idempotent: set absolute state, not a delta
account.set_balance(target=500) # safe to run twice
# conditional write: retry becomes a no-op
update order set status="PAID"
where id = 42 and status = "PENDING" # second run matches nothing9. Summary
Idempotency is the discipline that lets a system retry freely without doubling its effects. The pieces reinforce one another:
| Concern | Mechanism |
|---|---|
| Why must we retry at all? | A lost response is indistinguishable from a lost request, so retrying is the only safe move. |
| Why do retries hurt? | Writes with side effects (charges, orders) get applied twice. |
| How do we identify a logical request? | A client-generated idempotency key, reused across all its retries. |
| How does the server dedup? | A dedup store mapping key → status, response, TTL. |
| How do we survive concurrent retries? | Claim the key first via a unique constraint; losers replay the result. |
| What can we actually guarantee? | Not exactly-once delivery, but exactly-once effect via at-least-once + dedup. |
| How do we publish events reliably? | The transactional outbox: event and data commit together; a relay publishes once. |
| How do we avoid the problem entirely? | Naturally idempotent operations: upserts, conditional writes, deterministic ids. |