Consistent Hashing & Designing a Key-Value Store
A system-design interview guide to the one idea that makes distributed storage tractable: how to spread keys across a changing set of servers without reshuffling everything, and how that single technique becomes the backbone of a partitioned, replicated, tunable key-value store.
Almost every distributed data system has to answer the same question first: given a key, which machine holds it? When there is exactly one machine the answer is trivial, but the moment you have several — and especially when that number changes as machines come and go — the mapping becomes the whole game. Consistent hashing is the technique that keeps that mapping stable under change, and it turns out to be the foundation that the rest of a key-value store is built on. This guide starts from the naive approach, shows why it falls apart, develops consistent hashing and virtual nodes, and then uses it as the partitioning layer of a complete distributed key-value store — replication, the CAP tradeoff, tunable quorums, conflict resolution, and the background machinery that keeps replicas honest.
Contents
1. The Problem with Naive Hashing
Suppose you have N servers and you want to spread keys evenly across them. The obvious scheme is to hash the key to an integer and take it modulo the server count:
server_index = hash(key) % NWhile N stays fixed this works beautifully. The hash spreads keys uniformly, the modulo folds them into the range 0 .. N-1, and every server gets roughly the same share. The trouble is the N in that formula. The instant the server count changes — a machine is added to grow capacity, or one fails and drops out — N becomes a different number, and the modulo of nearly every key changes with it.
Concretely, suppose you have 4 servers and add a 5th. A key that hashed to 1000 previously mapped to 1000 % 4 = 0; now it maps to 1000 % 5 = 0 — but a key that hashed to 1002 moves from 1002 % 4 = 2 to 1002 % 5 = 2, and countless others jump to entirely different servers. In general, going from N to N+1 servers remaps on the order of N/(N+1) of all keys. Almost everything moves.
| Symptom | Why it hurts |
|---|---|
| Cache miss storm | If the servers are a cache, nearly every key now resolves to a server that does not hold it. The cache effectively empties at once and every request falls through to the backing store. |
| Massive data movement | If the servers are a database, the data for the remapped keys must physically migrate to its new owner. Adding one node triggers a near-total reshuffle of the cluster. |
| Load spike during reshuffle | The migration and the cold cache happen exactly when you were trying to add capacity, so the change that should help can instead tip the system over. |
hash(key) % N couples the key-to-server mapping to the total count of servers. Any change to the count perturbs the mapping for keys that had nothing to do with the server that changed. We want a scheme where adding or removing one server only affects the keys that server is directly responsible for.2. Consistent Hashing
