Common Patterns
A field guide to the recurring building blocks of system design — the handful of problems that show up in almost every large system, and the standard ways to solve each one. Each pattern is framed as a problem, the main approaches, and when to reach for which.
Most system-design problems are combinations of a small number of recurring sub-problems. You rarely invent a new way to push live updates or scale reads — you recognize the shape of the problem and apply a known pattern, then reason about its trade-offs for your specific constraints. This page collects the most common of those patterns. Knowing them turns a blank-page design question into a matter of selection: name the sub-problem, pick the fitting pattern, and justify the choice.
Contents
1. Pushing Real-Time Updates
Problem: the server has new information (a chat message, a price tick, a notification) and the client needs to see it promptly, without the user refreshing. HTTP is request-response, so the challenge is getting data to a client that did not just ask for it.
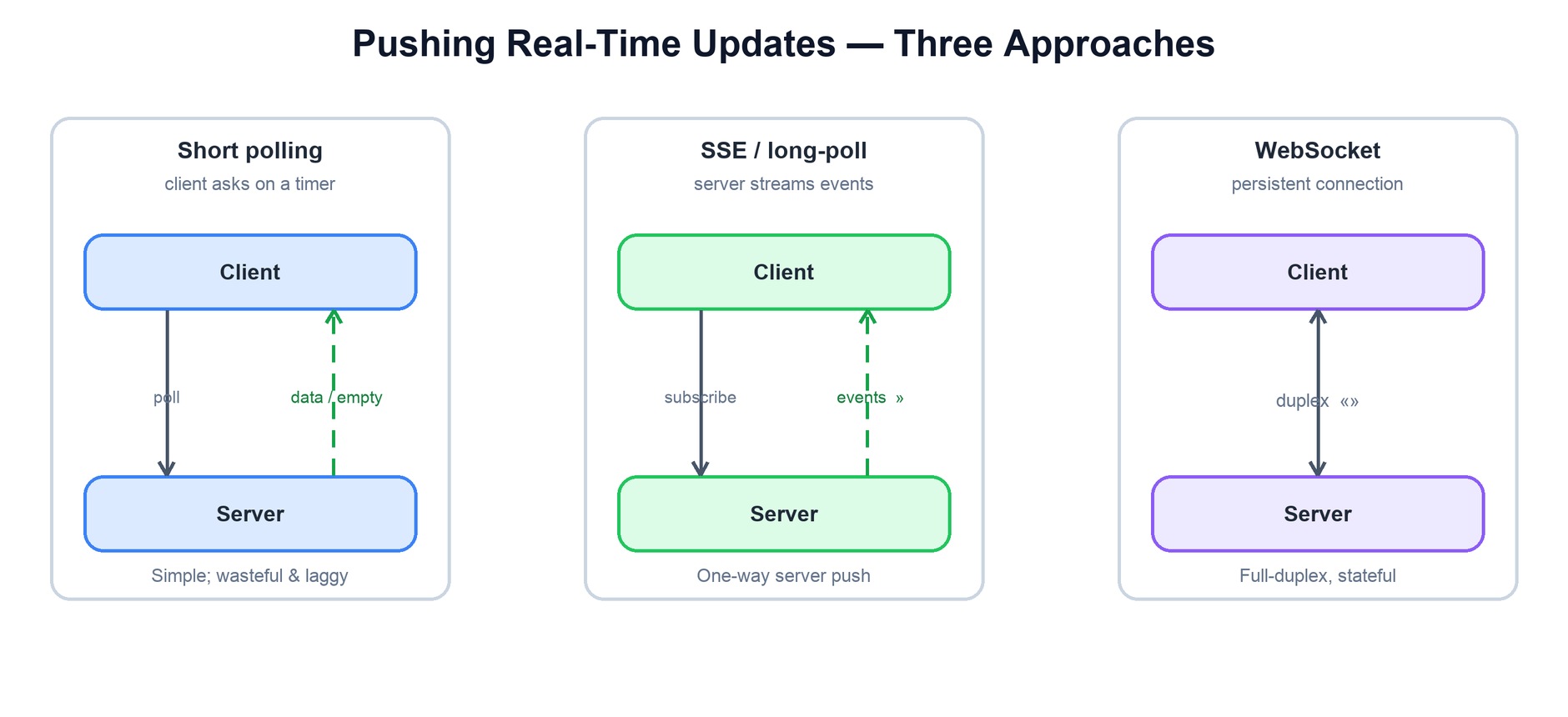
| Approach | How it works | Use when |
|---|---|---|
| Short polling | Client requests on a fixed timer; server answers with new data or nothing. | Updates are infrequent and a few seconds of lag is fine. Simplest to build. |
| Long polling | Client request is held open until there is data (or a timeout), then immediately re-issued. | You want near-instant delivery but must stay on plain HTTP / simple infra. |
| Server-sent events (SSE) | One long-lived HTTP stream the server pushes events down. One-way only. | Server-to-client streams: feeds, notifications, live dashboards. |
| WebSockets | A persistent, full-duplex TCP connection both sides can send on. | Truly interactive, low-latency, bidirectional traffic: chat, games, collaboration. |
2. Managing Long-Running Tasks
Problem: some work takes too long to finish inside a request — video transcoding, report generation, sending a million emails. Doing it synchronously ties up a server, risks timeouts, and gives the user a spinner for minutes.
