Elasticsearch — Internal Architecture
A developer's guide to how Elasticsearch actually works under the hood: the distributed layer over Lucene, node roles and cluster state, shards and routing, the inverted index, the indexing and query paths, and how near-real-time search is achieved.
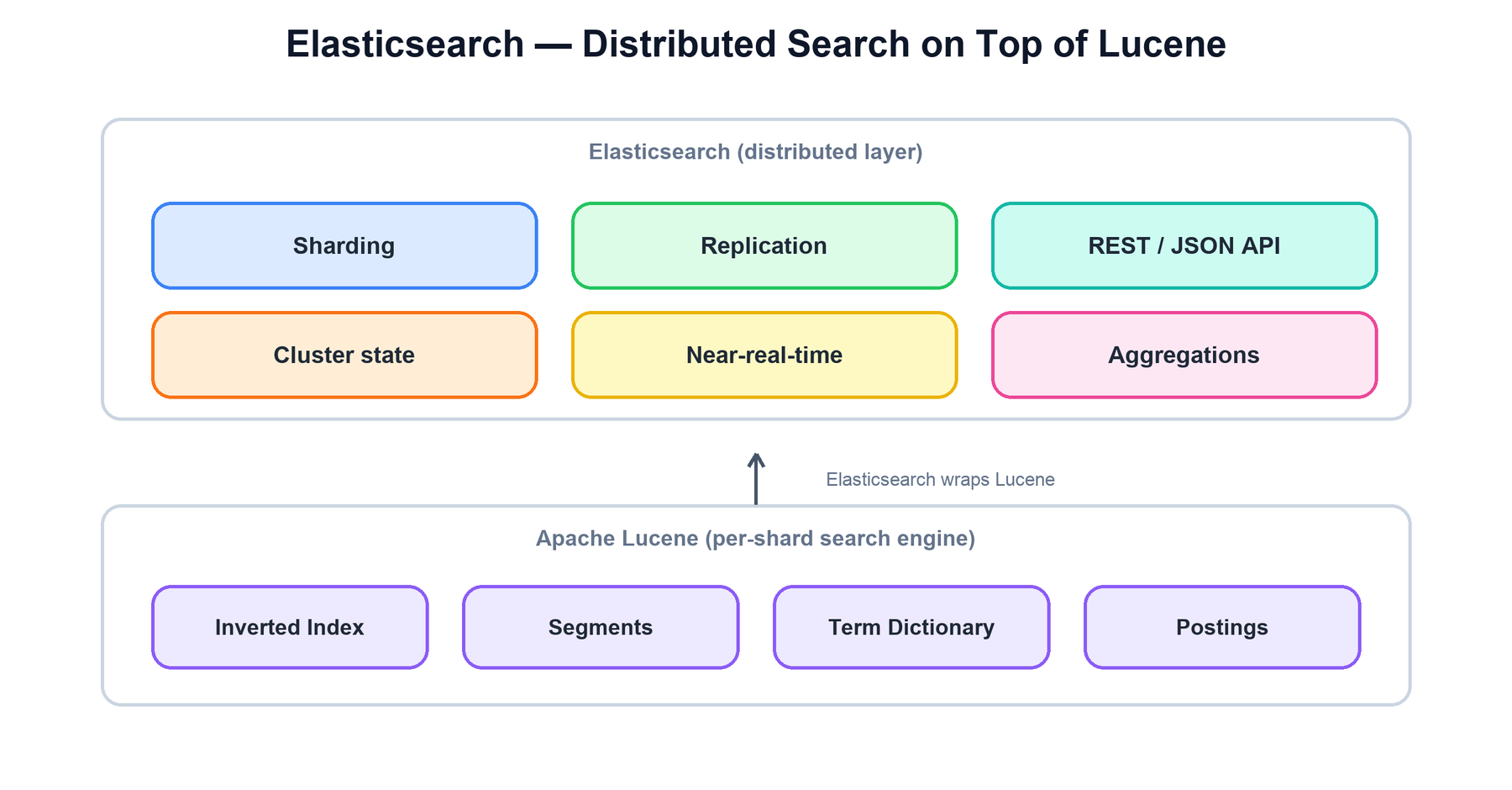
Elasticsearch is a distributed search and analytics engine built on top of Apache Lucene. Lucene is a single-machine, full-text search library: it stores an inverted index and answers term queries fast, but it knows nothing about clusters, networks, or replication. Elasticsearch wraps many Lucene indexes and adds the distributed half: it shards data across nodes, replicates each shard for safety, elects a master to manage cluster state, and exposes everything through a JSON-over-HTTP API. Understanding Elasticsearch means understanding how that distributed layer coordinates a fleet of independent Lucene engines.
Contents
1. Design Goals and Core Ideas
Every design choice in Elasticsearch follows from one ambition: take Lucene's fast single-machine full-text search and make it distributed, horizontally scalable, and near-real-time, without giving up the rich query and aggregation capabilities developers expect.
| Goal | How Elasticsearch achieves it |
|---|---|
| Full-text search at scale | Each shard is a self-contained Lucene index with an inverted index; queries run in parallel across shards. |
| Horizontal scalability | An index is split into shards spread across data nodes. Add nodes and shards relocate to use the new capacity. |
| High availability | Every primary shard has one or more replicas on other nodes. Lose a node and a replica is promoted. |
| Near-real-time | New documents become searchable within a refresh interval (about one second), not instantly, trading a little latency for throughput. |
| Analytics, not just search | Doc-values columnar storage and aggregations let the same engine compute metrics, histograms, and facets. |
2. Cluster Architecture and Node Roles
An Elasticsearch cluster is a set of nodes that share a cluster name. Unlike a fully peer-to-peer system, Elasticsearch has an elected master that owns the cluster's metadata. The master does not sit in the data path — it manages the cluster state: the list of nodes, index mappings and settings, and which shard lives on which node. Every node holds a copy of the cluster state, and the master publishes updates to all of them.