Consistent hashing breaks the coupling by hashing servers and keys into the same output space and arranging that space as a ring. Pick a hash function with a fixed output range, say 0 .. 2^k - 1, and imagine those values laid out on a circle so that the largest value wraps back around to 0.
- Place the servers. Hash each server's identifier (name, IP, id) onto the ring. Each server now occupies a point on the circle.
- Place the keys. Hash each key with the same function. Each key also lands at a point on the circle.
- Assign by walking clockwise. A key belongs to the first server you reach going clockwise from the key's position. If you walk past the top of the ring without finding one, you wrap around to the first server after
0.
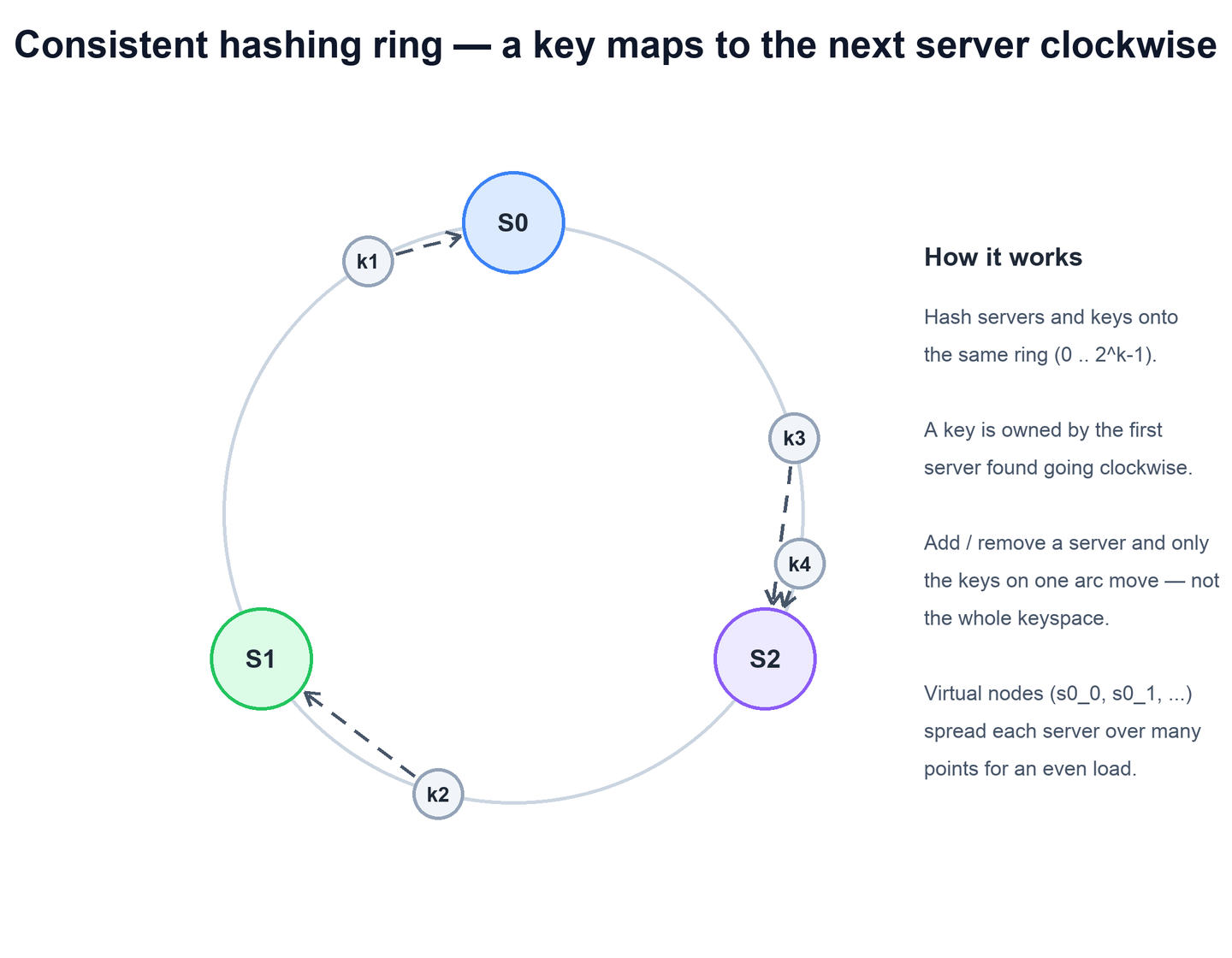
The payoff is what happens on change. When a server is removed, only the keys that it owned — the keys on the arc immediately counter-clockwise of it — need to move, and they move to the next server clockwise. Every other key keeps its owner. When a server is added, it inserts itself at one point on the ring and takes over only the slice of keys between it and its clockwise predecessor; it pulls those keys from a single neighbor and leaves the rest of the cluster untouched.
function lookup(key, ring):
pos = hash(key) # same hash space as servers
for server_pos in ring.sorted_clockwise_from(pos):
return ring.server_at(server_pos) # first one clockwise owns it
return ring.first_server() # wrap past top of ring
function add_server(s, ring):
p = hash(s)
ring.insert(p, s)
# only keys between p and the previous server clockwise move to s
function remove_server(s, ring):
ring.delete(hash(s))
# s's keys now resolve to the next server clockwise; nothing else movesInstead of remapping N/(N+1) of the keys on a change, consistent hashing remaps on average only 1/N of them — the share owned by the single server that joined or left. That is the entire reason the technique exists.
3. Virtual Nodes
Plain consistent hashing has a weakness: with only one point per server, the arcs between servers are uneven. A server that happens to land far from its clockwise predecessor owns a large arc and a heavy share of keys; one that lands in a crowded stretch owns almost nothing. With a handful of servers this variance can be severe, and it gets worse when a server leaves — its entire arc dumps onto a single neighbor, which can then become a hotspot.
Virtual nodes fix this by giving each physical server many points on the ring instead of one. A server s0 is hashed under several derived labels — s0_0, s0_1, s0_2, and so on — and each label lands at its own position. A key still belongs to the first point clockwise, but that point now maps back to whichever physical server owns it.
- Smoother load. Scattering many small arcs per server averages out the gaps, so each physical server ends up with a share close to its fair fraction of the ring. More virtual nodes per server means lower variance.
- Graceful failure. When a server leaves, its many small arcs are absorbed by many different neighbors rather than dumped on one. The departing load spreads across the cluster instead of creating a single hotspot.
