Counting Unique Active Users at Scale
A system design interview guide to counting distinct identifiers — daily and monthly active users, unique ad reach — across billions of events, when keeping the exact set of every id in memory is no longer affordable.
"How many distinct users did we see today?" sounds like a one-line question, and at small scale it is: drop every user id into a set and read off its size. The trouble starts when "today" means tens of billions of events and the answer has to cover dozens of audiences, time windows, and breakdowns at once. A set that remembers every id it has ever seen grows in lockstep with the number of distinct ids, and at a billion ids that set is gigabytes — per metric, per window. The interesting design problem is not the counting itself but how to count distinctly without paying for memory that scales with the answer. This guide builds up from the naive set to probabilistic cardinality estimation, the property that makes it composable across shards and time, and the architecture that ties it together.
Contents
1. The Distinct-Count Problem
The core operation is cardinality: given a stream of identifiers with arbitrary repeats, report how many different ones appeared. This is fundamentally harder than a plain count, because a plain count just needs a running integer — you never have to remember which ids you have already seen. Distinct counting does: to avoid counting the same user twice, something has to recognise that this id has shown up before.
The metrics that ride on this operation are everywhere in a consumer product:
- DAU and MAU — daily and monthly active users, the headline engagement numbers, are distinct counts of user ids over a one-day and a rolling thirty-day window.
- Unique reach — how many distinct people an ad or campaign actually touched, as opposed to total impressions, which double-count anyone who saw it more than once.
- Distinct visitors per page, per region, per cohort — the same operation sliced many ways, which multiplies the number of independent counts you have to maintain.
Two things make this expensive at scale. First, the stream is enormous and unbounded, so any approach that touches every event has to be cheap per event. Second, you rarely want a single global number; you want the count for many overlapping audiences and windows, and each one is its own distinct-count problem. A solution that costs gigabytes for one metric does not survive being multiplied by hundreds of slices.
2. Why an Exact Set Blows Up
The exact answer is conceptually trivial: maintain a hash set, insert every id, and the cardinality is the set's size. It is also correct to the last unit. The problem is purely one of resources, and it shows up the moment the number of distinct ids gets large.