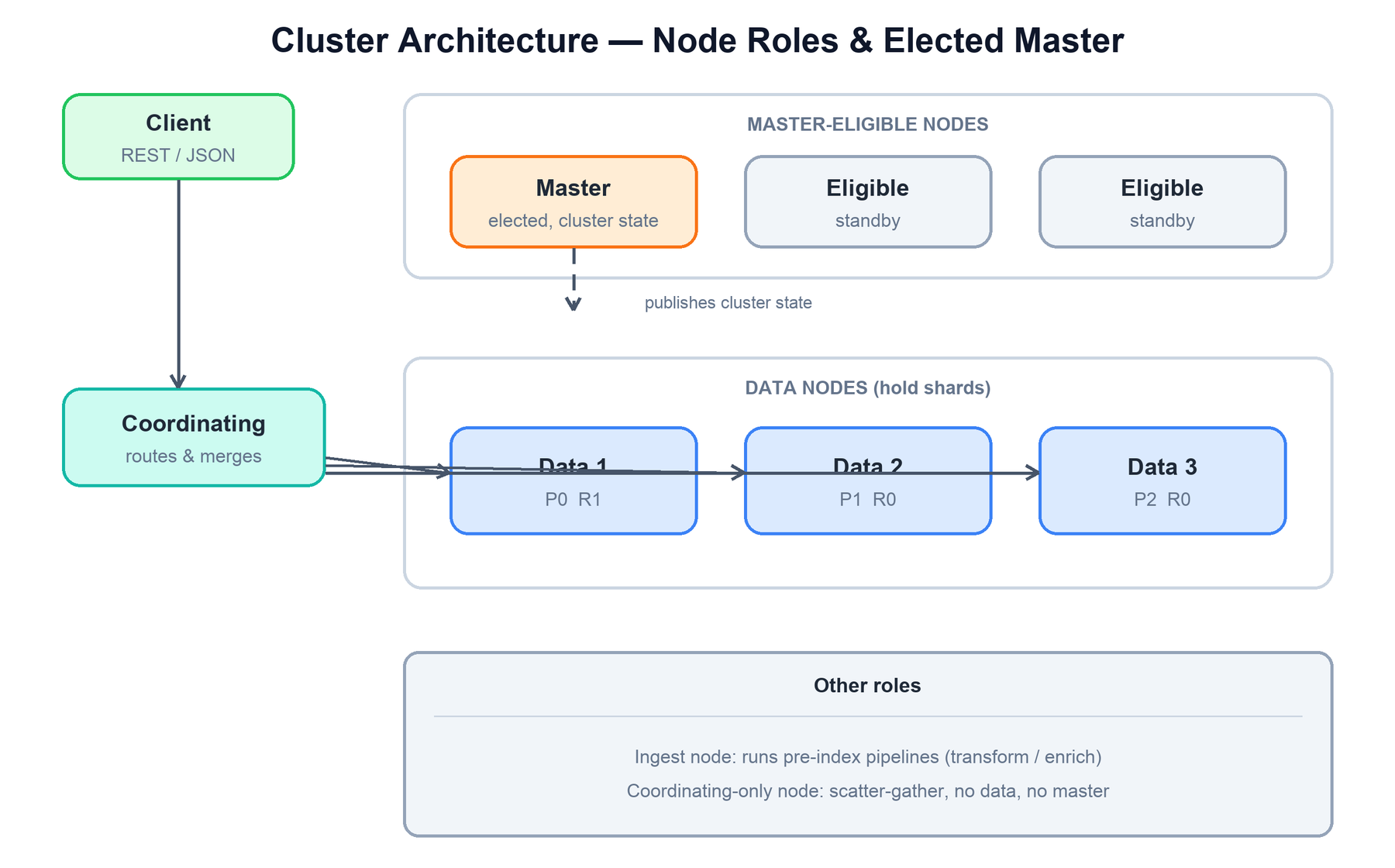
Nodes are configured with one or more roles:
- Master-eligible: can be elected master. The cluster elects exactly one active master from this pool. The master applies cluster-state changes — creating indices, allocating shards, processing node joins and departures — and publishes the new state. Master-eligible nodes form a voting configuration; a quorum of them must agree to elect a master and to commit each state change.
- Data: holds shards (primaries and replicas) and does the actual indexing and searching. This is where Lucene runs and where disk and memory pressure live.
- Coordinating: a role every node can play. The node that receives a client request becomes the coordinating node for it: it routes sub-requests to the right shards, gathers responses, merges them, and replies. A node with no other roles is a dedicated coordinating-only node — a smart load balancer.
- Ingest: runs ingest pipelines that transform or enrich documents before they are indexed (parsing, field renaming, lookups), offloading that work from data nodes.
Discovery is how nodes find each other and form the cluster. On startup a node contacts a configured list of seed hosts, learns about other master-eligible nodes, and participates in master election. Once a master is elected, it admits new nodes by adding them to the cluster state and publishing it. Failure detection runs continuously: the master pings the other nodes and they ping the master; a node that stops responding is removed from the cluster state, and the master reallocates its shards.
3. Indices, Shards and Routing
An index is a logical collection of documents (for example, all your logs). Physically, an index is split into primary shards, and each primary can have one or more replica shards. A shard is a complete, independent Lucene index. Splitting an index into shards is what lets a single index outgrow one machine and lets queries run in parallel.
