Designing a Distributed Lock
A system design interview guide to mutual exclusion and single-leader selection across many machines — making sure that only one process at a time holds a lock or acts as the leader, even when nodes crash, pause, or get cut off from the network.
On a single machine, mutual exclusion is a solved problem: the operating system gives you a mutex, and the hardware guarantees that only one thread holds it. Spread the same job across many machines and that guarantee evaporates. There is no shared memory to put the mutex in, the machines can fail independently, and their clocks do not agree. A distributed lock tries to recreate "only one holder at a time" on top of that hostile environment, and a closely related problem — leader election — is just the special case of "exactly one machine should be in charge." This guide explains why these are genuinely hard, builds a lock from a store with a lease, adds fencing tokens to make it safe, walks through the famous pitfalls of naive lock implementations, and then covers leader election and split-brain avoidance.
Contents
1. Why It Is Hard
The difficulty of distributed locking comes from three facts about distributed systems that simply are not true on one machine. Any design that ignores them will look correct in a demo and corrupt data in production.
- No shared memory. There is no single piece of RAM that all the machines can compare-and-swap on. The "lock" has to live in some external service that everyone agrees to consult, which means acquiring it is a network call that can be slow, lost, or duplicated.
- Partial failure. A node that holds the lock can crash, hang, or be partitioned away at any instant — and the rest of the system cannot tell the difference between "the holder is dead" and "the holder is just slow." If you wait forever for a dead holder, the system stalls; if you assume it is dead too eagerly, you may hand the lock to a second holder while the first is still alive.
- Clock skew. Machines disagree about what time it is, and clocks can jump (NTP corrections, virtualization pauses). Any scheme that relies on different machines having the same notion of "now" — including naive timeouts — is fragile.
Put together, these mean you can never build a distributed lock that is simultaneously perfectly safe and perfectly live. The honest goal is a lock that is safe by construction — it never lets two holders both successfully mutate the protected resource — and reasonably live, recovering automatically when a holder dies. The mechanisms in the rest of this guide are all in service of that "safe even under partial failure" property.
2. A Lock with a Lease
The first building block is to put the lock in a shared store (a key-value store, a database, a coordination service) and give it a lease: a time-to-live after which the lock automatically expires. A client acquires the lock by atomically creating a key only if it does not already exist, with a TTL attached. If the holder dies without releasing, the key expires on its own and the lock becomes available again — no human has to clean up after a crashed process.
The lease is what makes the lock live in the face of partial failure. Without it, a holder that crashes would keep the lock forever and the whole system would deadlock. The TTL is, in effect, the system's answer to "how long do we wait before assuming the holder is dead?" Set it too short and a slow-but-alive holder loses its lock; set it too long and recovery after a real crash is sluggish. There is no perfect value, which is exactly why the lease alone is not enough for safety — and why fencing tokens, covered next, are needed.
# acquire: atomic create-if-absent with a TTL lease
function acquire(lock_key, owner_id, ttl):
ok = store.set_if_absent(lock_key, owner_id, expire=ttl)
return ok # true only if we created the key
function release(lock_key, owner_id):
if store.get(lock_key) == owner_id: # only release our own lock
store.delete(lock_key)3. Fencing Tokens
The lease keeps the system live, but it does not keep it safe. Consider the worst case: a client acquires the lock, then suffers a long pause (a stop-the-world GC, a hypervisor freeze) that outlasts the TTL. The lock expires, a second client acquires it legitimately, and then the first client wakes up — still convinced it holds the lock — and writes to the protected resource. Now two writers have both believed they were the sole holder, and the data is corrupt. No timeout tuning fixes this, because the first client's pause can always exceed any TTL you choose.
The robust fix is a fencing token: every time the lock is granted, the lock service also hands out a number that strictly increases with each grant. The client must include its token on every write to the protected resource, and the resource must reject any write whose token is lower than the highest it has already accepted. The paused client wakes up holding an old, smaller token; its write is refused; the newer holder's larger token wins. Safety no longer depends on clocks or on the holder noticing its lease expired — it depends only on a monotonic counter, which is easy to reason about and easy to make correct.
