Apache Flink — Internal Architecture
A developer's guide to how Flink actually works under the hood: the cluster runtime, how a program becomes parallel subtasks, how state lives and survives failures, and how checkpoints, watermarks, and backpressure keep results correct on an unbounded stream.
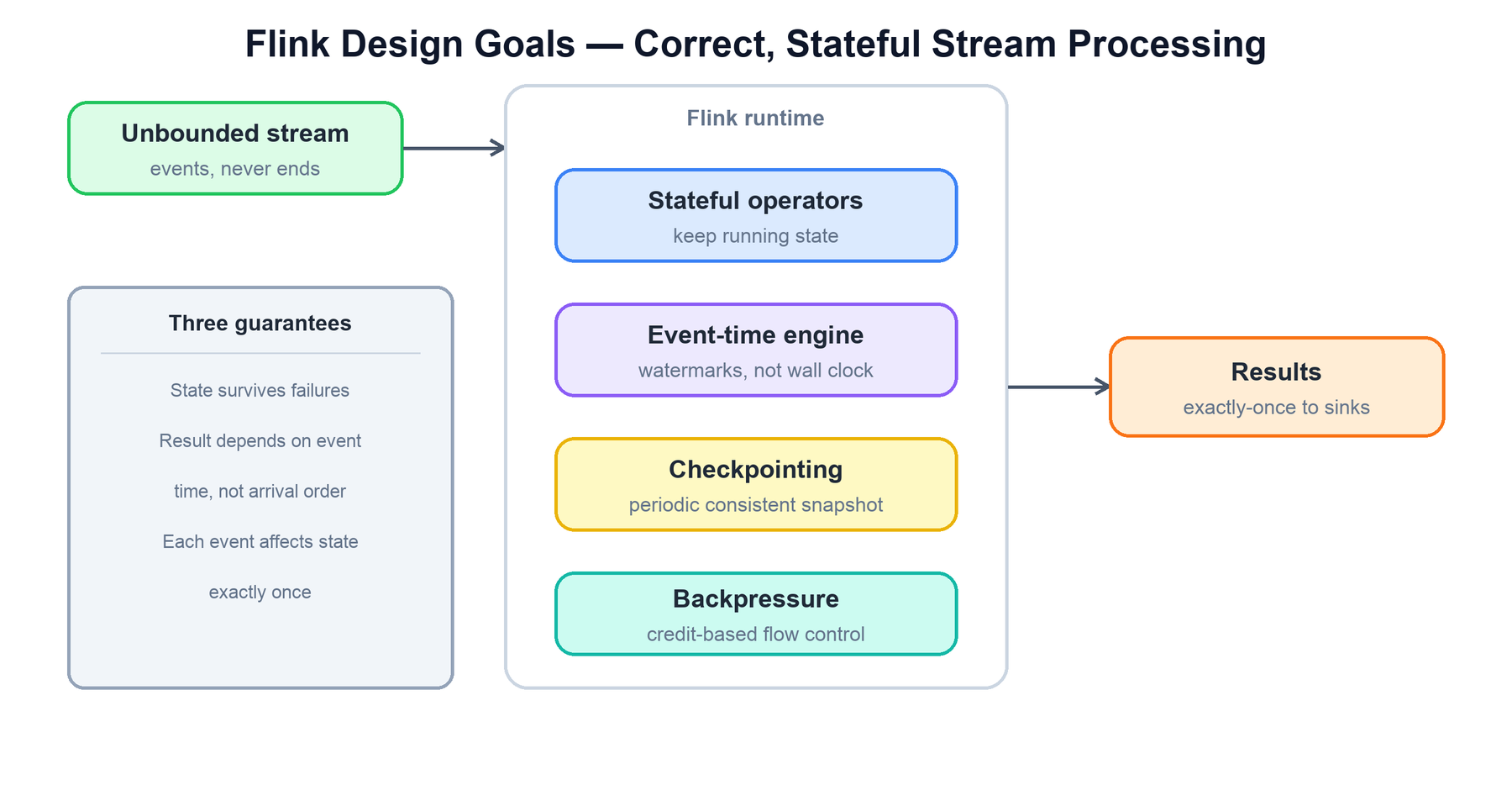
Apache Flink is a distributed engine for stateful computation over data streams. Where a batch engine processes a finite dataset and stops, Flink treats data as an unbounded stream of events that may never end, and it keeps long-lived state as it goes. Its design rests on three reinforcing ideas: every operator can hold state that survives failures; results are computed in event time (when things happened) rather than the order events happen to arrive; and the combination of checkpoints and replayable sources gives exactly-once semantics for that state. Understanding Flink means understanding how those three pieces fit together on top of a fairly conventional master/worker runtime.
Contents
1. Design Goals and Core Ideas
Every internal decision in Flink traces back to a small set of goals for processing unbounded streams correctly. Keeping them in mind makes the rest of the architecture predictable.
| Goal | How Flink achieves it |
|---|---|
| Stateful stream processing | Operators keep partitioned, fault-tolerant state in a state backend. State is a first-class citizen, not a side effect bolted on top. |
| Event-time correctness | Records carry their own timestamps. Watermarks track progress in event time, so results do not depend on the wall-clock order in which events arrive. |
| Exactly-once semantics | Periodic checkpoints snapshot a globally consistent cut of all state. On failure the job rewinds to the last checkpoint and replays from there, so each event affects state exactly once. |
| High throughput, low latency | Pipelined, record-at-a-time execution (not micro-batching) with buffered network transfer. Backpressure is handled natively. |
| Scalability | Every operator runs as many parallel subtasks. Parallelism is set per operator, and state is repartitioned cleanly on rescale via savepoints. |
2. Cluster Architecture
A Flink cluster follows a master/worker pattern. The master is the JobManager and the workers are TaskManagers. Unlike Cassandra's peer-to-peer ring, there is a clear coordination role — but it is split into three distinct responsibilities so that a single failed job cannot take down the whole cluster.