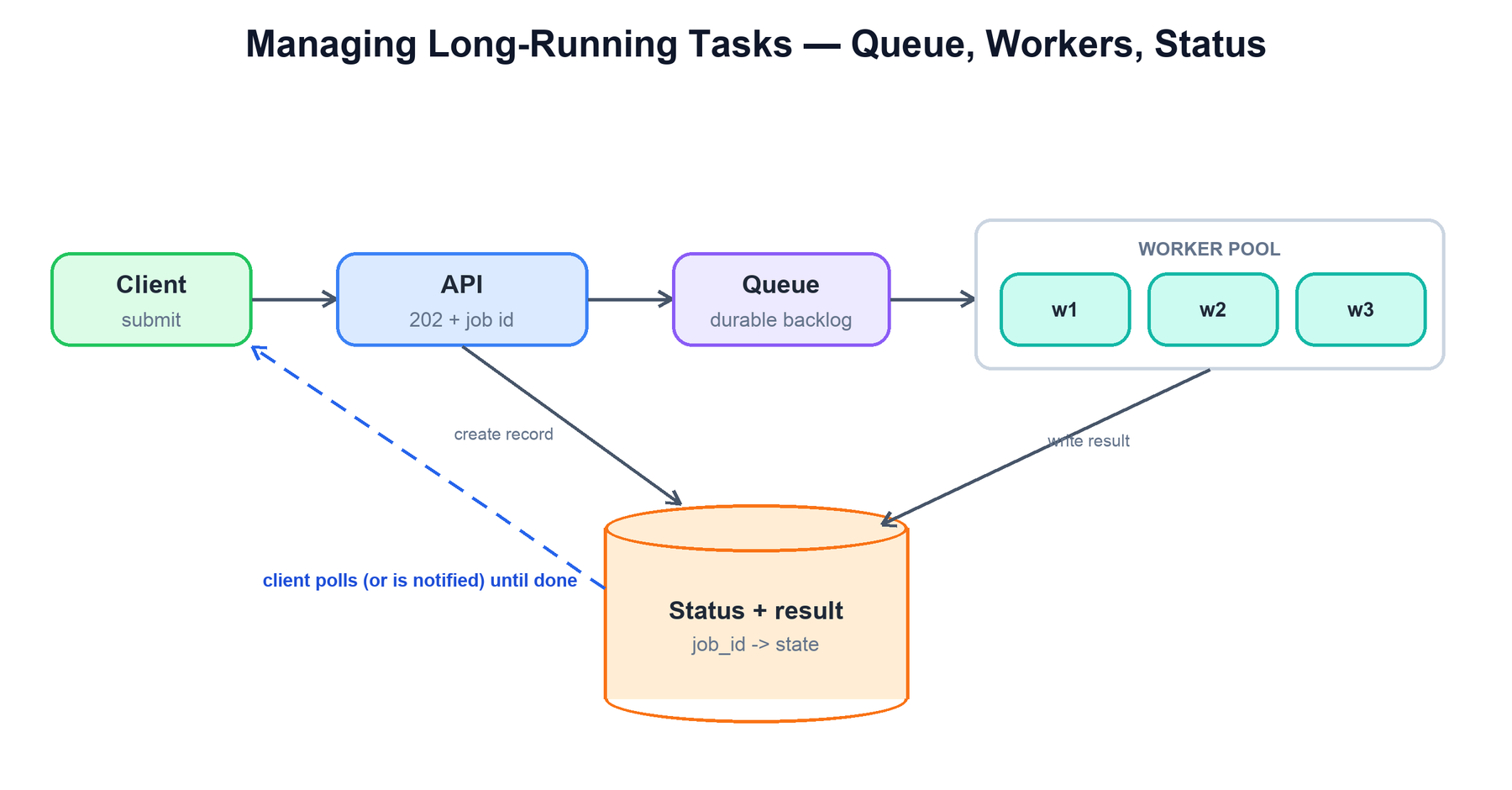
The pattern is accept-and-defer: the API validates the request, writes a job record, puts it on a queue, and returns 202 Accepted with a job id. A pool of workers pulls from the queue and processes jobs in the background, writing progress and results to a status store. The client learns the outcome by polling the job status or being notified (webhook / push) when it completes.
- Decoupling & durability. The queue buffers bursts and survives crashes — a worker dying just means the job is retried, not lost.
- Elastic throughput. Scale workers independently of the API tier; the queue depth tells you when to add more.
- Make jobs idempotent. At-least-once delivery means a job can run twice — see §10.
3. Dealing with Contention
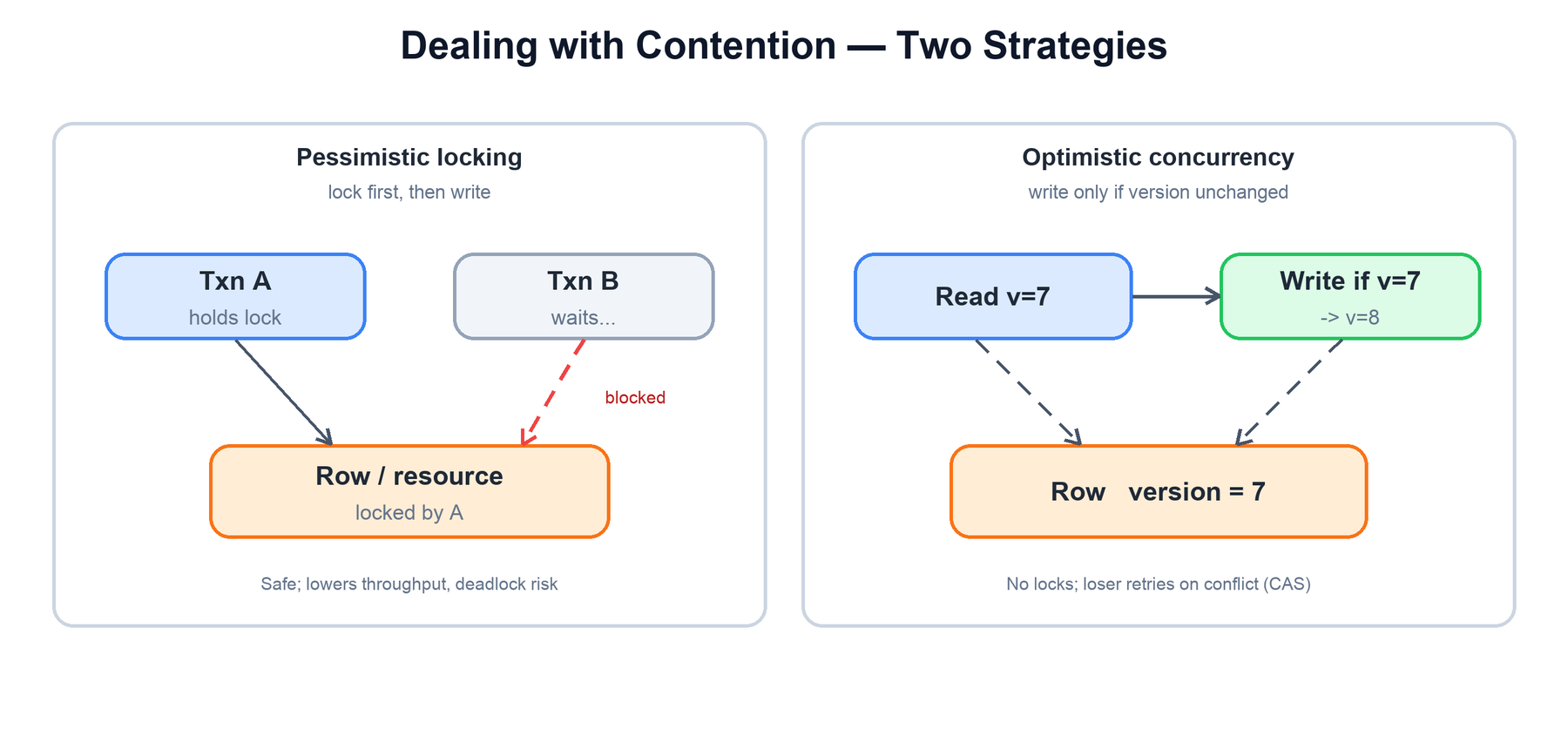
Problem: multiple clients try to read-modify-write the same resource at the same time — the last seat on a flight, a counter, an account balance. Without coordination they overwrite each other and you get lost updates or oversells.