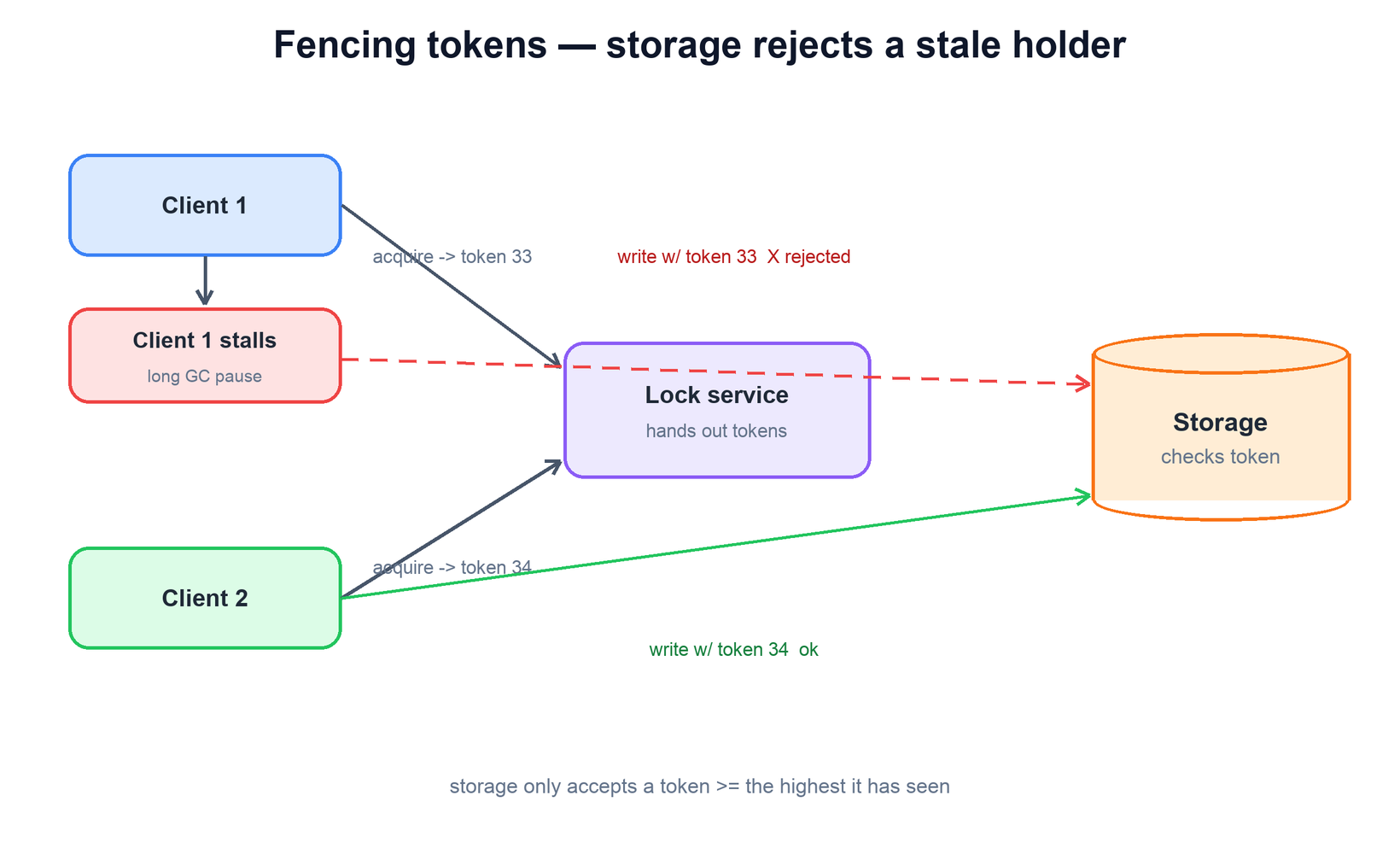
# storage enforces monotonic fencing tokens
function write(resource, data, token):
if token < resource.highest_token_seen:
reject("stale token") # a newer holder exists
resource.highest_token_seen = token
resource.apply(data) # safe: we hold the latest grant4. Naive Locks and Redlock
A very common interview answer is "just use a single Redis key with SET key value NX PX ttl." That is a fine starting point and works for the happy path, but it has two well-known weaknesses. First, on a single Redis node the lock is only as durable as that node — if the primary fails over to a replica that had not yet received the lock write, two clients can hold the "lock" at once. Second, and more fundamentally, a single-key lock provides no fencing token, so it cannot survive the paused-holder scenario from the previous section.