Each distinct id you insert occupies space in the set — the id itself plus the hash-table overhead around it. That space is paid per distinct id, so the set's footprint grows linearly with cardinality. At a million ids it is a few tens of megabytes and nobody notices. At a billion distinct ids it is many gigabytes for a single counter, and you do not have one counter — you have one per metric, per window, per breakdown. The memory bill is the product of all of those, and it grows without bound as your audience and the number of slices grow.
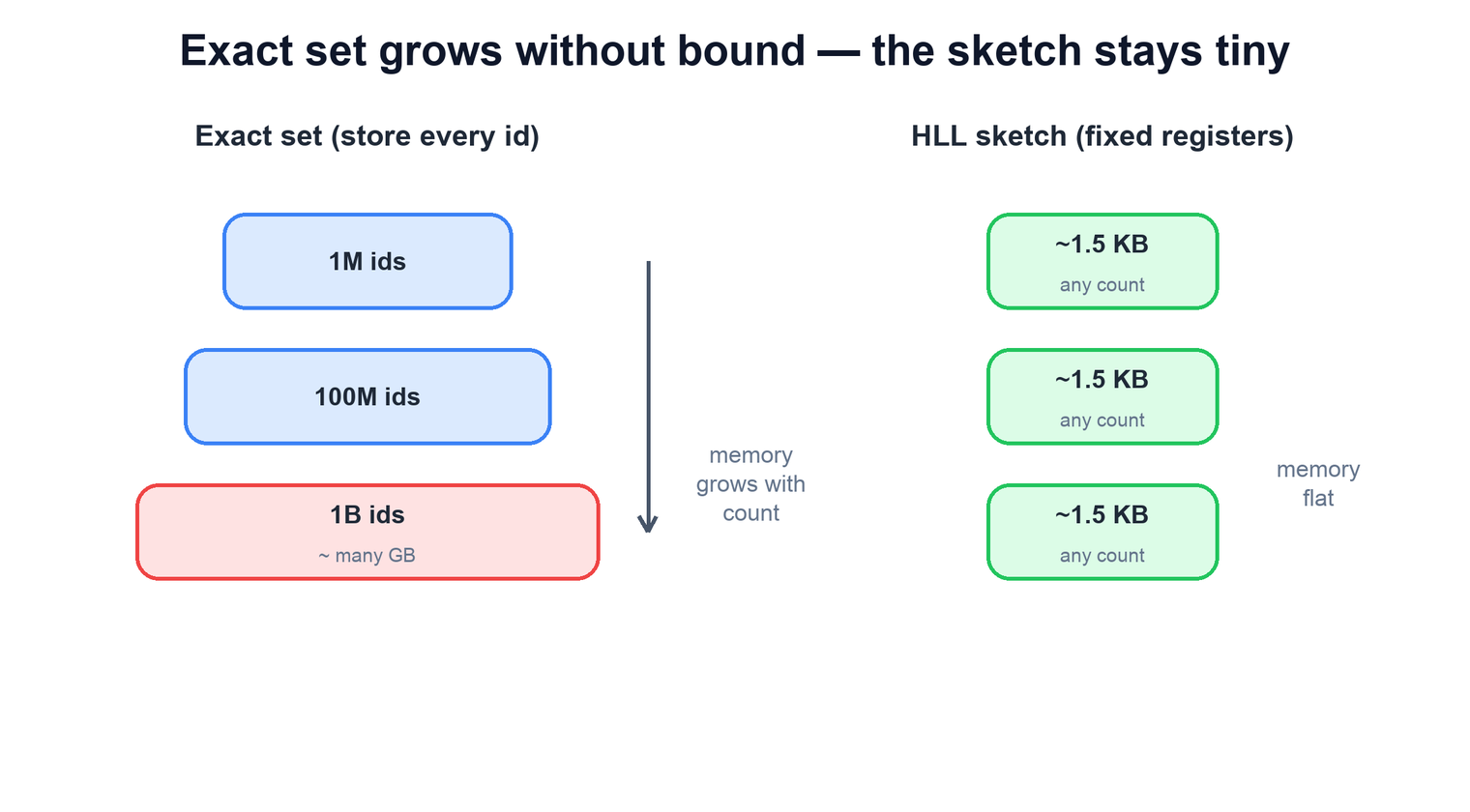
You could push the exact set onto disk or into a distributed store, but that trades a memory problem for a throughput and latency problem: every event now involves a lookup and possible write against external storage, and the storage itself still grows with cardinality. For a high-rate stream feeding many metrics, the exact set is the wrong tool — not because it is incorrect, but because its cost is tied to exactly the quantity you are trying to measure.
The key insight that unlocks a cheaper approach is that most consumers of these numbers do not need the exact figure. Whether daily actives are 41,802,119 or 41,800,000 changes no decision; a count that is within a percent or two, computed in a fixed kilobyte, is far more valuable than an exact one that costs gigabytes. That tolerance is what probabilistic cardinality estimation trades on.
3. HyperLogLog
HyperLogLog (HLL) is the standard answer to large-scale distinct counting. It estimates cardinality from a tiny, fixed-size summary — a few kilobytes that can stand in for billions of distinct ids — by exploiting a statistical property of hashed values rather than remembering the ids themselves.
The intuition is a coin-flip argument. If you hash an id into a uniformly random bit string, then the number of leading zeros in that string behaves like flipping a coin and counting how many heads you get in a row before the first tail. Seeing a run of k leading zeros is roughly a one-in-2k event. So if, across all the ids you have hashed, the longest run of leading zeros you have ever observed is k, that is evidence you have probably seen on the order of 2k distinct values. Crucially, repeats do not move this estimate: hashing the same id again produces the same bit string and the same leading-zero count, so duplicates are silently absorbed — which is exactly the distinctness property we need.
A single longest-run observation is a wildly noisy estimator, so HLL splits the work across many independent registers (also called buckets) and averages them. Each id is hashed once; the first few bits of the hash pick which register the id belongs to, and the remaining bits supply the leading-zero count for that register. Each register keeps only the maximum leading-zero count it has ever seen — a small integer, a handful of bits. The final estimate combines all the registers using a harmonic mean (with a bias correction), which damps the influence of any one unusually long run and gives a stable answer.