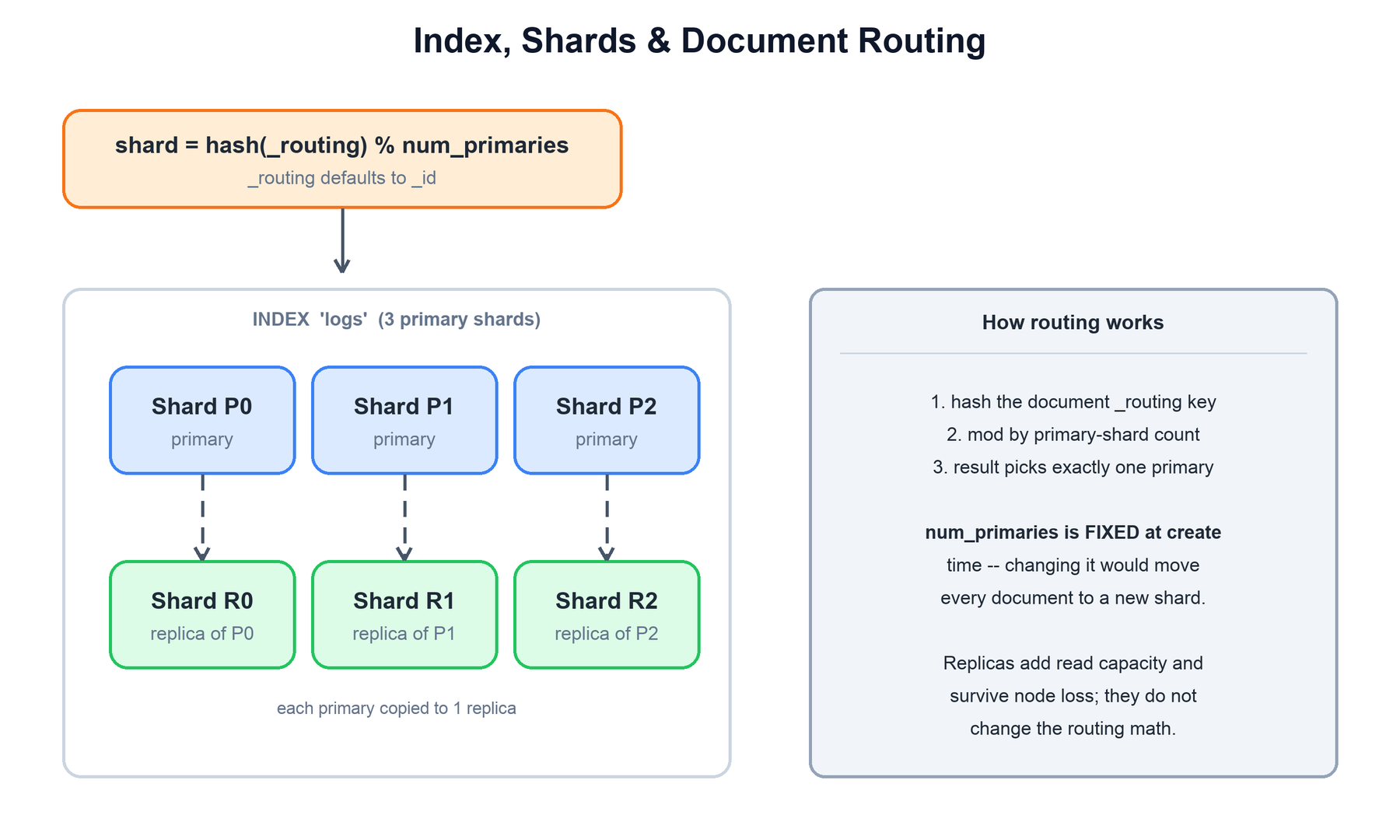
Which shard does a document go to? Elasticsearch routes it deterministically:
function route(document):
routing = document._routing or document._id # default routing key is the doc id
shard = hash(routing) % num_primary_shards # pick exactly one primary
return shardTwo consequences matter in practice. First, the same key always lands on the same shard, so a get-by-id or a routed query touches only one shard. Second, num_primary_shards is fixed when the index is created — it is in the denominator of the routing formula, so changing it would relocate nearly every document. (Elasticsearch offers explicit split and shrink operations that rebuild the index when you genuinely need a different primary count.)
Replicas do not change the routing math. A replica is a byte-for-byte copy of its primary on a different node. Replicas serve two purposes: they take over if the node holding the primary fails (a replica is promoted to primary), and they add read throughput because searches can run against either the primary or a replica.
4. Lucene Internals: The Inverted Index
At the bottom of every shard is Lucene, and at the heart of Lucene is the inverted index. A forward index maps a document to its words; an inverted index maps each term to the list of documents that contain it (the postings list). That inversion is what makes "find every document containing fox" a single dictionary lookup instead of a scan.
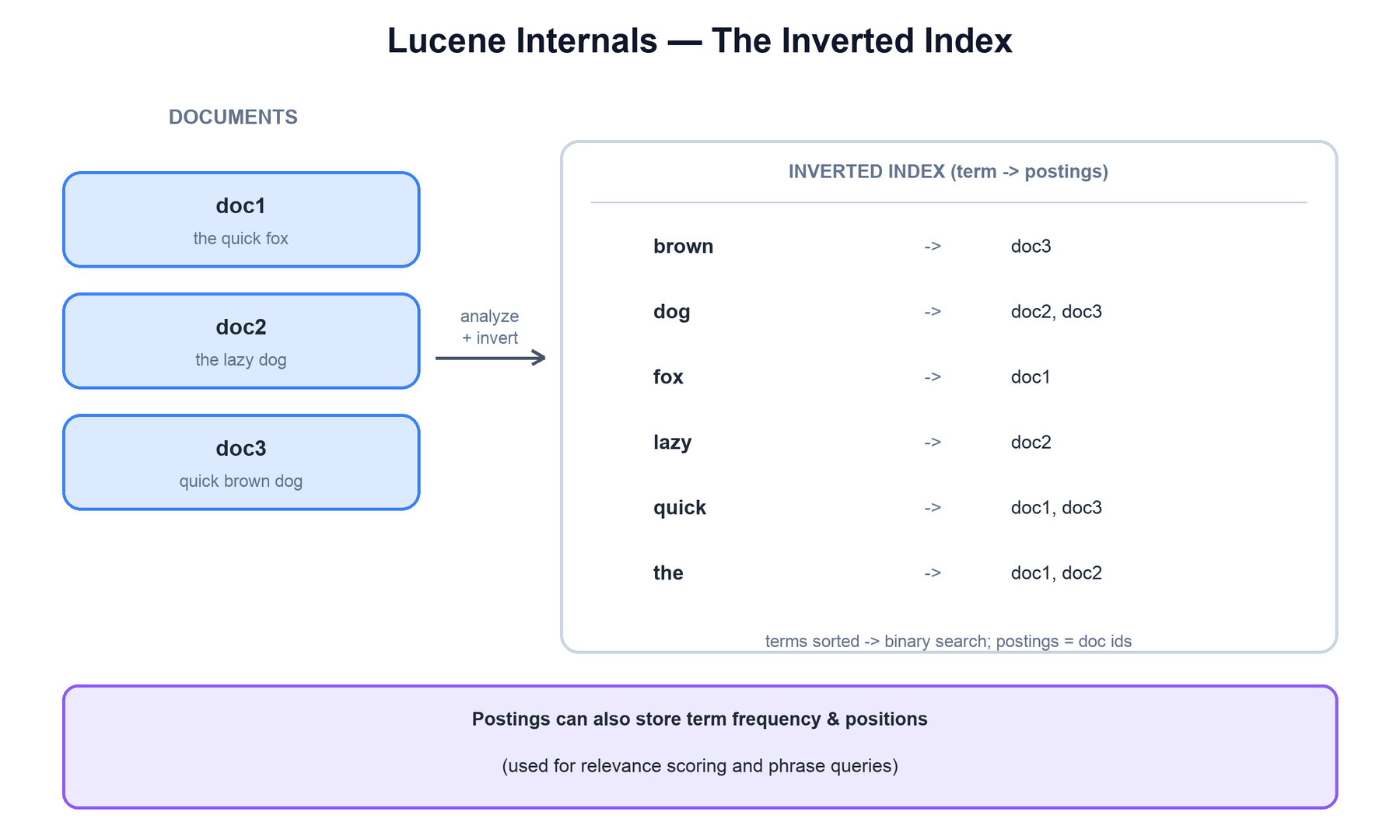
Lucene stores this efficiently:
