Designing Package / Delivery Tracking
A system design interview guide to building a service that follows a shipment from the moment a label is printed through to delivery, ingesting a stream of scan events from carriers, keeping a current status and a full history, predicting arrival, and serving fast "where is my package?" lookups to millions of customers.
Package tracking is a deceptively good interview problem because it is, at heart, an exercise in turning an unreliable, out-of-order stream of external events into a clean, queryable model of the world. A shipment does not move through your system; it moves through trucks, planes, and sorting hubs you do not control, and all you ever see are scans — discrete observations that someone, somewhere, handled the package. Those scans arrive late, occasionally out of order, sometimes more than once, and you have to fold them into a single authoritative answer to two questions a customer keeps asking: where is my package right now, and when will it arrive? This guide builds up a design that treats the shipment as a state machine, ingests events idempotently, keeps both a current state and an append-only history, recomputes an ETA as new information lands, and serves the read path from a store tuned for speed.
Contents
1. The Package Lifecycle
The cleanest mental model for a shipment is a state machine. A package is always in exactly one well-defined state, and scan events are the transitions that move it from one state to the next. Pinning this down first is valuable in an interview because every later decision — what to store, what a "status update" means, when to notify the customer — hangs off this model.
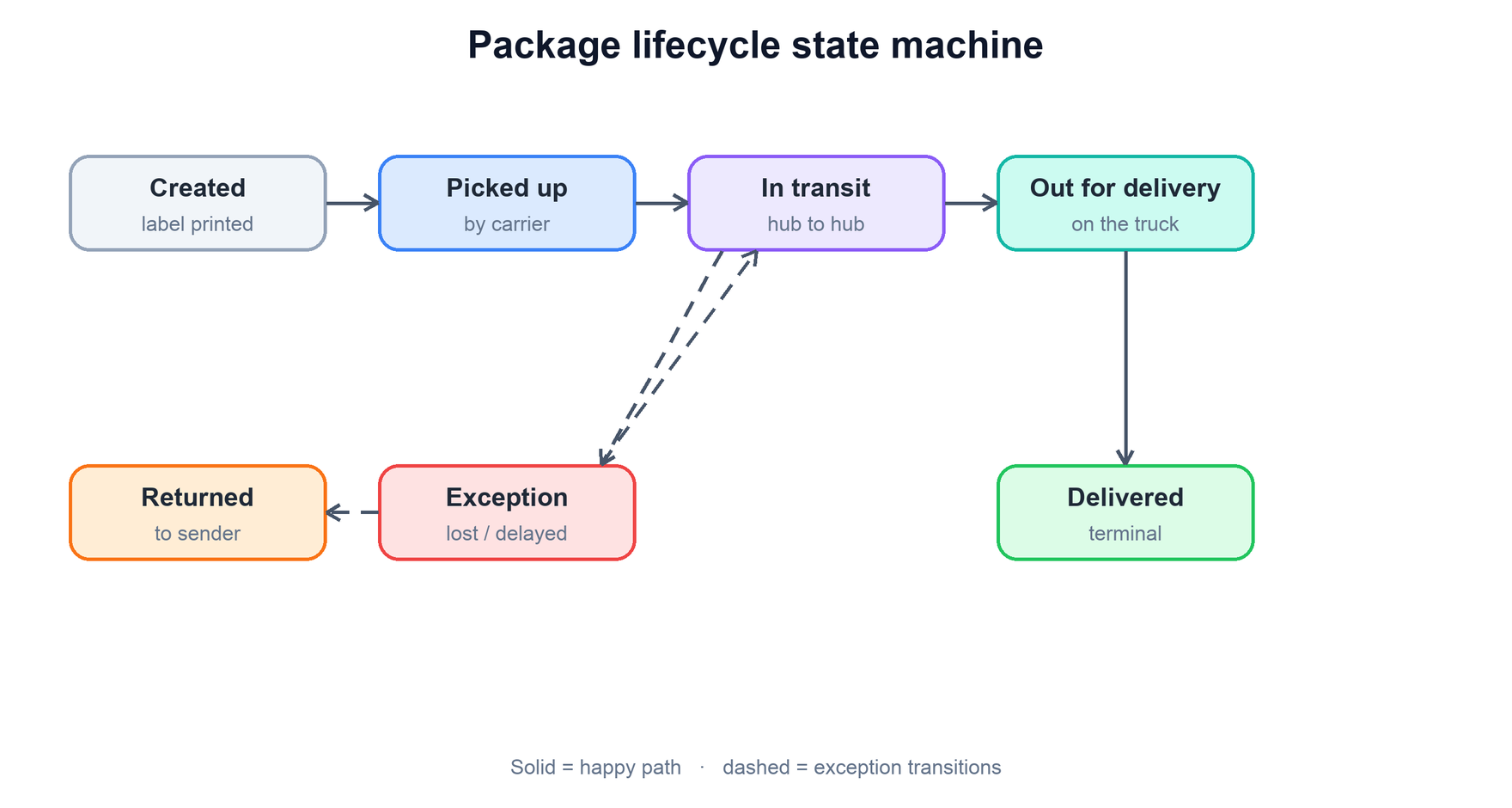
The states fall into two groups. The happy-path states are the ones every successful shipment passes through in order. The exception states capture everything that can go wrong without breaking the model:
| State | Meaning | Typical trigger |
|---|---|---|
| Created | The shipment exists and a tracking number has been issued, but no carrier has touched it yet. | Label printed by the merchant. |
| Picked up | A carrier has accepted physical custody of the package. | First carrier scan. |
| In transit | Moving through the carrier network, hub to hub. | Departure / arrival scans at facilities. |
| Out for delivery | Loaded on the final vehicle for delivery today. | Scan at the last-mile depot. |
| Delivered | Terminal success state. | Delivery scan / proof of delivery. |