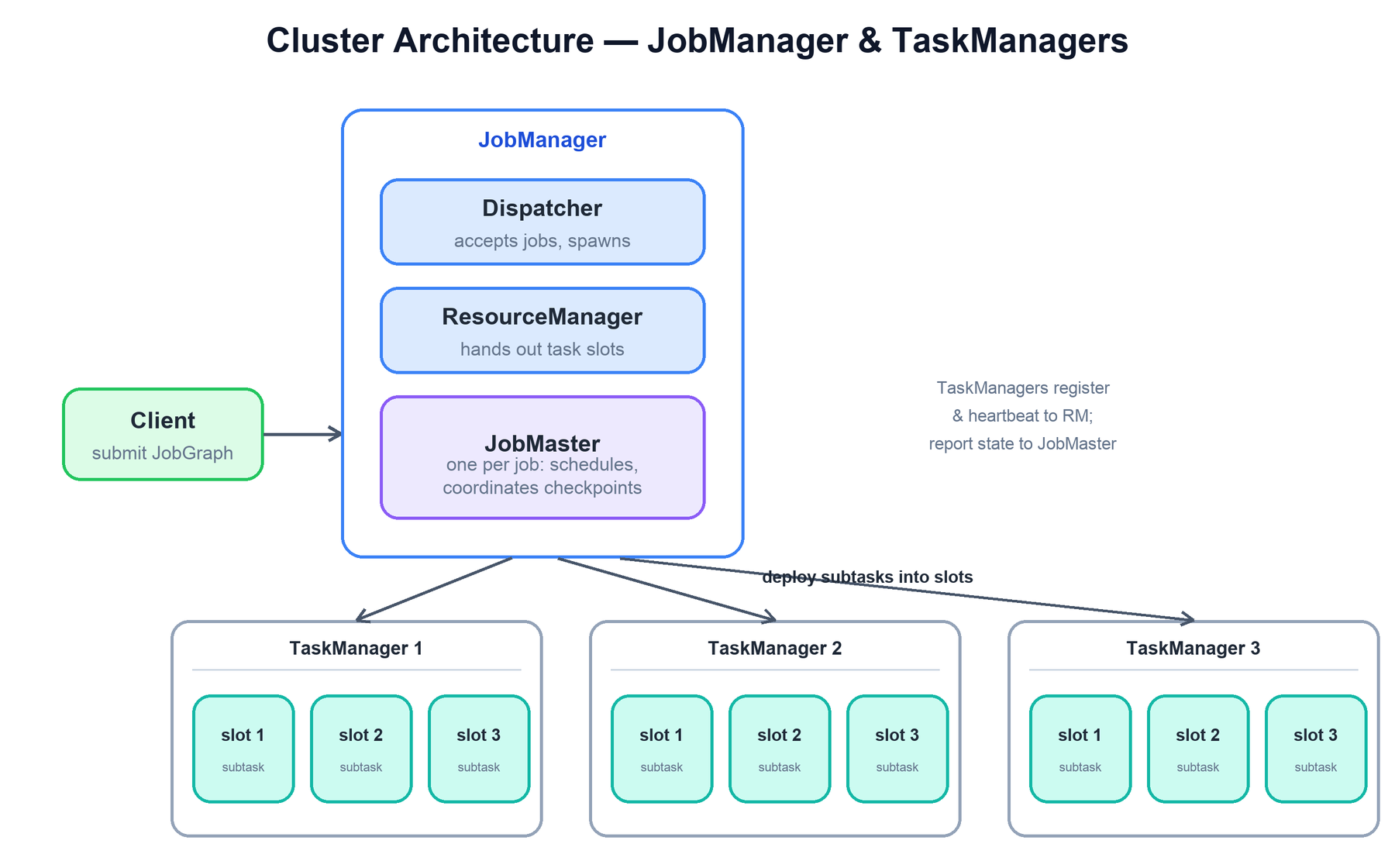
The components are:
- Dispatcher: the cluster entry point. It receives submitted jobs over REST, starts a dedicated JobMaster for each one, and serves the web UI. It is the front door, not the scheduler.
- ResourceManager: manages task slots — the unit of resource a TaskManager offers. It hands free slots to JobMasters that ask for them and, in deployments like YARN or Kubernetes, can request or release TaskManagers dynamically.
- JobMaster: one per running job. It turns the submitted graph into a schedule, requests slots, deploys subtasks, tracks their status, and drives checkpointing. When a job finishes or fails permanently, its JobMaster goes away; other jobs are unaffected.
- TaskManager: a worker JVM (or process) that provides a fixed number of task slots. Each slot runs one parallel slice of the pipeline. TaskManagers register with the ResourceManager, heartbeat to it, and exchange data directly with each other over the network.
A task slot represents an isolated share of a TaskManager's resources (primarily managed memory). A TaskManager with three slots can run three parallel subtasks. By default Flink allows slot sharing: subtasks from different operators of the same job can share one slot, so a full pipeline slice fits in a single slot and the slot count effectively caps the job's parallelism.
Submitting a job proceeds roughly like this:
function submit(job_graph):
dispatcher.receive(job_graph) # REST entry point
jm = dispatcher.start_job_master(job_graph)
needed = jm.compute_required_slots() # from operator parallelism
slots = resource_manager.allocate(needed)
exec_graph = jm.build_execution_graph(job_graph)
for subtask in exec_graph.subtasks():
slot = slots.pick_for(subtask)
task_manager(slot).deploy(subtask) # ship code + state handle
jm.track_status() # reschedule on failure3. The Dataflow Graph
A Flink program is a logical description of operators and the streams connecting them. Before it runs, that description passes through three representations, each lower-level than the last.