- Term dictionary: the sorted set of all unique terms in a field. Because it is sorted, Lucene can binary-search it and supports range and prefix queries cheaply.
- Postings: for each term, the list of document ids that contain it, often with the term frequency and the positions of each occurrence. Frequencies feed relevance scoring; positions enable phrase and proximity queries.
- Segments: a Lucene index is not one big file. It is a set of immutable segments, each a small, self-contained inverted index. New documents go into new segments; existing segments are never modified. Immutability is the key trick — a segment needs no locking, can be cached aggressively, and is safe to read concurrently.
Because segments are immutable, a delete cannot remove a document in place. Instead Lucene records the doc id in a per-segment deleted-documents bitset and filters it out of results. An update is just a delete plus a fresh insert. The space is reclaimed later, during merge.
5. Indexing Path
When a document arrives at the primary shard, Elasticsearch must make it both durable (survive a crash) and eventually searchable, while keeping the write fast. It does this with an in-memory buffer plus a write-ahead log called the translog, and two background events: refresh and flush.
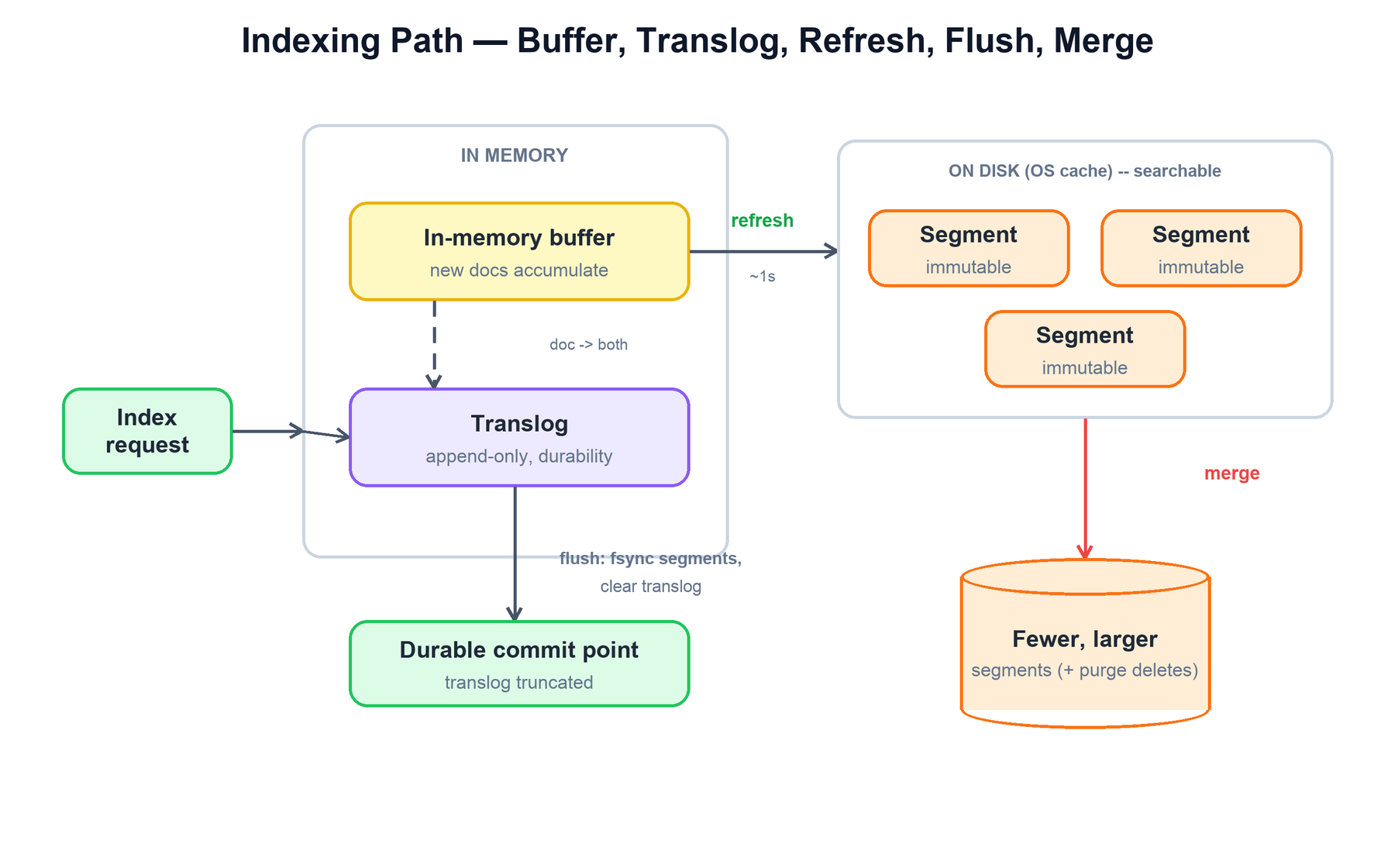
The stages are:
- Buffer + translog. The document is added to an in-memory buffer and, for durability, appended to the translog on disk. The write is acknowledged once the translog write is safe. The document is durable but not yet searchable.