| Exception | Something went wrong — lost, damaged, delayed, address problem. | Exception scan from a hub. |
| Returned | Terminal state: the package is going back to the sender. | Return-to-sender scan. |
Modeling exceptions as first-class states rather than as error flags keeps the system honest. An exception is not a failure of your system; it is a legitimate thing that happened to the package, and the customer deserves to see it. Note also that the machine is not strictly linear — a package in an Exception state can recover back into In transit, which is exactly why a naive "status can only move forward" assumption breaks.
2. Ingesting Scan Events
Everything the system knows comes from scan events emitted by carriers and sorting hubs. Each scan is a small record saying "package X was observed at location Y at time Z with status code C." Some carriers push these to you via webhook as they happen; others expect you to poll their API on a schedule. Either way, the ingestion layer has to accept a high-volume, bursty, and fundamentally messy stream.
A representative scan event looks like this:
{
"event_id": "scan-9f2c-0042", # unique per scan, used for dedup
"tracking_id":"1Z-TRACK-7788",
"status_code":"DEPARTED_HUB", # maps to a lifecycle transition
"facility": "Memphis Hub",
"lat_lng": [35.04, -89.98],
"scanned_at": "2026-06-29T14:03:00Z", # event time, NOT receive time
"received_at":"2026-06-29T14:07:11Z"
}Three properties of this stream shape the rest of the design, and it is worth naming them explicitly:
- Out of order. Network delays, batched uploads, and clock skew mean a later scan can arrive before an earlier one. You cannot assume
received_atorder matchesscanned_atorder, so transitions must be applied on event time, not arrival time. - Duplicated. Webhooks retry, polls overlap, and hubs occasionally double-scan. The same logical event can show up two or three times, so ingestion must be idempotent.
- Untrusted in shape. Status codes vary by carrier, fields go missing, timestamps are malformed. Every event has to be validated and normalized into your own vocabulary before it touches the state machine.
3. End-to-End Architecture
The architecture follows the flow of an event: carriers and hubs emit scans, an ingest service validates and applies them, the result is written to a current-state store and appended to an immutable history, an ETA service recomputes the predicted arrival, and the customer-facing read path is served from a store tuned for fast lookups by tracking number.