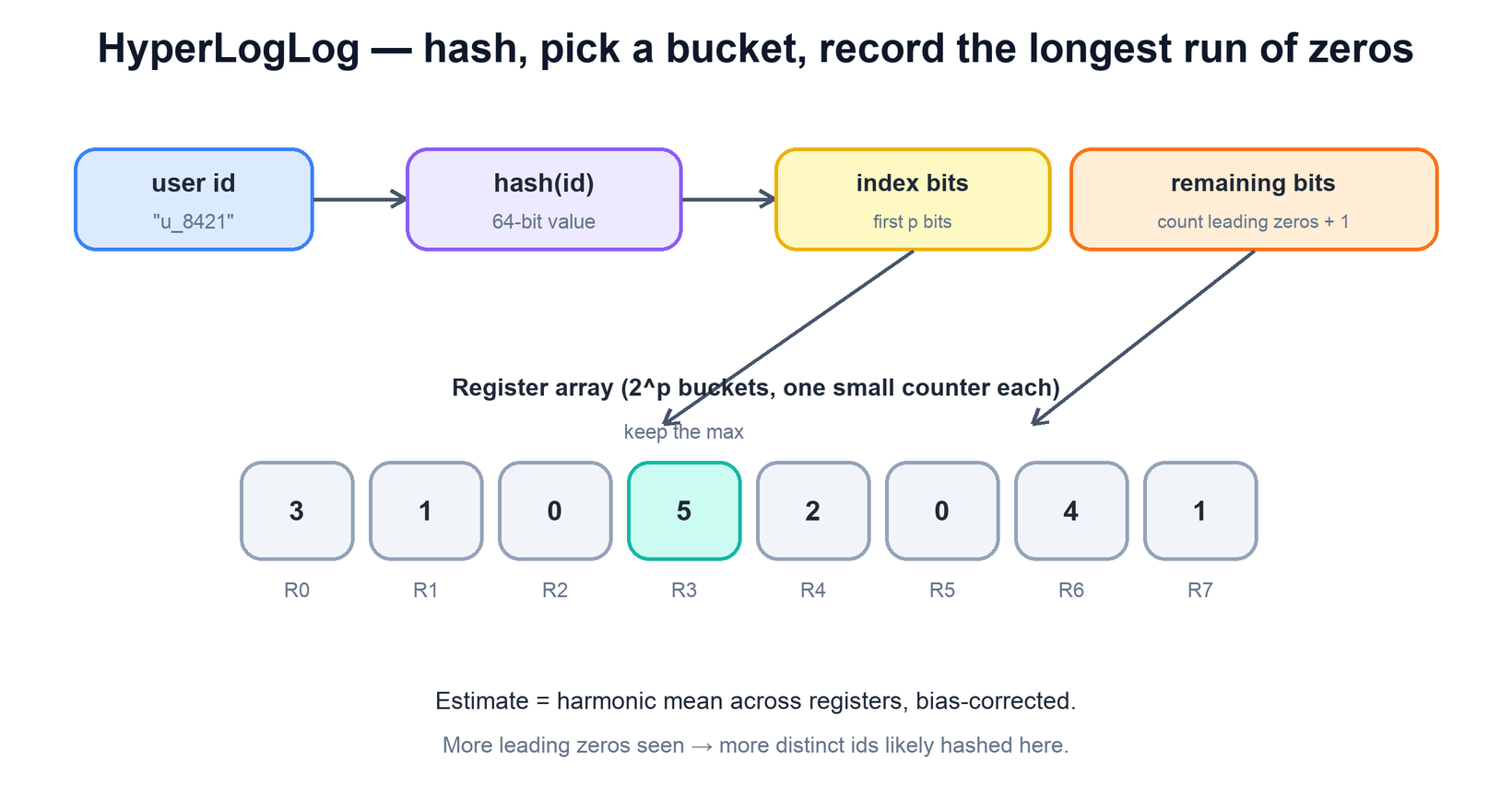
# add an id to the sketch
function hll_add(registers, id):
h = hash64(id) # uniform 64-bit value
idx = h >> (64 - p) # first p bits -> register index
rest = h & ((1 << (64 - p)) - 1) # remaining bits
rank = leading_zeros(rest) + 1 # length of the zero run + 1
registers[idx] = max(registers[idx], rank) # keep the longest run
# estimate the cardinality from the registers
function hll_estimate(registers):
m = len(registers) # 2^p buckets
raw = alpha(m) * m*m / sum(2 ** -r for r in registers) # harmonic mean
return bias_correct(raw, registers) # small/large-range fixesThe headline result is the memory story. With on the order of a few thousand registers of a few bits each — about 1.5 KB total — HLL estimates cardinalities up into the billions with a typical relative error around two percent. That footprint is fixed: it does not grow as the count grows, which is precisely the link that the exact set could not break.