- Heterogeneous capacity. A more powerful machine can be given proportionally more virtual nodes, so it naturally owns a larger share of the ring without any special-case logic.
function build_ring(servers, vnodes_per_server):
ring = empty()
for s in servers:
for i in range(vnodes_per_server):
ring.insert(hash(f"{s.id}_{i}"), s) # many points, one server
return ring # lookup() is unchanged4. Replication
Up to here a key has exactly one owner, so a single server failure loses data and stalls every request for the keys it held. A real key-value store keeps each key on more than one server. The ring makes the replica set fall out naturally: store each key not only on its primary owner but on the next N servers walking clockwise from the key's position, where N is the replication factor.
The one subtlety is virtual nodes. Because a single physical server appears at many points on the ring, naively taking the next N points clockwise might land on several virtual nodes that all belong to the same physical machine — which would defeat the purpose of replicating. So when collecting the replica set you walk clockwise but skip points that map to a physical server already chosen, until you have N distinct physical servers. These N servers are often called the key's preference list.
function replica_set(key, ring, N):
pos = hash(key)
chosen = []
for vnode in ring.points_clockwise_from(pos):
server = ring.server_at(vnode)
if server not in chosen: # skip virtual duplicates
chosen.append(server)
if len(chosen) == N:
break
return chosen # the preference listWith replication in place, a key survives the loss of up to N-1 of its replicas, and reads and writes can be served by whichever replicas are reachable. That flexibility is exactly what forces the next set of decisions: if several replicas can each answer, how many must agree, and what happens when they disagree?
5. The CAP Theorem
Once data is replicated across machines connected by a network, you inherit a fundamental constraint. The CAP theorem says a distributed store can offer at most two of three properties at the same time:
- Consistency (C): every read sees the most recent write (or an error). All replicas appear to agree on a single, current value.
- Availability (A): every request gets a non-error response, even if it might not reflect the very latest write.
- Partition tolerance (P): the system keeps working even when the network drops or delays messages between some nodes.
The catch is that network partitions are not optional — links fail, packets are lost, nodes become unreachable. Any real distributed system must tolerate partitions, so P is a given. That means the genuine choice is what to do during a partition: sacrifice consistency to stay available, or sacrifice availability to stay consistent.
| System type | During a partition it... | Good for |
|---|---|---|
| CP (consistency + partition tolerance) | Refuses requests it cannot serve consistently — a replica that cannot confirm it has the latest value returns an error rather than stale data. | Workloads where a wrong or stale answer is worse than no answer: balances, inventory, configuration. |
| AP (availability + partition tolerance) | Always answers from whatever replicas are reachable, accepting that different sides of the partition may briefly diverge and reconcile later. | Workloads where being up matters most and brief staleness is tolerable: shopping carts, session data, feeds. |
6. Tunable Consistency: N, W, R
Rather than hard-coding CP or AP, many stores let you tune the tradeoff per operation using three numbers. With a replication factor N, a quorum scheme requires:
W— the number of replicas that must acknowledge a write before it is considered successful.R— the number of replicas that must respond to a read before the answer is returned.
A write is sent to all N replicas but the coordinator waits for only W acknowledgements; a read is sent to all N but returns once R have replied, taking the value with the newest version among them. By choosing W and R you slide between fast and strongly consistent.
| Setting | Behavior | Optimized for |
|---|---|---|
R = 1, W = N | Every write must reach all replicas; a read only needs one. Reads are cheap and fast because any single replica is guaranteed current; writes are slow and fragile (one down replica blocks the write). | Fast reads, read-heavy workloads. |
W = 1, R = N | A write succeeds as soon as one replica accepts it; a read must consult all replicas to be sure it sees the latest. Writes are cheap and fast; reads are slow. | Fast writes, write-heavy workloads. |
W + R > N | The set of replicas a write touched and the set a read touches are guaranteed to overlap by at least one. That overlapping replica always carries the latest value, so a read cannot miss the most recent write. | Strong consistency guaranteed. |
The condition W + R > N is the quorum guarantee, and the intuition is just the pigeonhole principle: if the write touched W of the N replicas and the read touches R of them, and W + R exceeds N, the two sets cannot be disjoint — at least one replica is in both, and that replica has the newest write. A common balanced choice is N = 3, W = 2, R = 2, which gives strong consistency (2 + 2 > 3) while tolerating one replica being down for both reads and writes.
function write(key, value, version, replicas, W):
acks = send_to_all(replicas, key, value, version)
return success when acks.count >= W # wait for W, not all N
function read(key, replicas, R):
responses = collect_from(replicas, key, until=R)
return responses.max_by(version) # newest version wins
# if W + R > N, the freshest value is guaranteed to be among them7. Versioning & Conflict Resolution
Quorums tell you how many replicas to wait for, but not how to decide which value is "newest" when two writes happened without seeing each other — for example on opposite sides of a partition, or with W < N. The store needs a way to attach a version to each value and to detect when two versions are concurrent rather than one being a clean successor of the other.