- Refresh. Periodically (default every second) the buffer is turned into a new Lucene segment and that segment is opened for search. This is when the document becomes visible to queries. Refresh does not fsync, so it is cheap; the new segment lives in the OS file cache.
- Flush. Less often, Elasticsearch performs a Lucene commit: it fsyncs the segments to disk, writes a commit point, and truncates the translog. After a flush, the operations recorded in the translog are safely on disk, so the translog can be cleared.
- Merge. Refreshes produce many small segments. A background merge process combines them into fewer, larger segments, and in doing so physically drops documents marked deleted. Merging keeps the number of segments — and therefore search cost — under control.
function index(doc):
buffer.add(doc) # 1. in-memory, not yet searchable
translog.append(doc) # 1. durability (write-ahead log)
ack() # acknowledged once translog is safe
every refresh_interval: # 2. ~1s
segment = buffer.to_segment()
open_for_search(segment) # now searchable; no fsync yet
buffer.clear()
on flush: # 3. periodic Lucene commit
fsync(all_segments)
write_commit_point()
translog.truncate() # ops are durable in segments now
background: # 4. merge
merge_small_segments() # fewer files; purge deleted docsThe translog is what bridges the gap between durability and searchability: a document is durable the moment it is in the translog, even though it will not appear in search results until the next refresh, and its segment will not be fsynced until the next flush. On restart after a crash, Elasticsearch replays the translog to recover any operations that had not yet been flushed.
6. Near-Real-Time Search
Elasticsearch is near-real-time, not real-time. A freshly indexed document is not instantly searchable; it becomes visible only after the next refresh. The reason is structural: searches run against Lucene segments, and a document is not in any segment until refresh builds one from the in-memory buffer.
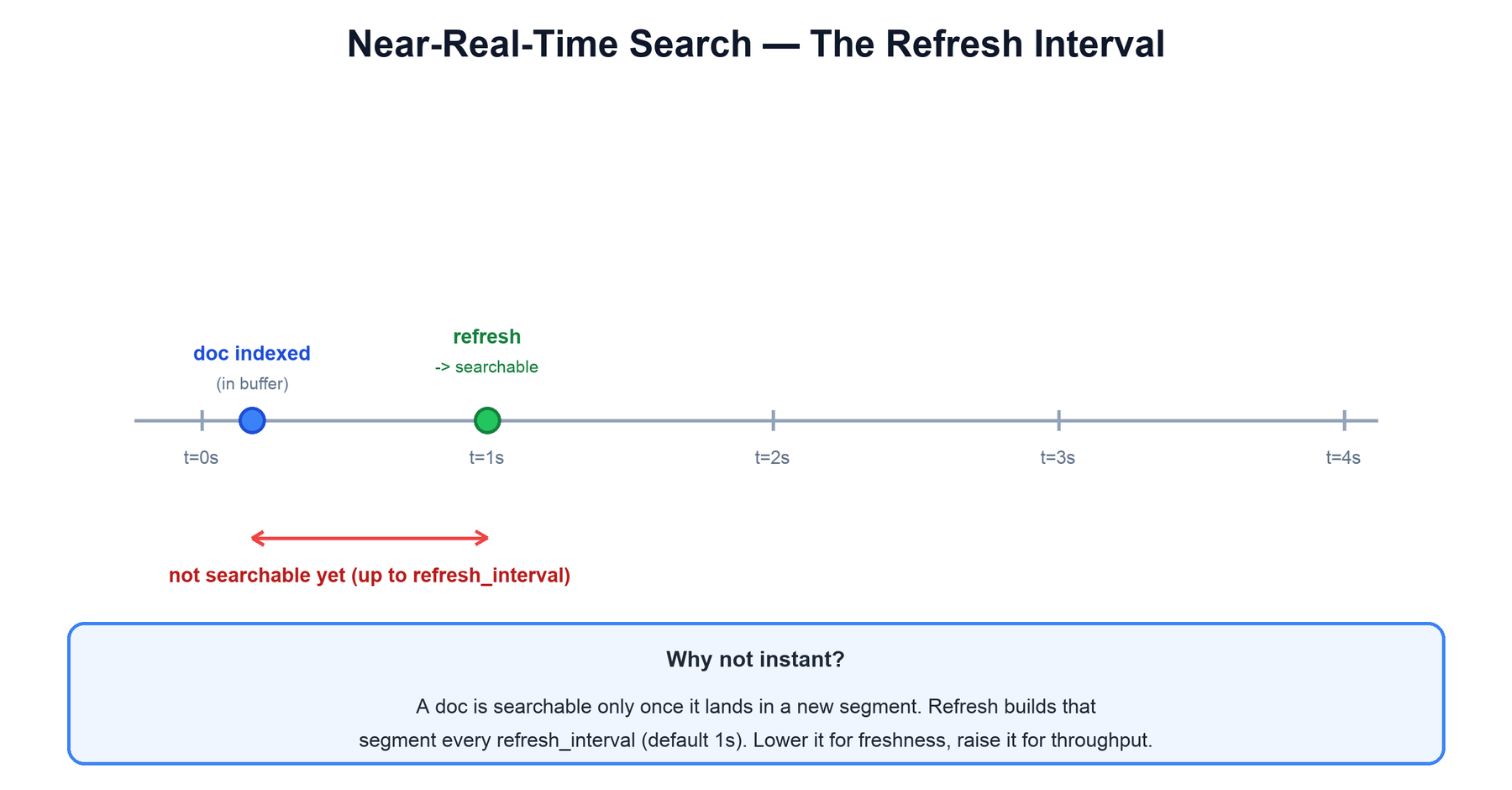
The refresh_interval setting controls the trade-off:
- Lower it (or call refresh explicitly) for fresher results — at the cost of producing more small segments and more merge work.