4. Mergeability
The property that makes HLL a system-design building block rather than just a clever counter is that two sketches can be merged into one that represents the union of their inputs — exactly and losslessly, with no double counting and no need to revisit the original ids.
Because each register simply holds the maximum leading-zero run seen for the ids that hashed into it, merging two sketches is element-wise maximum: for each register position, take the larger of the two values. The resulting sketch is identical to one you would have built by feeding it every id from both inputs. This works only when the sketches share the same hash function and the same number of registers, which is why those parameters are fixed and standardised up front.
# union of two sketches = element-wise max of registers
function hll_merge(a, b):
return [max(a[i], b[i]) for i in range(len(a))]
# DAU over a week = merge of seven daily sketches, then estimate
weekly = reduce(hll_merge, [daily[d] for d in last_7_days])
dau_week = hll_estimate(weekly)Mergeability buys two things that the architecture leans on heavily:
- Across shards. The event stream is partitioned across many machines, each maintaining its own local sketch over the ids it sees. The global distinct count is the merge of all the per-shard sketches. No machine needs the full set of ids, and no shuffle of raw ids is required — you ship kilobyte-sized sketches, not the stream.
- Across time windows. Store one sketch per small window — say one per hour or per day — and you can answer any larger window by merging the relevant pieces. Weekly actives are the merge of seven daily sketches; a rolling thirty-day MAU is the merge of thirty. You never recompute from raw events; you compose pre-built sketches.
This is the property that an exact set cannot match cheaply: unioning two large sets means materialising both and deduplicating across them, whereas merging two sketches is a fixed-size, order-independent maximum. It is also what makes distinct counting feel like ordinary aggregation — the sketch behaves like a number you can add up, except the "addition" is a set union.
5. Accuracy and Error
HLL is an estimator, and its error is a tunable parameter rather than an accident. The single knob is the number of registers, set by the precision p (the sketch has 2p registers). More registers mean more independent observations to average, which means a tighter estimate — at the cost of a larger, though still tiny, sketch.
The relationship is clean: the typical relative error scales roughly with one over the square root of the number of registers. Doubling the registers shrinks the error by about thirty percent. The commonly cited operating point — around 1.5 KB and roughly two percent error — is just one choice on this curve; you can spend a few more kilobytes to push the error well under a percent if a metric warrants it.
| Concern | What it means in practice |
|---|---|
| Tunable error | Pick precision p to trade memory for accuracy. Error ~ 1/√(2^p); more registers, tighter estimate, slightly bigger sketch. |
| Relative, not absolute | The error is a percentage of the true count, so the absolute miss grows with cardinality — fine for large numbers, less ideal for tiny ones. |
| Small-range behaviour | At very low cardinalities the raw estimate is biased; implementations switch to a more exact mode (e.g. linear counting) below a threshold. |
| No per-id queries | A sketch answers "how many distinct?" but cannot tell you whether a specific id is in the set — it forgets the ids by design. |
The practical consequence is that HLL is excellent for the large, fuzzy numbers that drive product and business decisions, and a poor fit when you need exactness or per-element membership. Knowing which regime you are in is the judgement call.
6. Exact vs Approximate
Choosing between an exact set and a probabilistic sketch is a question about requirements, not cleverness. The deciding factors are how large the cardinality gets, how much error the consumer can tolerate, and whether anything downstream needs to ask about individual ids.
- Use an exact count when cardinalities are modest (thousands to low millions), when the number must be precise — billing, compliance, financial reconciliation, anything audited — or when you also need membership ("has this specific user been seen?"). At small scale the exact set is simple, correct, and cheap enough.