| Strategy | How it works | Use when |
|---|---|---|
| Pessimistic locking | Acquire a lock (row lock, SELECT ... FOR UPDATE) before reading; others wait. | Conflicts are frequent and retrying is expensive; short critical sections. |
| Optimistic concurrency (OCC) | Read a version, do the work, write only if the version is unchanged (compare-and-set). Loser retries. | Conflicts are rare; you want maximum concurrency and no held locks. |
| Atomic operations | Push the whole change into one atomic primitive (INCR, conditional update) the datastore serializes for you. | The update is a simple, expressible mutation (counters, sets). |
| Distributed lock | A lock held in an external store (Redis, ZooKeeper) coordinates across processes/machines. | The resource spans services and no single database can arbitrate. |
4. Scaling Reads
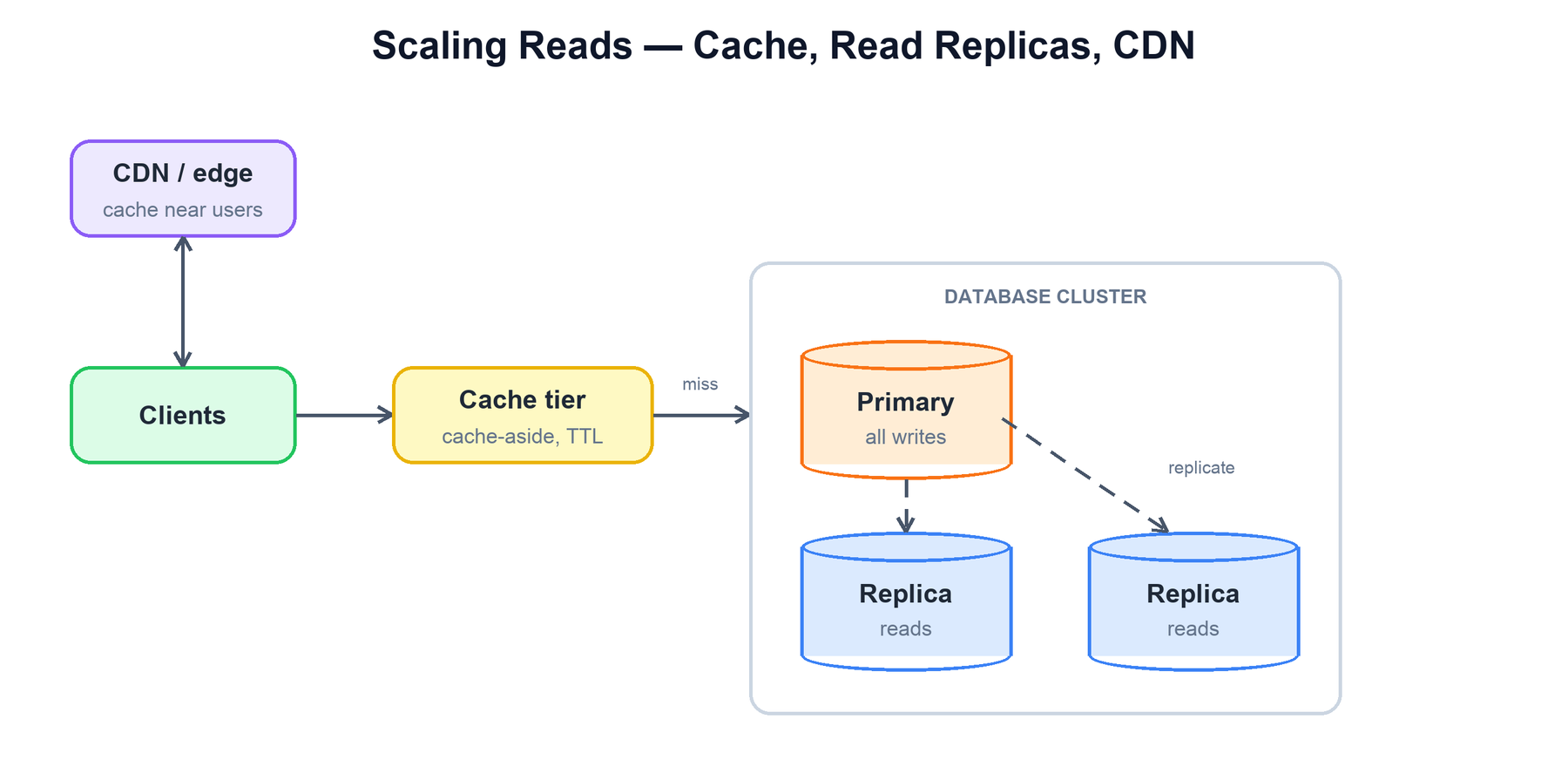