| Approach | How it works | Tradeoff |
|---|---|---|
| Vector clocks | Each value carries a vector of (node, counter) pairs. A node bumps its own counter on every write it coordinates. Comparing two vectors tells you whether one strictly descends from the other (keep the descendant) or whether they are concurrent (a genuine conflict). | Precisely detects concurrent writes without losing data, but the store must surface conflicts and let the client (or an application rule) merge them. Vectors can grow and need pruning. |
| Last-write-wins (LWW) | Tag each write with a timestamp; on conflict, simply keep the one with the larger timestamp and discard the other. | Trivially simple and conflict-free to resolve, but silently drops a concurrent write and depends on synchronized clocks, so it can lose data under skew. |
The difference is what they do with a true conflict. Vector clocks detect it and preserve both versions (called siblings) so nothing is lost until something merges them — a shopping cart, for instance, can union the two carts. Last-write-wins resolves it immediately by picking a winner, which is fine when losing one of two concurrent updates is acceptable and is far easier to operate.
function compare(v_a, v_b): # vector clocks
if v_a dominates v_b: return KEEP_A # a is a descendant of b
if v_b dominates v_a: return KEEP_B
return CONFLICT # concurrent -> keep both as siblings
function resolve_lww(a, b): # last-write-wins
return a if a.timestamp >= b.timestamp else b8. Anti-Entropy with Merkle Trees
Replicas drift apart over time — a write that only reached W of N nodes, a node that was down during an update, a dropped message. The store needs a background process to find and repair these divergences without comparing every key on every replica, which would be hopelessly expensive for large datasets. This reconciliation is called anti-entropy, and the efficient tool for it is the Merkle tree.
A Merkle tree is a tree of hashes built over a replica's key range: each leaf hashes a small bucket of keys, and each internal node hashes its children. Two replicas compare their trees from the top down. If two root hashes match, the entire range is identical and nothing more needs to be checked. If they differ, the replicas descend into only the children whose hashes disagree, and so on, narrowing in on exactly the buckets that diverge.
The win is the amount of data exchanged. To find the differences between two replicas you transfer and compare only hashes along the divergent paths — logarithmic in the size of the dataset — rather than shipping every key across to compare. Once the differing buckets are pinpointed, only those keys are exchanged and repaired.
9. Failure Handling
The final pieces keep the cluster coherent as nodes come and go. Two lightweight mechanisms cover the common cases.
- Gossip for membership. Rather than a central registry that itself becomes a single point of failure, each node periodically exchanges a small status message with a few random peers — who is up, who is down, ring positions, versions. Over a few rounds this gossip propagates the full membership view to every node. It is decentralized, scales well, and tolerates the very failures it is reporting.
- Hinted handoff for temporary failures. When a write's target replica is briefly unreachable, the coordinator does not simply fail. It writes the value to another healthy node along with a hint recording which node the data really belongs to. When the intended replica recovers, the holder replays the hinted writes to it and then discards the hint. This keeps writes available through short outages and lets the cluster heal itself once the node returns.
function gossip_round(self, peers):
peer = random.choice(peers)
merge(self.membership, peer.membership) # exchange + reconcile views
function write_with_handoff(key, value, replicas):
for r in replicas:
if r.is_up():
r.store(key, value)
else:
backup = pick_healthy_node()
backup.store_hint(key, value, intended=r) # replay when r returns10. Summary
A distributed key-value store is consistent hashing plus a series of deliberate tradeoffs layered on top of it:
| Concern | Mechanism |
|---|---|
| Which server holds a key? | Hash keys and servers onto one ring; a key belongs to the first server clockwise. |
Why not hash(key) % N? | Changing N remaps almost every key — a cache-miss storm and a full data reshuffle. The ring moves only ~1/N of keys per change. |
| How is load kept even? | Virtual nodes: each physical server occupies many ring points, smoothing variance and spreading the load of a departed node. |
| How does data survive failure? | Replicate each key onto the next N distinct physical servers clockwise (the preference list). |
| What gives during a partition? | CAP forces a choice: CP refuses to serve stale data; AP stays available and reconciles later. |
| How is the tradeoff tuned? | Quorum N, W, R: W+R > N guarantees overlap and strong consistency; skew W/R for fast writes or fast reads. |
| How are conflicts resolved? | Vector clocks detect concurrent writes and keep siblings; last-write-wins picks a timestamp winner more simply. |
| How do replicas stay in sync? | Anti-entropy with Merkle trees finds divergent buckets cheaply; read-repair fixes hot keys inline. |
| How is membership and transient failure handled? | Gossip spreads the cluster view; hinted handoff keeps writes available through short outages. |