The Redlock algorithm was proposed to address the durability gap by acquiring the lock on a majority of several independent Redis nodes, so the loss of any one node does not lose the lock. Redlock then became the subject of a famous debate. Critics argued that it still relies on bounded clock drift and bounded pauses for its safety guarantee, and that a lock used to protect a resource must be backed by fencing tokens regardless of how many nodes you spread it across — at which point the multi-node ceremony buys you little for correctness. The practical takeaway for an interview is not which side won, but the underlying lesson:
- A lock store gives you liveness and convenience, not safety on its own.
- Safety comes from fencing at the protected resource, not from the lock implementation.
- If you genuinely need correctness under failures, prefer a system designed for it (a consensus-based coordination service) over a lock bolted onto a cache.
5. Renewal and Heartbeats
A fixed TTL forces an awkward tradeoff: long-running work needs a long lease, but a long lease means slow recovery after a crash. The way out is lease renewal. The holder runs a background heartbeat that periodically extends the lease while it is still alive and making progress, so you can keep the TTL short (fast recovery) while still supporting work that runs much longer than one TTL.
The heartbeat is also how the system detects death. As long as renewals keep arriving, the holder is presumed alive and keeps the lock. The instant they stop — because the holder crashed, hung, or was partitioned — no further extensions occur, the lease runs out, and the lock is freed for someone else. This same heartbeat-or-expire pattern is exactly what leader election uses, which is why the two topics are so closely linked.
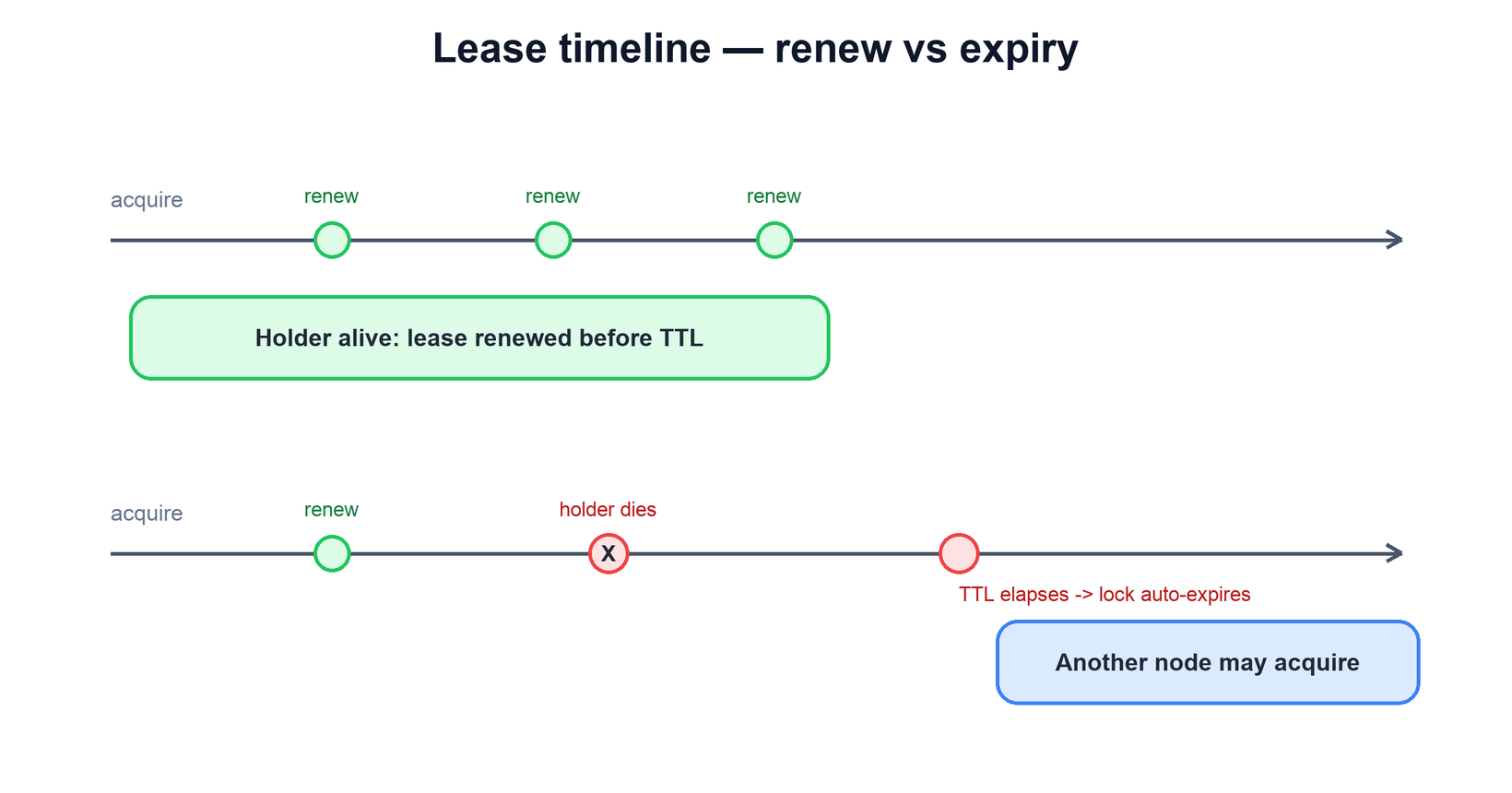
# background heartbeat keeps a short lease alive while we work
function heartbeat_loop(lock_key, owner_id, ttl):
while still_working:
sleep(ttl / 3) # renew well before expiry
ok = store.extend(lock_key, owner_id, ttl)
if not ok: # we lost the lock
stop_work() # do not keep mutating
break6. Leader Election
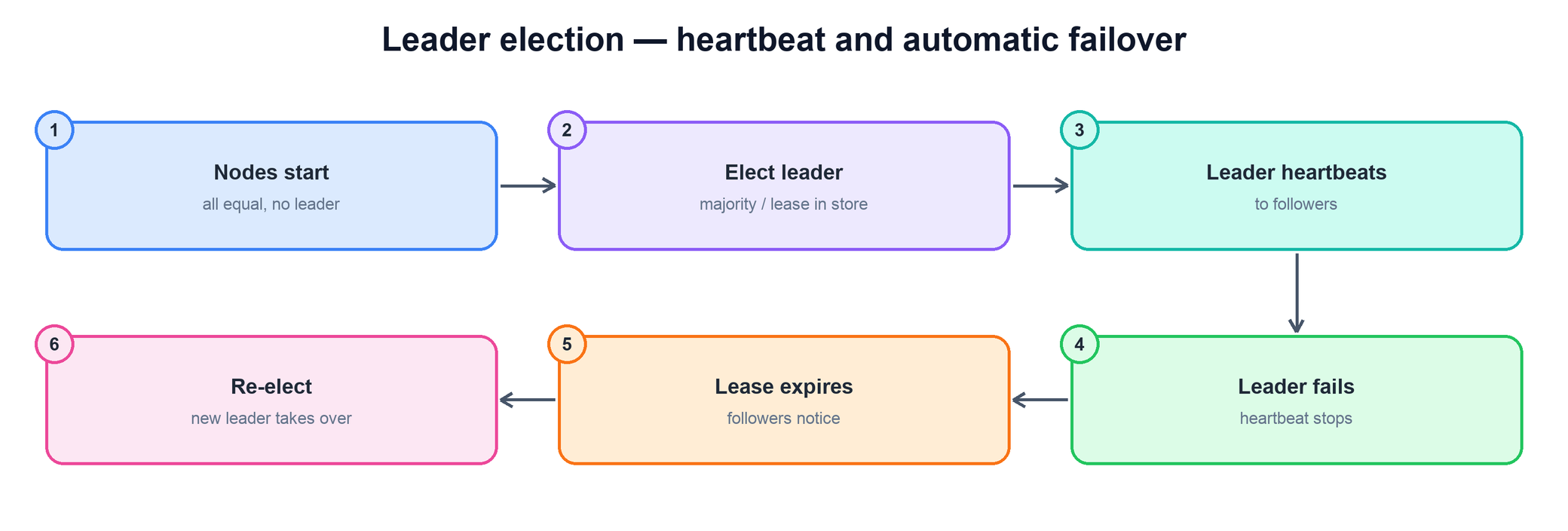
Leader election is mutual exclusion applied to a role: out of a group of identical nodes, exactly one should be the leader at a time, and if it fails another should take over automatically. You could try to build this by hand with the lease-and-fencing lock above, and the structure is the same — the leader is simply "whoever currently holds the leadership lease." But for anything that matters, the better answer is to delegate the hard part to a system explicitly built for agreement.