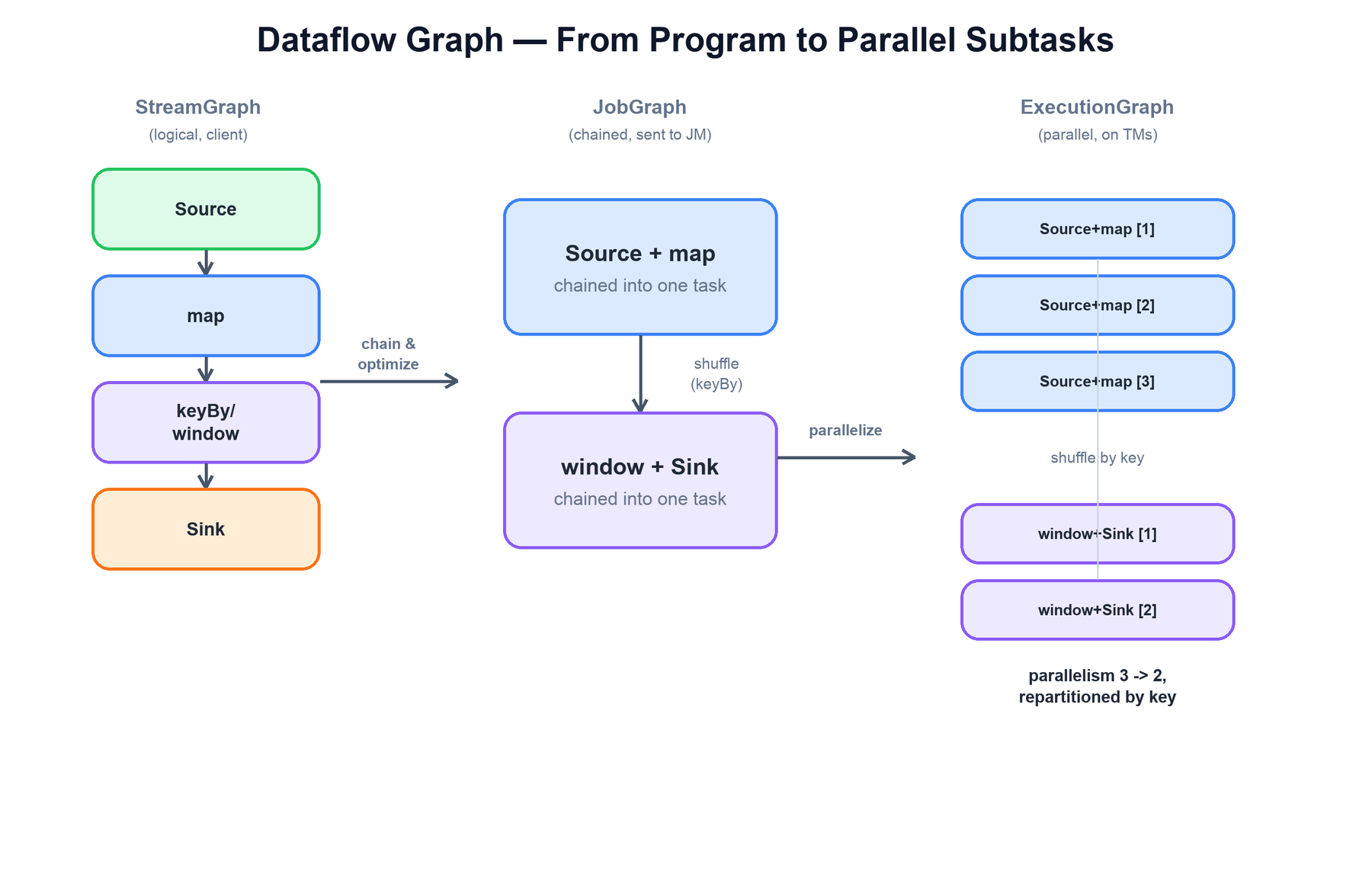
- StreamGraph: the direct, logical translation of your program on the client. One node per operator (
source,map,keyBy/window,sink), with the edges describing how streams connect. - JobGraph: the optimized graph the client ships to the JobManager. Its key optimization is operator chaining — fusing operators that have a one-to-one (forward) connection and the same parallelism into a single task, so records pass between them by direct method call instead of crossing a network or serialization boundary.
- ExecutionGraph: the parallel, physical graph the JobMaster builds. Each chained task becomes N parallel subtasks (one per unit of parallelism), each a separate instance running in its own slot. This is the graph that is actually scheduled and deployed.
Edges between operators come in two flavors. A forward edge keeps a record on the same subtask (and enables chaining). A redistributing edge — produced by keyBy, a rebalance, or a change in parallelism — sends records across the network to a different subtask. A keyBy in particular partitions the stream by a hash of the key so that all records for a given key always reach the same downstream subtask, which is what makes keyed state possible.
function chain(stream_graph): # client side
for op in stream_graph.operators():
if op.input_is_forward() and op.parallelism == op.input.parallelism \
and chaining_enabled(op):
fuse(op, op.input) # one task, no network
return job_graph # chained operators
function parallelize(job_graph): # JobMaster side
for task in job_graph.tasks():
for i in range(task.parallelism):
execution_graph.add_subtask(task, index=i)
return execution_graph4. State and State Backends
State is what separates Flink from a stateless stream filter. Anything an operator needs to remember between events — a running count, the contents of an open window, the last seen value per key — is held as Flink-managed state so the runtime can snapshot, restore, and repartition it. There are two kinds.