- Use an approximate sketch when cardinalities reach the high millions or billions, when a couple of percent of error is invisible to the decision being made, and especially when you need to roll the same metric up across many shards and time windows. This is the regime of DAU, MAU, and unique reach.
A common hybrid is to keep exact counts for small or high-stakes slices and switch to HLL once a slice's cardinality crosses a threshold where the exact set's memory stops being free. Some systems even start a counter as an exact set and promote it to a sketch automatically when it grows past a configured size, getting precision for small audiences and bounded memory for large ones.
7. Real Tools
You almost never implement HLL by hand; it ships inside the data systems you already use, which is worth knowing for an interview because it lets you reach for the right primitive rather than reinventing it.
| Tool | Interface | What it gives you |
|---|---|---|
| Redis | PFADD key id, PFCOUNT key, PFMERGE dst src... | An HLL data type behind a simple key. Add ids, read the estimate, and merge keys — the per-shard sketch and the union, served from memory. |
| Presto / Trino | approx_distinct(col) | Approximate distinct count in SQL over huge tables, backed by HLL, at a fraction of the cost of an exact COUNT(DISTINCT). |
| Spark | approx_count_distinct(col, rsd) | The same operation in a batch pipeline, with a tunable relative standard deviation that maps directly to the precision knob. |
| Data warehouses | e.g. APPROX_COUNT_DISTINCT | Most analytical warehouses expose an HLL-backed approximate distinct function for the same reason: exact distinct counts do not scale. |
A pattern worth highlighting: several of these can persist the sketch itself, not just the final number. Storing the serialised HLL sketch per window lets you merge stored sketches later to answer windows you did not pre-compute — the mergeability property surfacing as a concrete storage decision.
# Redis: per-shard add, then read the union across shards
PFADD dau:2026-06-29:shard3 u_8421 u_1990 u_8421 # dup absorbed
PFMERGE dau:2026-06-29 dau:2026-06-29:shard* # union of shards
PFCOUNT dau:2026-06-29 # ~ estimated DAU
# Presto: approximate distinct over a billion-row table
SELECT approx_distinct(user_id) AS dau
FROM events WHERE day = DATE '2026-06-29';8. Architecture
Putting the pieces together, a unique-user counting service is a pipeline that turns a firehose of events into a small, mergeable sketch per metric and window, and serves estimates by reading or merging those sketches. The shape follows directly from the two properties established above: a sketch costs fixed memory, and sketches merge.
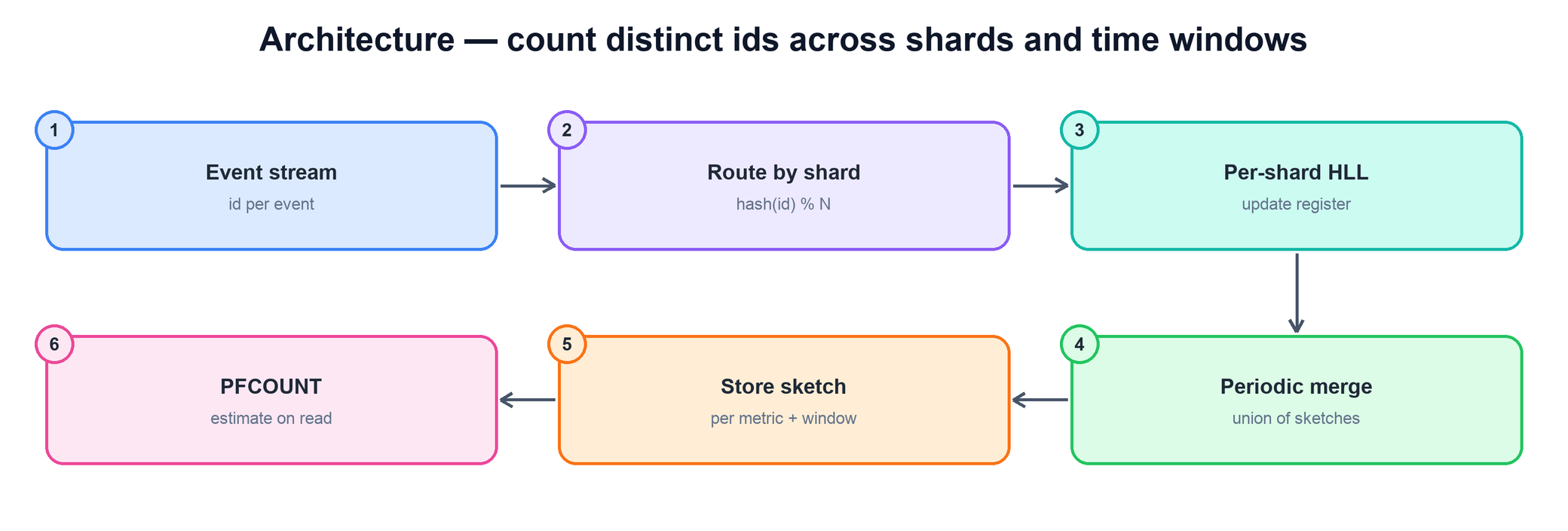
Tracing the flow:
- Event stream. Raw events arrive at high rate, each carrying at least a user id and the dimensions you slice on (time, region, campaign). This is the firehose; per-event work has to be cheap.