- Raise it, or disable refresh entirely, during heavy bulk indexing to maximize throughput, then refresh once at the end. Bulk loads run dramatically faster this way.
This is a deliberate design choice. Making every document instantly searchable would mean committing a tiny segment per document, which would crush indexing throughput and flood the merge process. By batching new documents into a segment once per interval, Elasticsearch amortizes that cost. The translog still guarantees durability in the meantime, so "not yet searchable" never means "not yet safe."
7. Replication Model
Elasticsearch replicates each shard with a primary-backup model. All writes for a shard go to its primary first; the primary then forwards them to the replicas. This is different from Cassandra's quorum model — there is a designated primary that orders the writes, which gives Elasticsearch a clear, single source of truth for each shard.
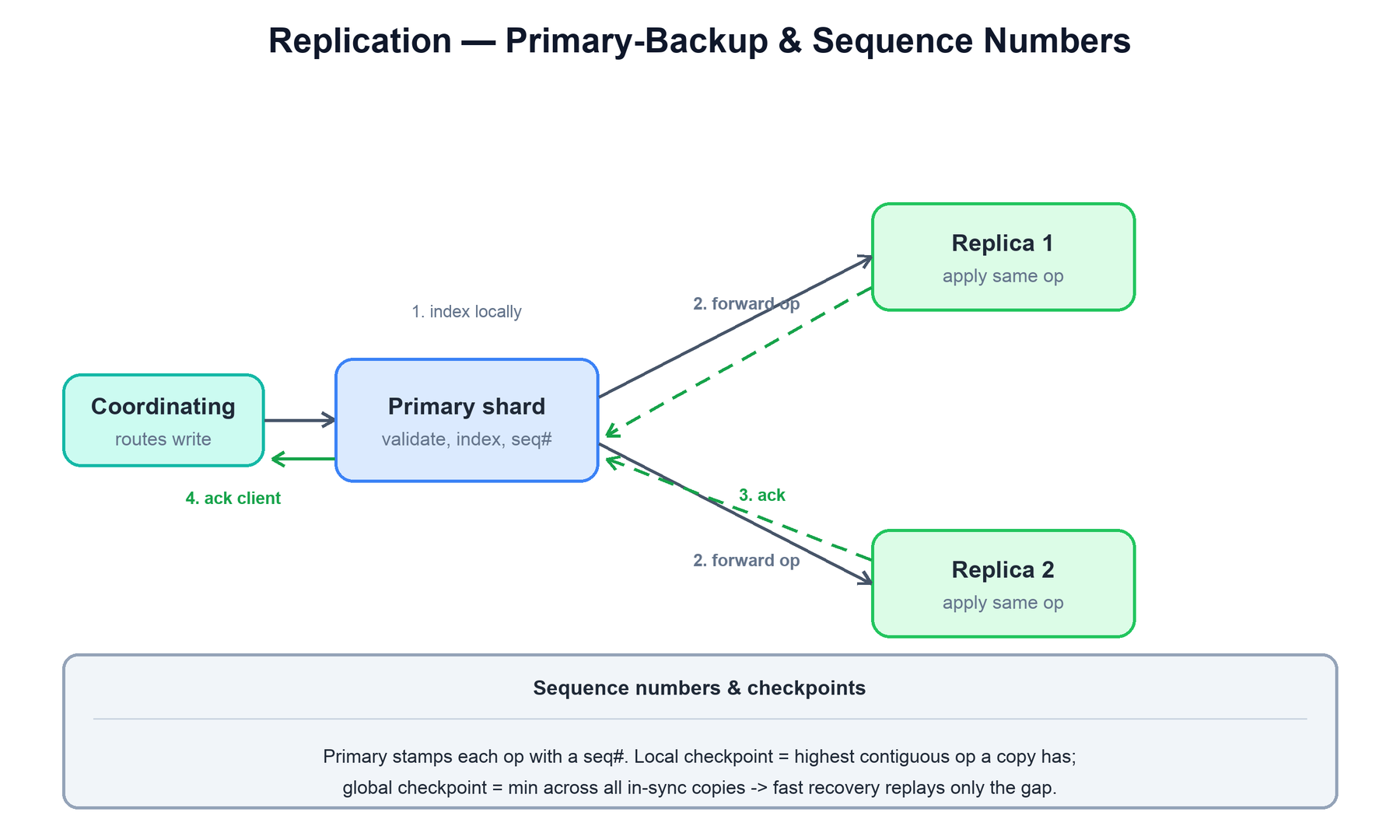
The write sequence for a single document is:
function replicate_write(doc):
primary.validate(doc)
primary.index(doc) # 1. apply locally, assign a seq#
for replica in in_sync_replicas:
send(replica, op = doc, seq = seq_no) # 2. forward the same operation
wait_for_replica_acks() # 3. replicas apply and ack
return ack_to_client() # 4. ack once replicas confirmTwo bookkeeping concepts keep replicas in step and make recovery cheap:
| Concept | What it is |
|---|---|
| Sequence number | The primary stamps every operation with a monotonically increasing seq#, so every copy can tell exactly which operations it has applied and in what order. |
| Local checkpoint | Per shard copy: the highest seq# below which that copy has applied every operation with no gaps. |
| Global checkpoint | The minimum local checkpoint across all in-sync copies. Every operation at or below it is guaranteed present on all in-sync copies. |
When a replica rejoins after a brief outage, it does not copy the whole shard. It compares checkpoints with the primary and replays only the operations after its checkpoint from the translog — a fast recovery of just the gap. The set of in-sync copies is tracked in the cluster state; a replica that falls too far behind is dropped from that set and must do a full file-based recovery instead.