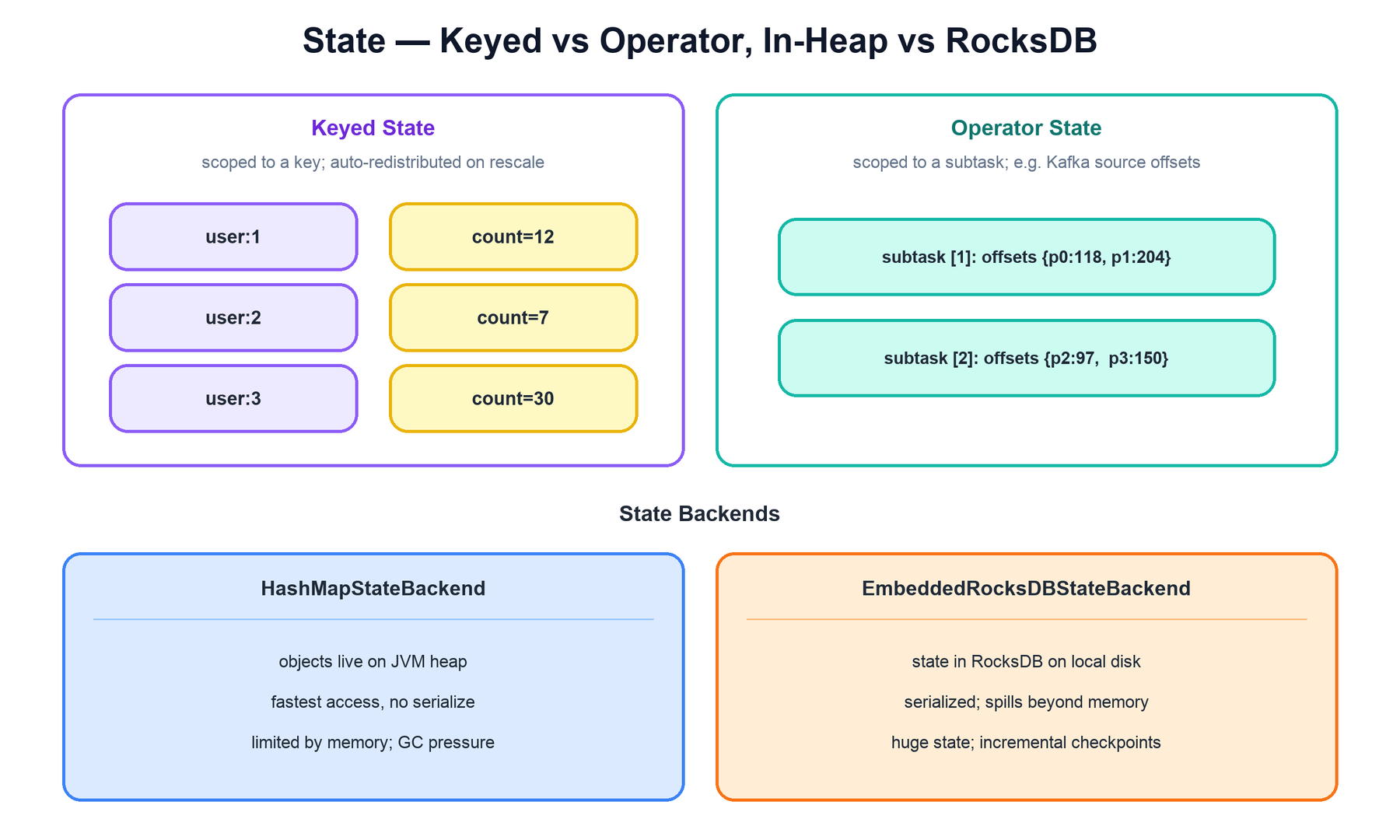
| Kind | Scope | Typical use |
|---|---|---|
| Keyed state | Bound to a single key on a keyed stream. Each key has its own independent value; a subtask only sees the keys hashed to it. | Per-user counters, per-key aggregations, window contents. ValueState, ListState, MapState. |
| Operator state | Bound to a parallel subtask, not a key. Redistributed by an explicit scheme when parallelism changes. | Source connector bookkeeping — e.g. a Kafka source storing the read offset per partition. |
Where that state physically lives is the job of the state backend. The choice is purely about capacity and access cost; it does not change semantics.
| Backend | Where state lives | Best for |
|---|---|---|
| HashMapStateBackend | As live Java objects on the JVM heap. | State that fits in memory. Fastest access (no serialization), but bounded by heap size and subject to GC pressure. |
| EmbeddedRocksDBStateBackend | Serialized in an embedded RocksDB instance on the local disk of each TaskManager. | Very large state, larger than memory. Pays serialization cost per access but supports incremental checkpoints (only changed SSTables are uploaded). |
Keyed state is the reason a keyBy matters so much: because every record for a key always lands on the same subtask, that subtask can keep the key's state locally with no coordination. When the job is rescaled, keys are reassigned to subtasks using key groups (fixed-size buckets of the key space), so state moves in whole buckets rather than key by key.
5. Checkpointing
Checkpointing is how Flink makes stateful streaming fault-tolerant. The challenge is to snapshot the state of every operator at a point that is mutually consistent, without stopping the stream. Flink solves this with a variant of the Chandy-Lamport distributed snapshot algorithm, using special records called checkpoint barriers.