Problem: read traffic vastly outweighs writes (often 100:1 or more) and a single database can't serve it. The goal is to add read capacity and cut latency without compromising the write path.
| Technique | How it works | Cost / caveat |
|---|---|---|
| Caching | Keep hot results in memory (cache-aside, with TTLs) so most reads never hit the database. | Invalidation and staleness; cold-cache and thundering-herd risk. |
| Read replicas | Replicate the primary to read-only copies and route reads to them. | Replication lag means replicas can serve slightly stale data. |
| CDN / edge | Serve cacheable responses from points of presence close to users. | Best for static or slowly-changing content; needs cache-control discipline. |
| Denormalization / materialized views | Precompute the shape the read needs so a query is a single lookup. | More write-time work and storage; views must be kept in sync. |
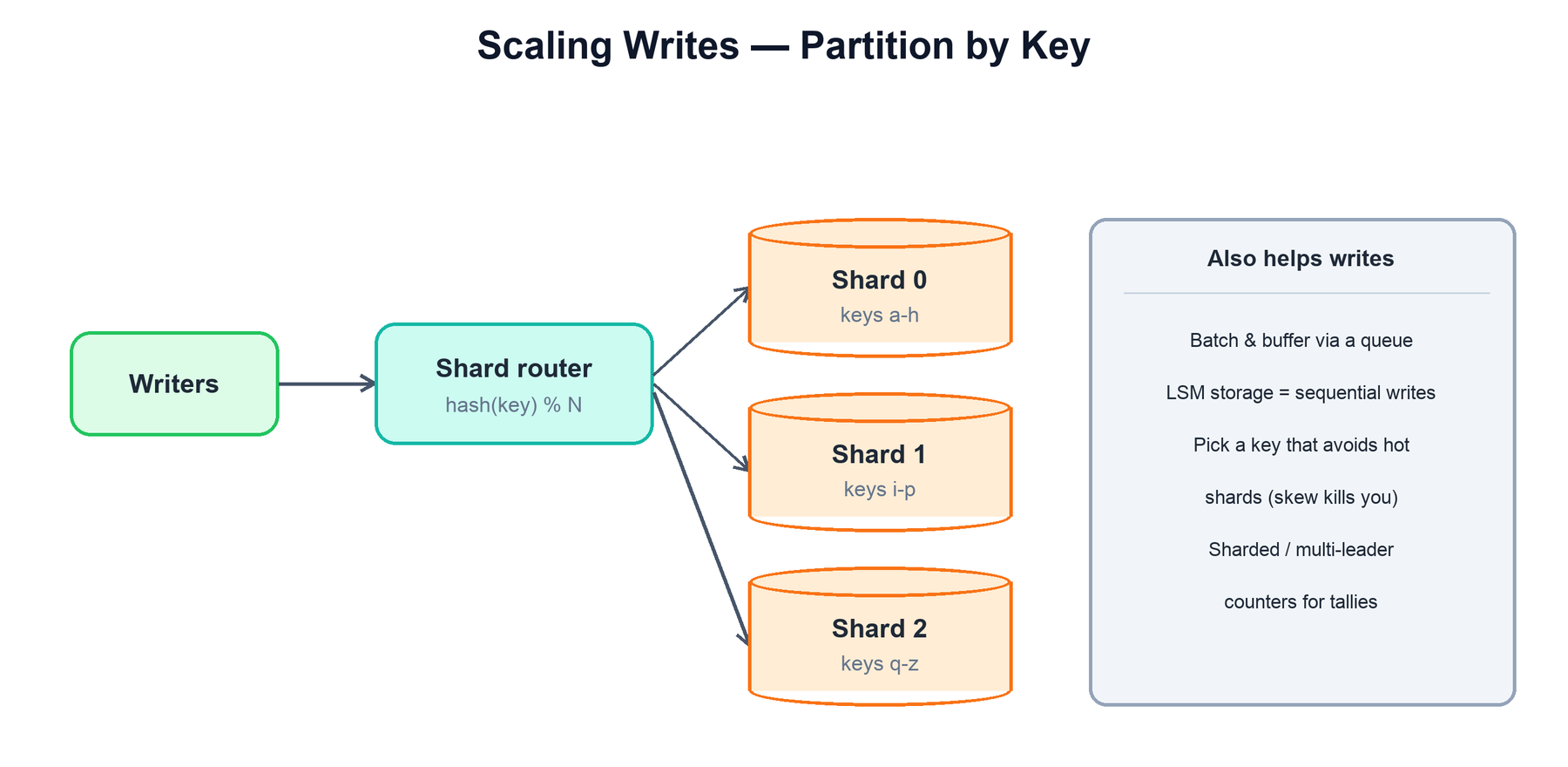
5. Scaling Writes
Problem: a single node can't absorb the write throughput — too many inserts per second, or a working set too large for one machine. Writes are harder to scale than reads because you can't just add read-only copies.
| Technique | How it works | Use when |
|---|---|---|
| Partitioning / sharding | Split data across shards by a key (hash or range); each shard takes a fraction of writes. | The dominant lever. Needs a shard key that spreads load evenly. |
| Batching & buffering | Accept writes into a queue/log and apply them in batches downstream. | Smooths spikes and turns many small writes into fewer large ones. |
| LSM-tree storage | Engines (Cassandra, RocksDB) that turn random writes into sequential appends. | Write-heavy workloads where sequential I/O is far cheaper. |
| Sharded / async counters | Split a hot counter into many sub-counters, or aggregate asynchronously. | A single hot row (likes, views) that would otherwise serialize all writes. |
6. Handling Large Blobs
Problem: users upload and download large binary files — images, video, documents. Streaming gigabytes through your application servers and storing them in your primary database wrecks both.