8. Query Path
A search must consult every shard of the index, because any shard could hold a matching document. The coordinating node fans the query out to the shards (scatter) and combines their answers (gather). To avoid shipping full documents from every shard, Elasticsearch splits a search into two phases: query-then-fetch.
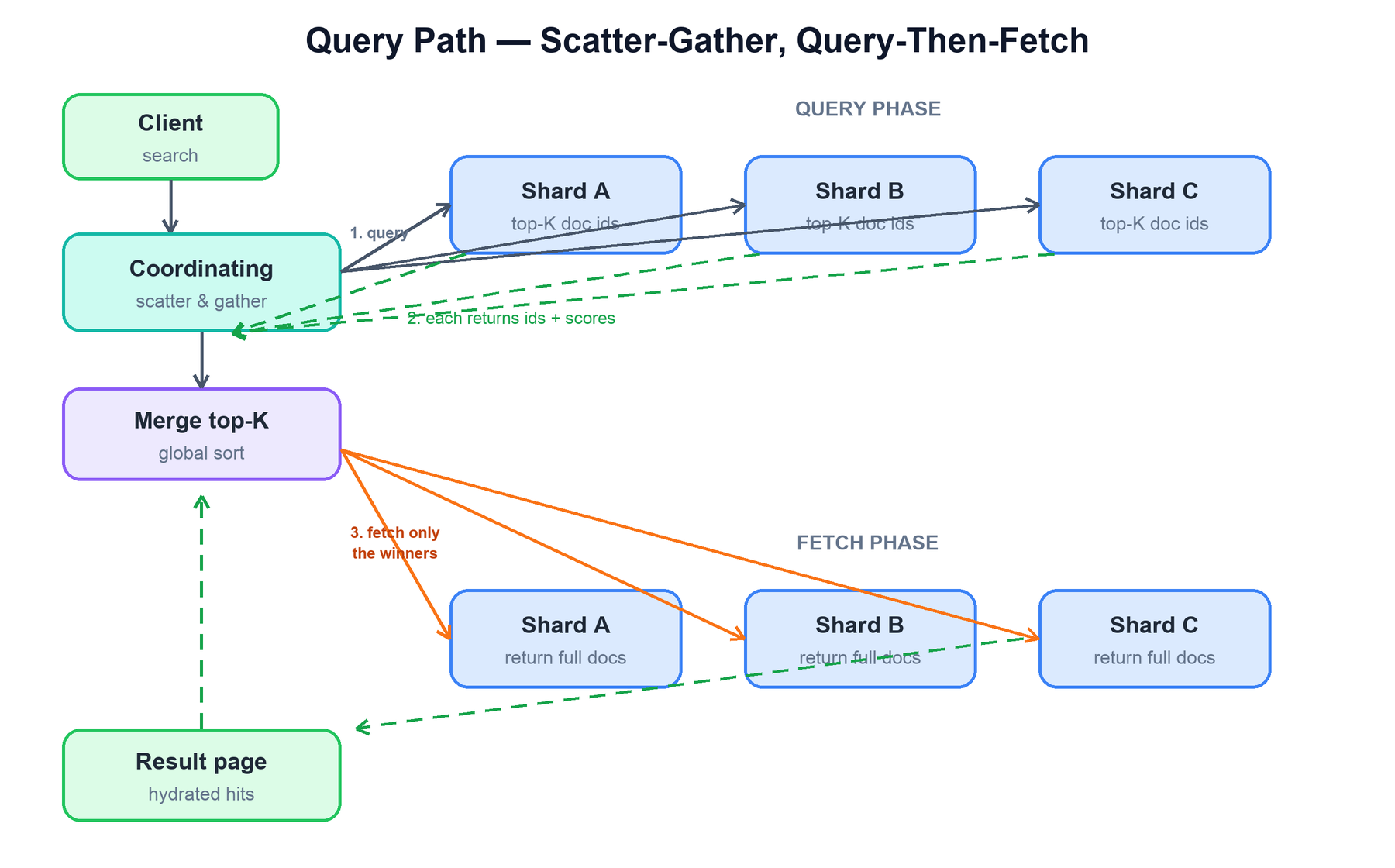
- Query phase. The coordinating node sends the query to one copy (primary or replica) of every shard. Each shard runs the query against its own Lucene index and returns just the top-K document ids and their scores — not the documents themselves. The coordinating node merges these partial lists and sorts them to find the true global top-K.
- Fetch phase. Now the coordinating node knows exactly which documents make the final page. It asks the relevant shards to return the full source for only those documents, hydrates the hits, and replies to the client.
function search(query, size):
# --- query phase: scatter ---
for shard in index.shards:
copy = pick_copy(shard) # primary or a replica
partial[shard] = copy.query(query, top = size) # ids + scores only
top_ids = merge_and_sort(partial)[:size] # global top-K
# --- fetch phase: gather full docs ---
for id in top_ids:
docs.add(shard_of(id).fetch(id)) # retrieve only the winners
return docsThe reason for two phases is bandwidth. If each shard returned full documents, the coordinating node would receive shards × size documents and throw most of them away. Returning lightweight ids and scores first, then fetching only the final winners, keeps the network cost proportional to the page size, not to the shard count. This is also why deep pagination is expensive: to return page 1000, every shard must still rank and return the top (page × size) ids for the coordinating node to merge.
9. Analysis: Turning Text Into Terms
Before text can go into an inverted index, it must be broken into terms. That job belongs to an analyzer, a pipeline of three stages applied in order.