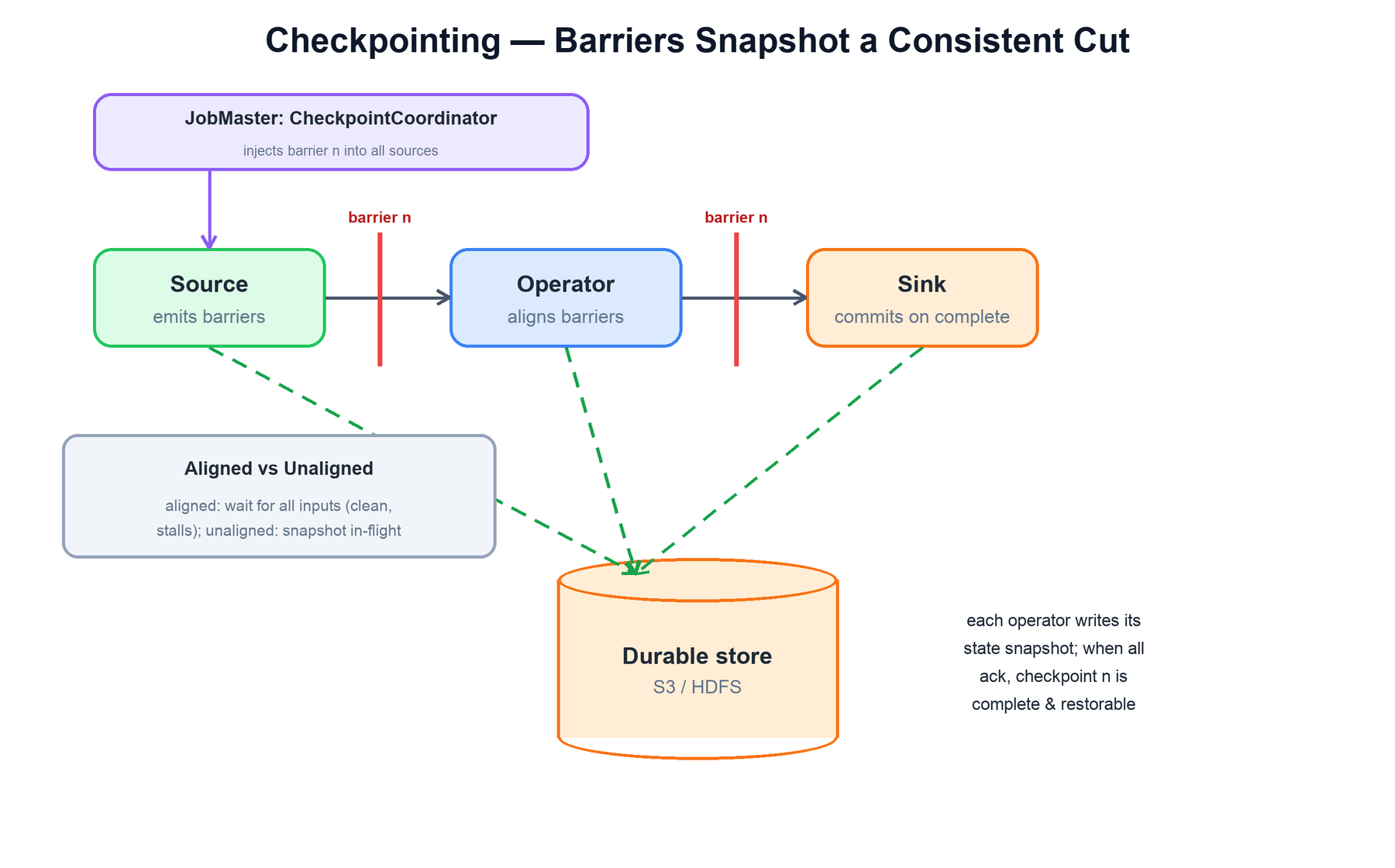
The mechanism works like this:
- The CheckpointCoordinator (inside the JobMaster) periodically injects a barrier carrying checkpoint number
ninto every source subtask. - A barrier flows through the dataflow alongside normal records, never overtaking them. When an operator has received barrier
non all of its input channels, everything before the barrier is "in" checkpointnand everything after is "out". - At that moment the operator snapshots its state to durable storage (S3, HDFS, etc.), then forwards barrier
nto its outputs and resumes processing. - When every operator — through to the sinks — has acknowledged barrier
n, the coordinator marks checkpointncomplete. Sinks that participate in exactly-once then commit their pending output.
An operator with multiple inputs cannot snapshot until it has seen the barrier on all of them. The two strategies for handling that wait are the central tradeoff in checkpointing:
| Mode | What it does | Tradeoff |
|---|---|---|
| Aligned | Once a barrier arrives on one input, that input is buffered ("aligned") until the barrier arrives on all others. Snapshot contains no in-flight data. | Cleanest snapshot, but a slow channel stalls the operator while it waits — checkpoint latency grows under backpressure. |
| Unaligned | The operator snapshots immediately and includes the in-flight records (the buffered data between barriers) in the checkpoint. | Checkpoints complete quickly even under heavy backpressure, at the cost of a larger snapshot. |
Exactly-once falls directly out of this. Recovery rewinds all operators to the same checkpoint and replays sources from the offsets stored in that checkpoint:
on checkpoint trigger (every checkpoint_interval):
coordinator.inject_barrier(n) into all sources
function on_barrier(op, n):
wait_for_barrier_on_all_inputs(op, n) # aligned mode
handle = op.snapshot_state_to(durable_store) # async upload
op.forward_barrier(n)
coordinator.ack(op, n, handle)
on failure:
cp = latest_complete_checkpoint()
for op in all_operators:
op.restore_state_from(cp.handle[op]) # consistent cut
sources.seek(cp.offsets) # replay from here
# each event now affects state exactly once6. Savepoints vs Checkpoints
Savepoints and checkpoints use the same snapshotting machinery but serve opposite purposes. Checkpoints are an automatic, internal safety net the runtime manages for failure recovery. Savepoints are a manual, user-owned snapshot taken deliberately for operational changes.