- Routing by shard. Events are partitioned across machines, typically by hashing the id, so each shard maintains an independent sketch over its portion of the stream. Routing by id is not required for correctness — sketches merge regardless — but it keeps each shard's work bounded.
- Per-shard HLL update. For each event, the shard hashes the id and updates the relevant register in its in-memory sketch. This is the only per-event cost, and it is a hash plus a max — constant time, constant space.
- Periodic merge. On a schedule (or at window boundaries), a job merges the per-shard sketches for each metric and window into a single consolidated sketch via element-wise max. This collapses many partial sketches into the canonical one for that slice.
- Store sketch per metric + window. The merged sketches are persisted, keyed by metric and window. Storing the sketch, not just the estimate, preserves mergeability so larger or composite windows can be answered later.
- Query. A read either estimates directly from one stored sketch, or merges several stored sketches (e.g. seven dailies for a weekly figure) and then estimates. Either way the read touches kilobytes, not the original stream.
# ingest path: cheap per-event update on the owning shard
function on_event(evt):
shard = pick_shard(evt.user_id) # hash(id) % N
for window in windows_for(evt.timestamp): # e.g. this hour, this day
sketch = shard.sketch(evt.metric, window)
hll_add(sketch.registers, evt.user_id) # hash + max, O(1)
# periodic merge: collapse per-shard sketches, then persist
function consolidate(metric, window):
merged = reduce(hll_merge, [s.sketch(metric, window) for s in shards])
store.put(key(metric, window), merged) # keep the sketch itself
# read path: estimate, merging windows on the fly if needed
function distinct_count(metric, windows):
sketches = [store.get(key(metric, w)) for w in windows]
return hll_estimate(reduce(hll_merge, sketches))9. Summary
Counting unique users at scale is the problem of measuring cardinality without paying memory proportional to the answer. The design is a small set of decisions that reinforce one another:
| Concern | Mechanism |
|---|---|
| What are we actually computing? | Cardinality — the number of distinct ids in a stream — for metrics like DAU, MAU, and unique reach. |
| Why not just use a set? | An exact set costs memory proportional to the distinct count — gigabytes at a billion ids, multiplied across every metric and window. |
| How do we count distinctly in fixed memory? | HyperLogLog: hash each id, track the longest leading-zero run per register, estimate via a bias-corrected harmonic mean. |
| How do we roll up across shards and time? | Mergeability — the union of two sketches is the element-wise max of their registers, exact and order-independent. |
| How accurate is it? | Tunable: error ~ 1/√(registers); about 1.5 KB buys roughly two percent error for billions of ids. |
| When should we stay exact? | Small cardinalities, audited or billed numbers, or when per-id membership is required. |
| What do we build on? | Redis PFADD/PFCOUNT/PFMERGE, Presto approx_distinct, Spark approx_count_distinct — HLL is built in. |
| How is it wired together? | Event stream → per-shard sketch → periodic merge → stored sketch per metric and window → estimate on read. |