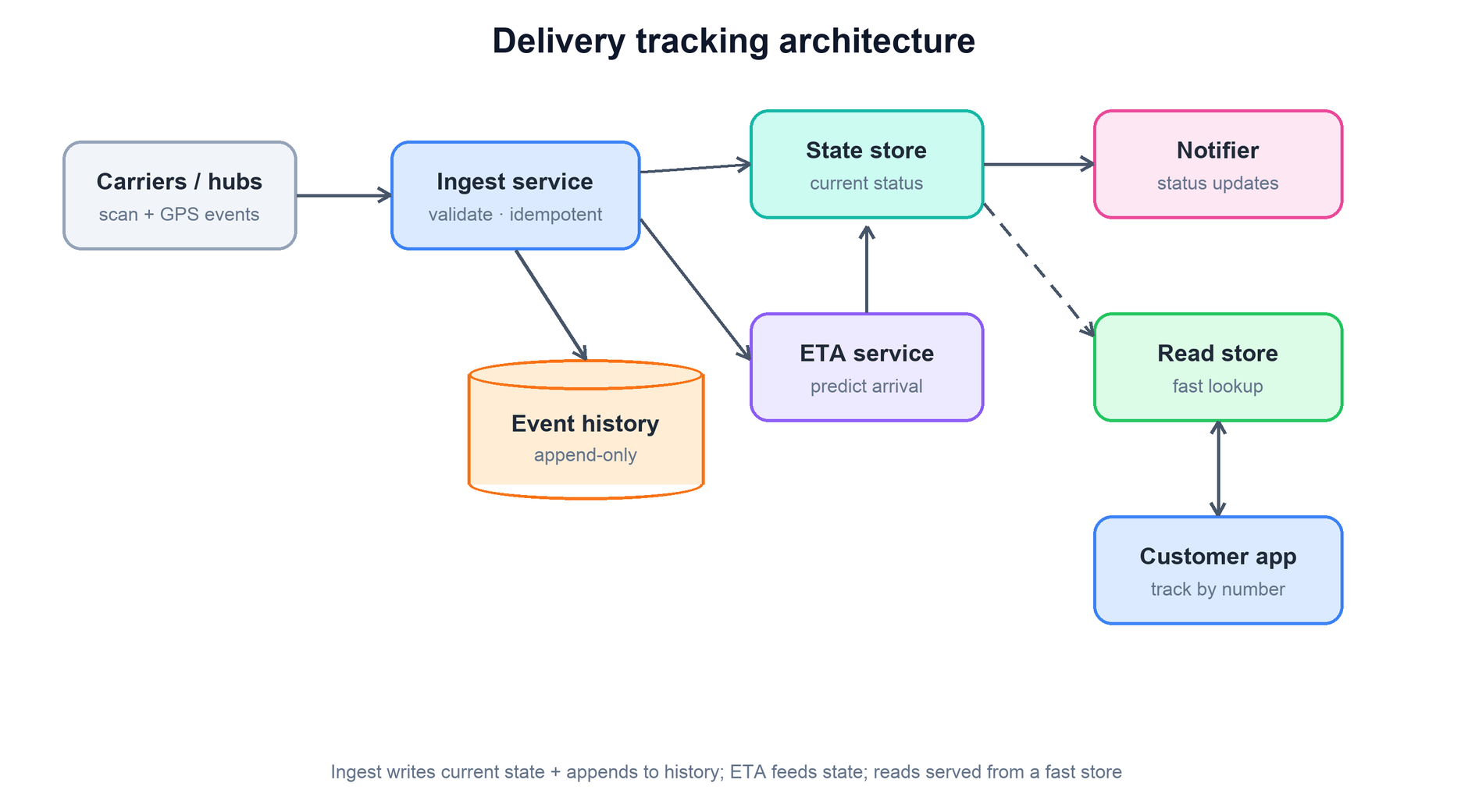
Walking the components in the order an event touches them:
- Carriers / hubs. The external sources of truth about physical reality. They push webhooks or expose polling APIs. You treat them as untrusted and unreliable, exactly as a notification system treats its gateways.
- Ingest service. The single entry point for all events. It validates the payload, normalizes the carrier-specific status code into your lifecycle vocabulary, checks the event id for duplicates, and decides whether this event advances the state machine. It is the only component allowed to mutate the state store.
- Event history. An append-only log of every accepted scan. Nothing here is ever updated or deleted. This is the audit trail and the source from which current state can always be rebuilt.
- State store. The current state of every shipment — one row per tracking number with its present status, last known location, and current ETA. This is small, hot, and frequently read.
- ETA service. Given the latest location and the route, it predicts the arrival window and writes it back into the state store.
- Notifier. When a transition is meaningful to the customer (picked up, out for delivery, delivered, exception), it pushes a status update — reusing the kind of fan-out notification pipeline covered elsewhere.
- Read store. A denormalized, read-optimized view that the customer app hits. Keeping reads off the write path means a traffic spike of "where is my package?" lookups cannot slow down event ingestion.
4. Current State vs. History
One of the central design choices is to keep two representations of the same shipment: a single mutable "current state" record and an append-only history of every event. They answer different questions and have opposite access patterns, and trying to serve both from one table leads to pain.
| Current state | Event history | |
|---|---|---|
| Shape | One row per tracking number. | Many rows per tracking number, one per scan. |
| Mutability | Updated in place as the package moves. | Append-only; never updated or deleted. |
| Answers | "What is the status right now?" | "What is the full journey, in order?" |
| Read pattern | Point lookup by tracking id — very hot. | Range scan of one package's events. |
The history is the more fundamental of the two. Because it records every event with its event time, the current state can always be derived from it by replaying the events in order. That makes the current-state record effectively a cache — a materialized projection kept up to date for fast reads, but reconstructable from the log if it is ever lost or corrupted. This is the same event-sourcing instinct that underpins many ledger and audit systems: keep the immutable facts, and treat every aggregate as a view over them.