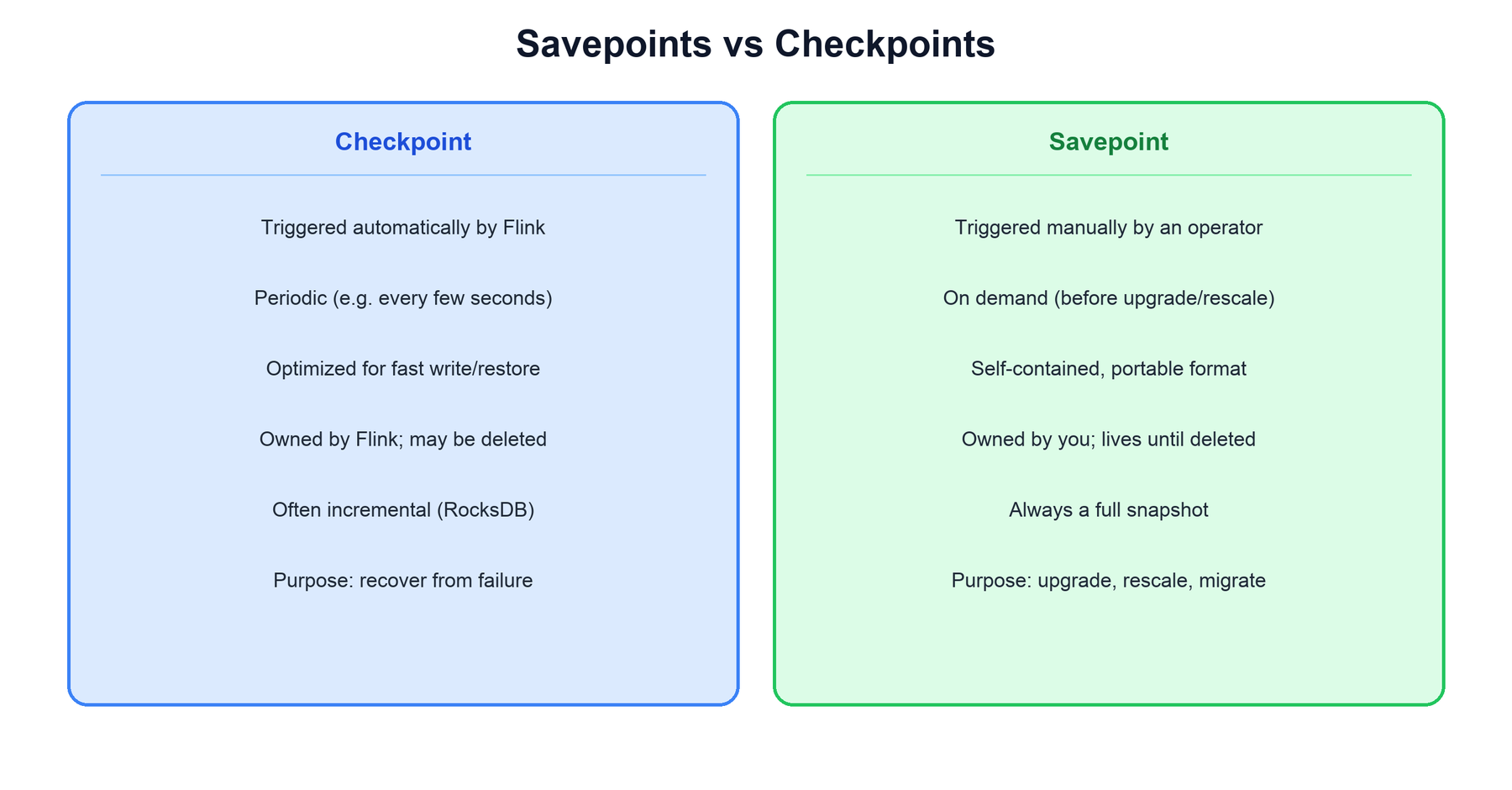
| Property | Checkpoint | Savepoint |
|---|---|---|
| Triggered by | Flink, automatically and periodically | An operator, manually and on demand |
| Lifecycle | Owned by Flink; old ones are discarded automatically | Owned by you; it persists until you delete it |
| Format | Optimized for fast write/restore; may be incremental | Self-contained, portable, always a full snapshot |
| Primary purpose | Recover from an unexpected failure | Planned stop/restart: upgrades, rescaling, migration |
Because a savepoint is a portable, complete snapshot, it is the tool for the two most common operational tasks:
- Rescaling. Stop the job with a savepoint, then restart it with a new parallelism. Flink redistributes keyed state across the new set of subtasks using key groups, so each new subtask receives exactly the keys it now owns.
- Upgrades. Deploy a new version of the job — bug fixes, new operators, a changed Flink version — by stopping with a savepoint and restoring the new program from it. Operators are matched by stable IDs so their state carries over.
# graceful upgrade or rescale
savepoint_path = flink.stop_with_savepoint(job_id) # drain + full snapshot
deploy(new_job_jar) # or change -p parallelism
flink.run(new_job_jar, from_savepoint=savepoint_path)
# keyed state repartitioned by key group; operators matched by uid7. Time and Windows
On an unbounded stream you cannot wait for "all the data" before producing a result, and events do not arrive in the order they happened — a mobile client may buffer events offline and deliver them late. Flink's answer is to compute in event time and track progress with watermarks.