- A consensus protocol (e.g. Raft). The nodes run a consensus algorithm that guarantees they agree on a single leader for each term, with built-in handling of failures and elections. This is the foundation under most modern coordination systems.
- A coordination service (e.g. ZooKeeper, etcd). These expose primitives that make election easy: a candidate creates an ephemeral node tied to its session, and the node that creates the agreed-upon key (or the lowest-sequenced one) becomes leader. If that node's session dies, its ephemeral node disappears automatically, and the next candidate is notified and takes over.
In all of these, the leader sends heartbeats to prove it is alive, and the followers watch for them. When heartbeats stop and the leadership lease expires, the remaining nodes run an election and a new leader takes over — automatic failover with no human in the loop.
# election via an ephemeral key + heartbeat lease
function run_for_leader(node_id):
if store.set_if_absent("leader", node_id, expire=ttl):
become_leader()
start_heartbeat("leader", node_id, ttl) # renew while alive
else:
watch("leader") # re-run on expiry7. Split-Brain Avoidance
The nightmare scenario for any election is split-brain: a network partition cuts the cluster in two, and each side, unable to see the other, elects its own leader. Now two nodes both believe they are in charge, both accept writes, and the system's state forks. Resolving the damage after the partition heals can be impossible.
The standard defense is to require a majority quorum to elect or remain a leader. A candidate may only become leader if more than half of all nodes vote for it, and a sitting leader that can no longer reach a majority must step down. Because two disjoint groups cannot each contain more than half of the nodes, at most one side of any partition can have a leader; the minority side has no leader and refuses to accept writes until it rejoins. This is exactly what consensus protocols like Raft guarantee, and it is the reason such systems are deployed with an odd number of nodes — so a clean majority always exists. Fencing tokens then provide a second line of defense: even if a stale leader lingers briefly, its lower token is rejected by the protected resource.
8. Tradeoffs
How much machinery you need depends entirely on what the lock protects. An interviewer wants to see you match the mechanism to the cost of getting it wrong.
| Mechanism | Buys you | Cost / limitation |
|---|---|---|
| Single-key lock with TTL | Simple, fast, fine for best-effort coordination. | No safety under failover or paused holders; no fencing. |
| Lease + heartbeat renewal | Liveness: dead holders are reclaimed, long jobs supported. | Still unsafe on its own without fencing; tuning TTL is a tradeoff. |
| Fencing tokens | Safety: stale holders cannot corrupt the resource. | The protected resource must be modified to check tokens. |
| Consensus / coordination service | Correct election and locking under partitions; auto-failover. | Operationally heavier; adds latency and another system to run. |
The pragmatic rule: if a brief double-acquire merely wastes work (two workers process the same job, idempotently), a simple lease lock is fine. If a double-acquire corrupts data or money, you need fencing tokens and, for leadership, a consensus-backed coordination service with majority quorum. Reach for the heavy machinery only when the cost of being wrong justifies it.
9. Summary
A distributed lock recreates mutual exclusion on top of a system with no shared memory, independent failures, and unsynchronized clocks. The design is a stack of mechanisms, each covering a gap the previous one leaves open:
| Concern | Mechanism |
|---|---|
| Why is this hard? | No shared memory, partial failure, and clock skew — you cannot tell "dead" from "slow." |
| How do we reclaim a crashed holder's lock? | Store the lock with a TTL lease so it auto-expires. |
| How do we stop a paused, stale holder corrupting data? | Fencing tokens — monotonically increasing numbers the resource enforces. |
| Why isn't a naive Redis lock enough? | Single-node failover can double-grant, and it offers no fencing; Redlock's safety is debated. |
| How do we support long jobs with short TTLs? | Heartbeat renewal — extend the lease while alive, free it the moment renewals stop. |
| How do we pick a single leader? | Leader election via a consensus protocol or coordination-service ephemeral nodes with heartbeats. |
| How do we recover when the leader dies? | Heartbeats stop, the lease expires, the rest re-elect — automatic failover. |
| How do we avoid two leaders? | Majority quorum prevents dual election; fencing tokens stop a stale leader from corrupting state. |