5. Idempotent, Out-of-Order Ingestion
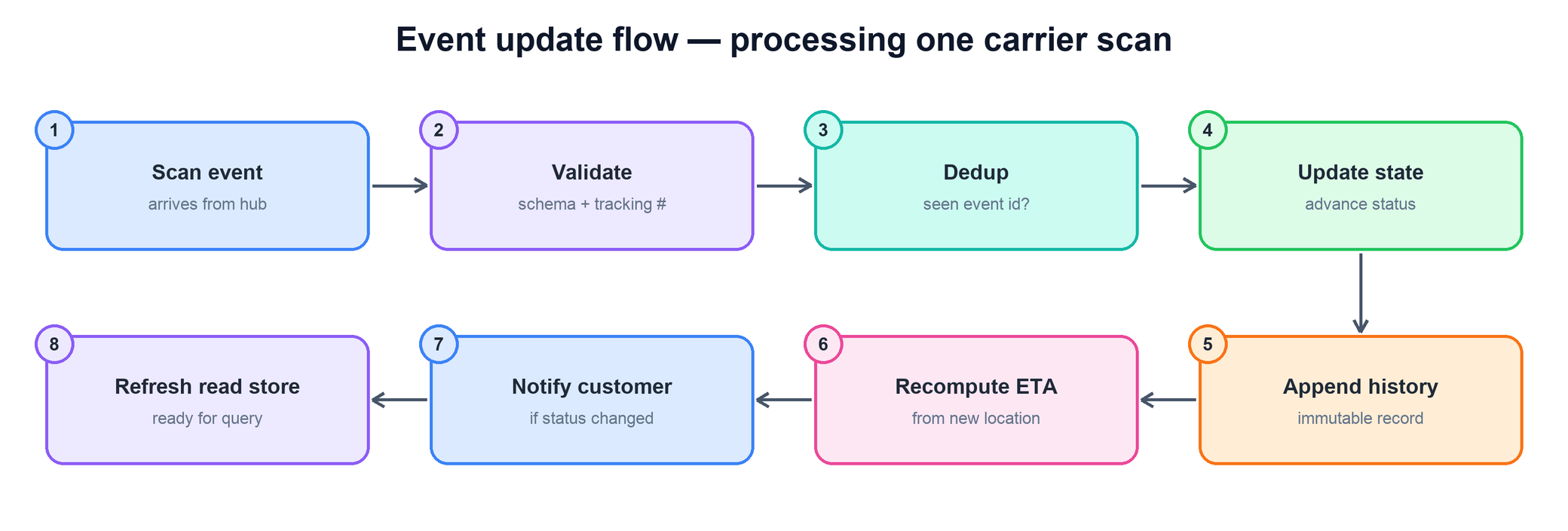
Given that events are duplicated and out of order, the ingest service has to be careful about how it folds an event into the state. Two rules make this safe.
Idempotency by event id. Every scan carries a unique event_id. Before doing anything, the ingest service checks whether that id has already been appended to the history. If it has, the event is a duplicate and is dropped silently. This means a carrier can safely retry a webhook, or a poll can overlap a previous poll, without ever double-applying a scan.
Event-time ordering for the state transition. The append-only history records every accepted event regardless of arrival order — that is fine, because history is just facts. But the current state must reflect the latest thing that actually happened to the package, by event time. So a late-arriving scan with an older scanned_at is appended to history but does not regress the current status. The state machine only advances when an event is both legal for the current state and newer than the last applied event.
function ingest(event):
validate(event) # reject malformed payloads
if history.contains(event.event_id):
return DUPLICATE # idempotent: drop replays
history.append(event) # always record the fact
state = state_store.get(event.tracking_id)
if event.scanned_at <= state.last_event_at:
return STORED_NOT_APPLIED # late scan: history only
next = transition(state.status, event.status_code)
if next is ILLEGAL:
flag_for_review(event) # unexpected transition
return
state_store.update(event.tracking_id,
status=next,
location=event.facility,
last_event_at=event.scanned_at)The combination gives at-least-once ingestion with exactly-once effect: the network may deliver an event many times and in any order, but the state machine advances cleanly and monotonically, and the history stays a faithful, complete record.