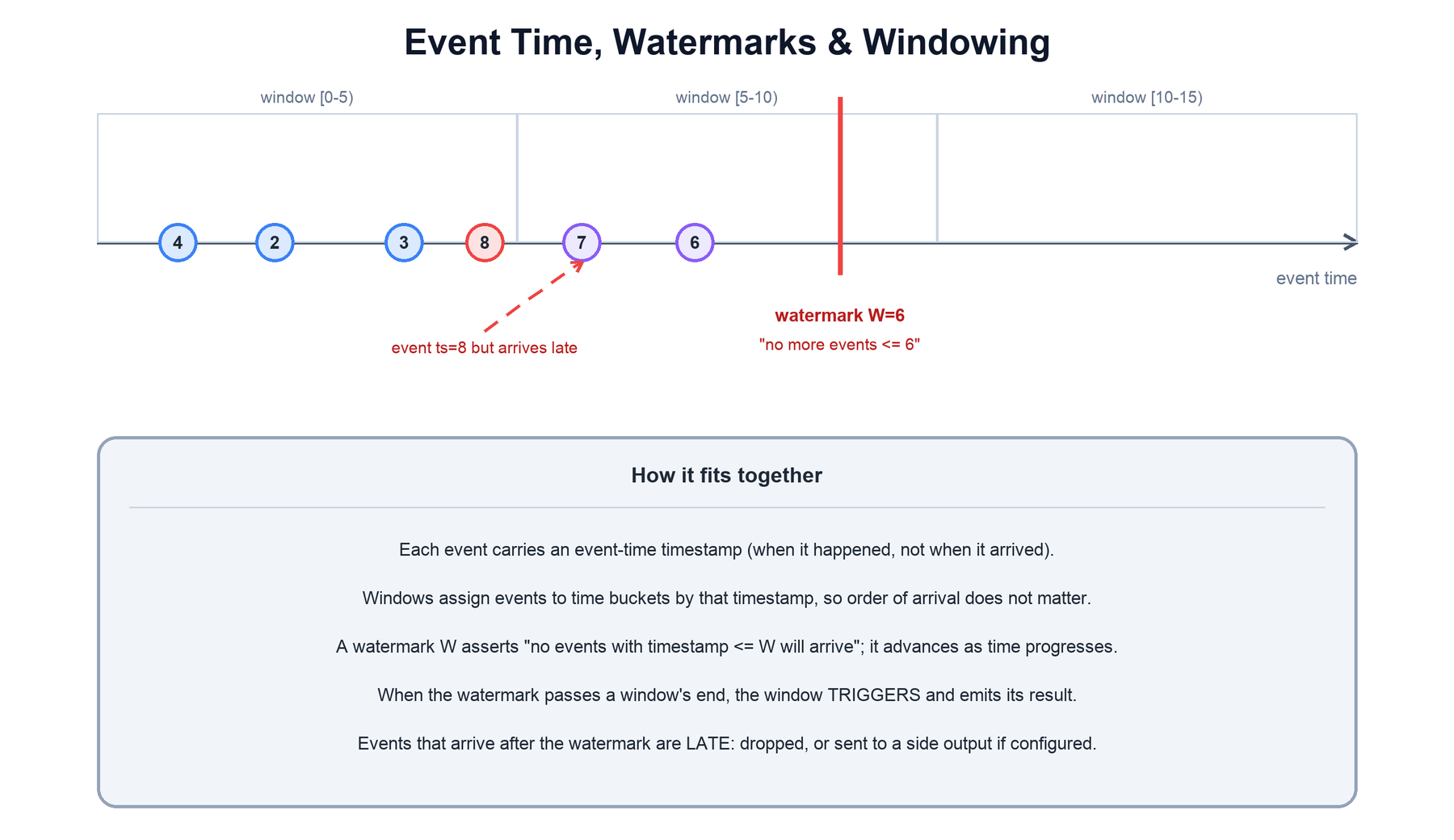
- Event time is the timestamp embedded in each record — when the event actually occurred. (Contrast with processing time, the wall-clock time at the operator, which is simpler but non-deterministic on replay.)
- Watermarks are special records that flow with the stream carrying a timestamp
W, asserting "I do not expect any more events with a timestamp ≤W." A watermark generator produces them, usually allowing a bounded amount of out-of-orderness. The watermark only advances; it is the engine's notion of how far event time has progressed. - Windows assign each record to one or more time buckets based on its event-time timestamp — for example tumbling 5-second windows. Because assignment is by timestamp, out-of-order arrival does not put an event in the wrong window.
- Triggering: a window fires and emits its result when the watermark passes the window's end. At that point Flink is satisfied that all (on-time) events for the window have arrived.
- Late data: an event whose timestamp is already below the current watermark when it arrives. By default it is dropped; with
allowedLatenessthe window can stay open a little longer, and a side output can capture truly late events for separate handling.
on event e arriving at operator:
window = assign_window(e.event_time) # by timestamp, not arrival
if e.event_time <= current_watermark:
side_output.emit(e) # LATE: window already fired
else:
window.state.add(e)
on watermark W arriving:
current_watermark = W
for w in windows where w.end <= W:
emit(trigger(w)) # fire and produce result
w.clear()The watermark is fundamentally a latency-versus-completeness dial. Allowing more lateness before emitting a watermark gives later events time to arrive (more complete results) but delays when windows fire (higher latency). A tight watermark fires sooner but risks dropping stragglers.
8. Network Shuffle and Backpressure
When subtasks are connected by a redistributing edge, records cross the network from a producer subtask to a consumer subtask. Flink moves them in buffers (batches of serialized records) rather than one record per packet, for efficiency. The interesting part is what happens when the consumer cannot keep up.