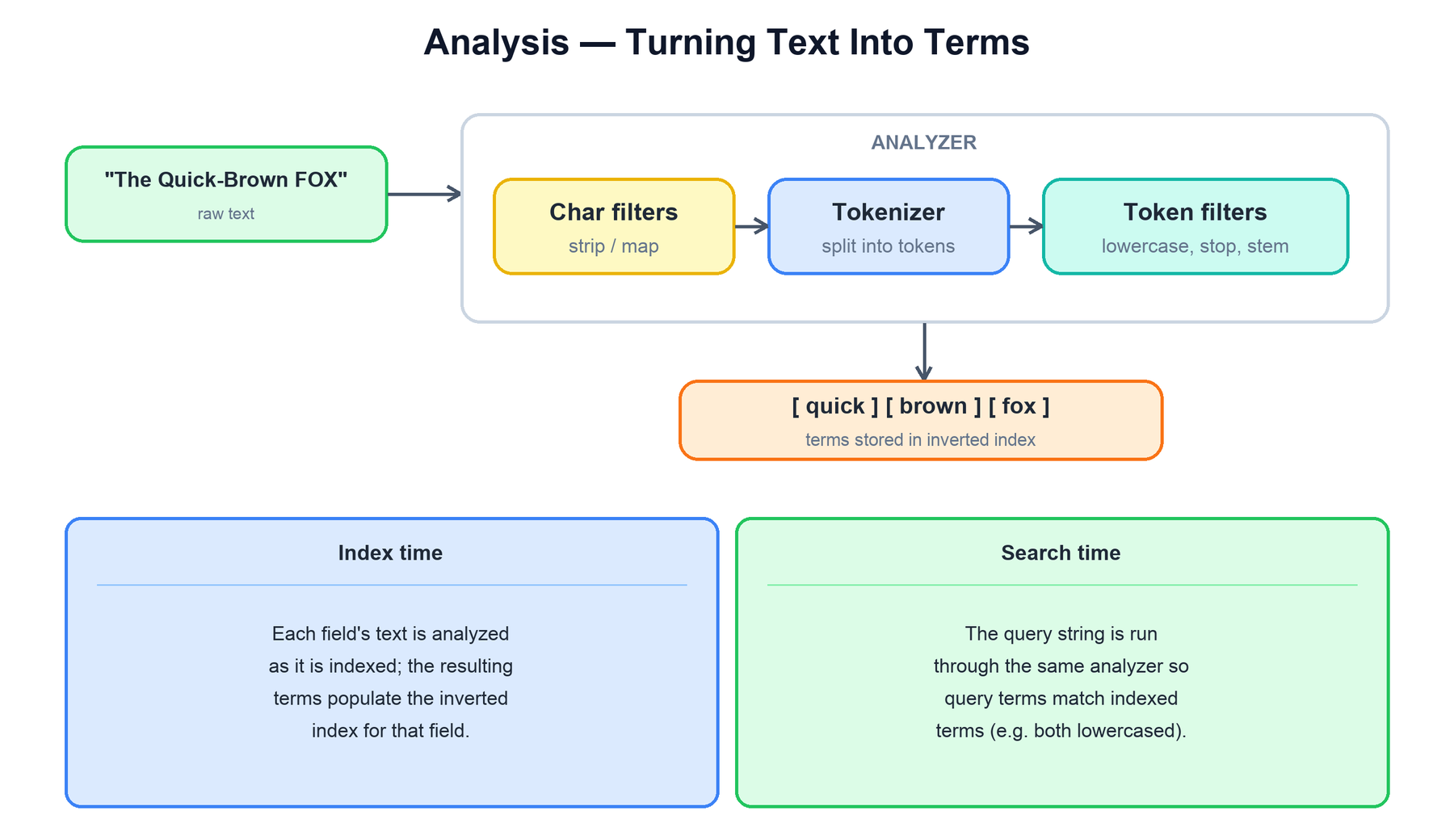
| Stage | What it does | Example |
|---|---|---|
| Character filters | Pre-process the raw string before tokenizing. | Strip HTML tags; map & to "and". |
| Tokenizer | Split the stream into tokens. | Standard tokenizer breaks on whitespace and punctuation: "Quick-Brown" → "Quick", "Brown". |
| Token filters | Transform, add, or drop tokens. | Lowercase; remove stop words; stem "running" → "run". |
The subtle but crucial point is that analysis happens at two times, and they must agree:
- Index time: when a document is indexed, each text field is analyzed and the resulting terms populate that field's inverted index.
- Search time: when a full-text query runs, the query string is passed through the same analyzer so that query terms are normalized the same way as the indexed terms.
If the two used different analyzers, matches would silently fail. Index "FOX" as the lowercased term fox but search for the unanalyzed term FOX, and there is no match. Using the same analyzer on both sides — lowercasing, stemming, and stop-word removal applied identically — is what makes a search for "the Foxes" find a document that said "fox." (Fields meant for exact matching, like ids or tags, use the keyword type, which skips analysis and stores the value verbatim.)
10. Summary
Elasticsearch is best understood as a thin-but-clever distributed layer over many Lucene engines. The pieces reinforce each other:
| Concern | Mechanism |
|---|---|
| What does the searching? | Per-shard Lucene inverted indexes made of immutable segments. |
| Who manages the cluster? | An elected master owns and publishes the cluster state; it stays out of the data path. |
| Where does a document live? | shard = hash(_routing) % num_primaries; primary count is fixed at create time. |
| How is it durable yet fast? | In-memory buffer + translog; acknowledge on translog write, fsync later on flush. |
| Why not instant search? | Documents are searchable only after refresh builds a new segment (about one second). |
| How are copies kept safe? | Primary-backup replication with sequence numbers and local/global checkpoints for fast recovery. |
| How does a search work? | Coordinating node scatter-gathers; query phase finds ids, fetch phase retrieves the winners. |
| How does text become searchable? | Analyzers (char filters → tokenizer → token filters) at both index and search time. |