6. Computing the ETA
Customers care less about the current location than about the answer to "when will it get here?" The ETA service turns the stream of location scans into a predicted arrival window. It is recomputed whenever a new, applied scan moves the package, because each scan is fresh evidence about how the shipment is progressing relative to plan.
A first-cut ETA can be simple — the carrier's committed delivery date for the service level — and then refined as scans arrive:
- Baseline. At creation, the ETA is the service-level commitment (e.g. "ground, 3–5 days"). This gives the customer an answer before a single scan exists.
- Progress-based refinement. As the package hits expected waypoints on time, confidence narrows the window. If it sits at a hub longer than the historical average for that leg, the ETA slips.
- Exception handling. An exception scan widens or invalidates the ETA — you do not pretend to know the arrival of a package that is currently lost.
The recomputed ETA is written back into the state store so it travels with the current status and is served on the next read. A more sophisticated version feeds historical leg times and current network load into a model, but the interview point is the shape: ETA is a function of the event history and the route, recomputed on each meaningful transition.
function recompute_eta(tracking_id):
state = state_store.get(tracking_id)
legs = route.remaining_legs(state.location, state.destination)
base = sum(historical_leg_time(leg) for leg in legs)
if state.status == EXCEPTION:
return widen(base) # low confidence when stuck
return now() + base * congestion_factor() # adjust for load7. Notifying the Customer
A status update is only useful if the customer hears about it. When an applied scan produces a transition the customer cares about, the ingest service emits an event to a notifier, which pushes a notification through the appropriate channel — push, SMS, or email — based on the customer's preferences.
Two design points keep this clean. First, not every scan is notification-worthy: a customer wants to know when the package is picked up, out for delivery, delivered, or stuck in an exception, but they do not need a ping for every intermediate hub scan. The notifier subscribes only to the meaningful transitions. Second, notifications should fire off the transition, not off the raw event — because of out-of-order and duplicate scans, firing on every event would mean duplicate or even contradictory alerts ("delivered" followed by "in transit"). Driving notifications from the deduplicated, ordered state machine guarantees the customer sees a coherent story.
NOTIFY_ON = {PICKED_UP, OUT_FOR_DELIVERY, DELIVERED, EXCEPTION}
function on_transition(tracking_id, old, new):
if new in NOTIFY_ON and new != old: # meaningful + actually changed
notifier.send(customer_of(tracking_id),
template=new,
params={tracking_id, eta_of(tracking_id)})8. The Customer Read Path
The most common operation in the whole system is a customer typing a tracking number into a page and asking "where is my package?" These reads vastly outnumber writes, they spike unpredictably (a delivery-day surge, a marketing email, a delayed shipment everyone refreshes), and they must be fast. So the read path is deliberately separated from the write path.
The read store holds a denormalized view per tracking number: current status, last known location, ETA, and a compact recent history — everything the tracking page needs in a single point lookup, with no joins. It is updated asynchronously whenever the state store changes, and it is the only thing the customer-facing API touches. This buys several properties:
- Isolation. A flood of read traffic hits the read store, not the ingest pipeline, so a viral "everyone is refreshing" moment cannot stall event processing.
- Caching. Because a tracking page is read far more often than the package moves, results cache well; most lookups never reach a database.
- Independent scaling. Reads and writes scale on separate hardware tuned for their own pattern — point reads on one side, append-heavy ingestion on the other.
This is a textbook command-query separation: writes flow through ingestion into the authoritative state and history, while reads are served from a projection optimized purely for lookups. The slight asynchrony — the read store lags the state store by a moment — is an acceptable trade for the isolation and speed it buys, because a tracking page being a second stale is invisible to the customer.
9. Summary
Delivery tracking is the discipline of turning an unreliable external event stream into a clean, queryable model. The design is a handful of decisions that reinforce each other:
| Concern | Mechanism |
|---|---|
| How do we model a shipment? | A state machine: Created → Picked up → In transit → Out for delivery → Delivered, plus Exception and Returned. |
| Where does information come from? | Scan events from carriers and hubs, via webhook or polling — out of order, duplicated, and untrusted. |
| How do we accept events safely? | An ingest service that validates, normalizes, and is the sole writer of state. |
| How do we keep an audit trail? | An append-only event history; current state is a projection that can be replayed from it. |
| How do we handle duplicates and reordering? | Idempotency by event id; advance the state machine only on newer, legal transitions. |
| When will it arrive? | An ETA service that recomputes the arrival window on each meaningful scan and writes it into state. |
| How does the customer find out? | A notifier driven off state transitions (not raw events) for meaningful status changes. |
| How do we serve "where is my package?" | A fast, denormalized read store, separated from the write path for isolation and scale. |