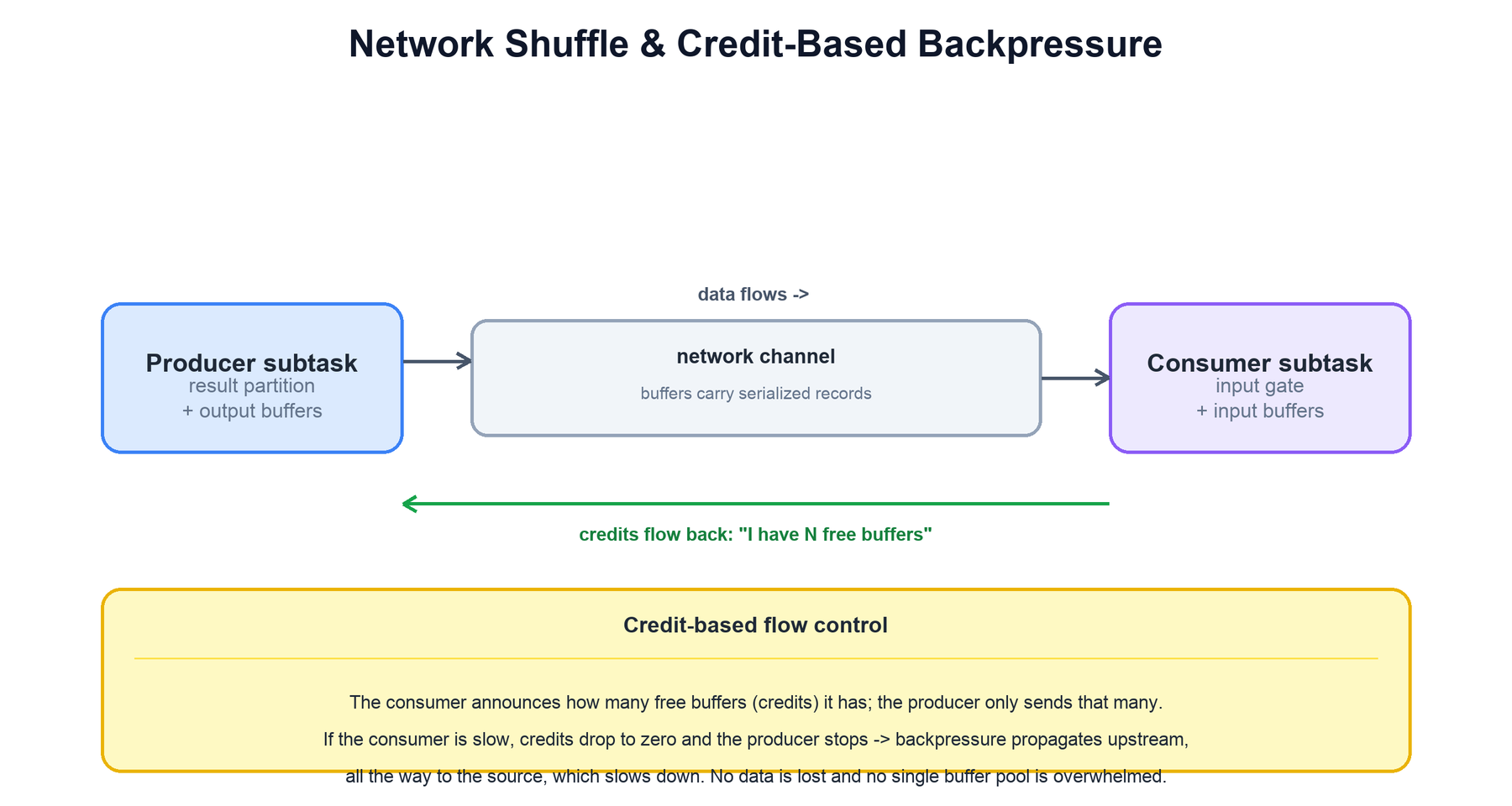
Flink uses credit-based flow control to handle this natively, with no explicit throttling logic in user code:
- Each consumer subtask has a pool of input buffers. It continuously tells the producer how many free buffers it has — these are its credits.
- The producer only sends as many buffers of data as the consumer has credits for. It never floods a channel the consumer cannot drain.
- If the consumer slows down, its free buffers fill and its credit drops toward zero. The producer, out of credits, stops sending on that channel and its own output buffers begin to fill.
- That pressure propagates upstream subtask by subtask — eventually reaching the source, which slows down its intake. The whole pipeline self-regulates to the speed of its slowest stage.
This is what backpressure means in Flink: it is not an error condition but the normal, designed mechanism that keeps a fast producer from overwhelming a slow consumer. No data is dropped, and no unbounded queue grows; the system simply runs at the rate the bottleneck allows.
function producer_send(channel, buffer):
if channel.credits == 0:
block() # backpressure: cannot send
else:
channel.transfer(buffer)
channel.credits -= 1
function consumer_loop():
while True:
buf = input_gate.next_buffer() # blocks if none ready
process(buf)
recycle(buf)
announce_credit(buf.channel, +1) # I have a free buffer again9. Summary
Flink's design is a small set of ideas that compose into correct, fault-tolerant stream processing:
| Concern | Mechanism |
|---|---|
| Who coordinates the cluster? | JobManager split into Dispatcher, ResourceManager, and a per-job JobMaster; TaskManagers provide task slots. |
| How does a program become work? | StreamGraph → chained JobGraph → parallel ExecutionGraph of subtasks deployed into slots. |
| What does an operator remember? | Keyed state (per key) and operator state (per subtask), held in a HashMap or RocksDB state backend. |
| How does state survive failure? | Chandy-Lamport barriers snapshot a consistent cut to durable storage; recovery rewinds all operators to the last checkpoint. |
| How are results correct? | Exactly-once over state, plus replayable sources and transactional/idempotent sinks for end-to-end guarantees. |
| How do upgrades and rescaling work? | Manual, portable savepoints; keyed state repartitioned by key group. |
| How is out-of-order data handled? | Event time + watermarks; windows fire when the watermark passes their end; late data dropped or side-output. |
| How does a fast stage not swamp a slow one? | Credit-based backpressure: consumers grant credits, producers only send what fits, pressure flows to the source. |