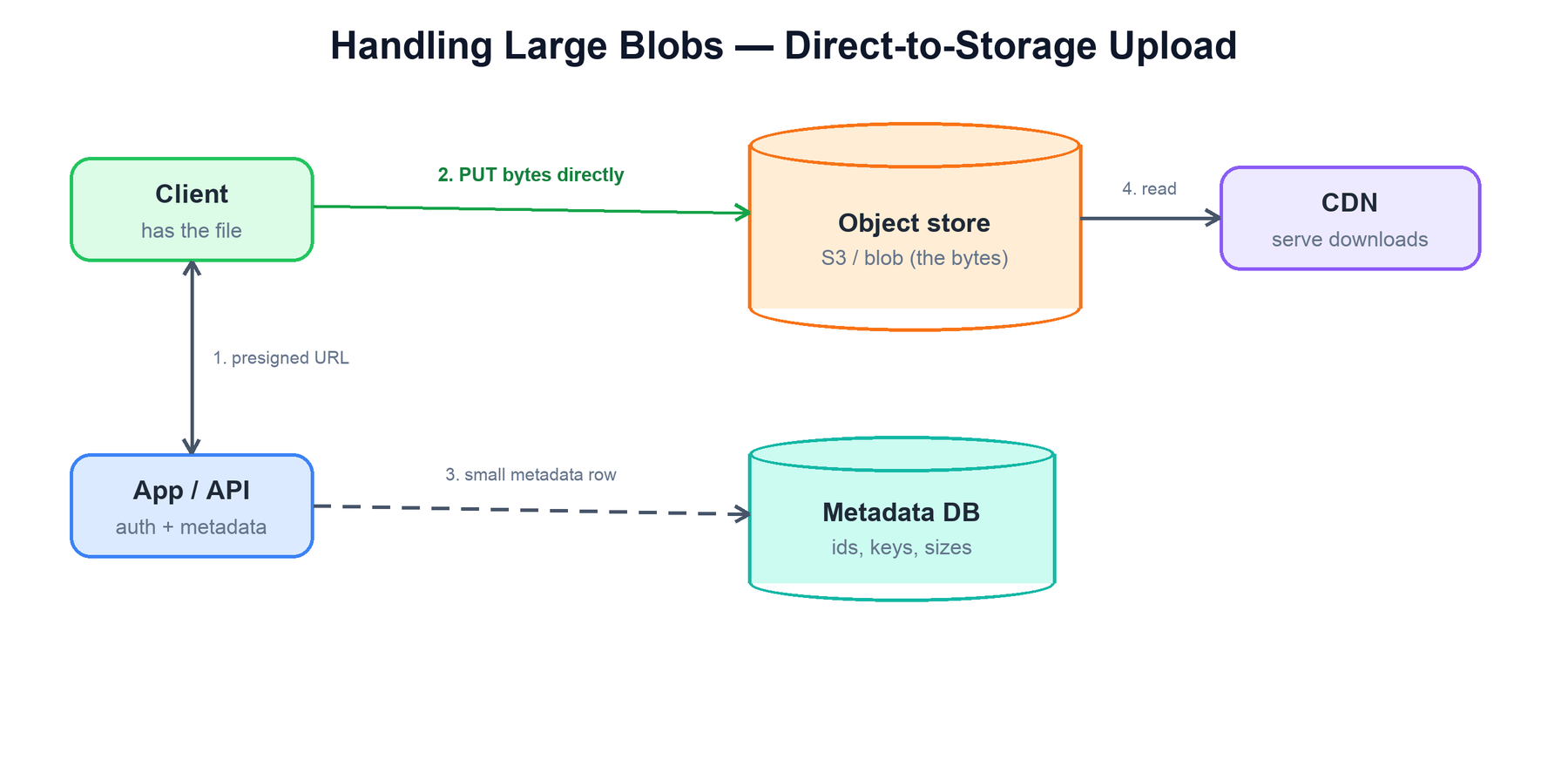
The pattern separates bytes from metadata:
- Object storage for the bytes. Files live in a blob store (S3, GCS) built for cheap, durable, massive objects — never in the relational database.
- Direct, presigned transfer. The app issues a short-lived presigned URL and the client uploads (and downloads) straight to/from object storage, so the file never passes through your servers.
- Metadata in the database. Your database stores only a small row: id, storage key, size, owner, content type — the things you query on.
- CDN for downloads. Serve reads through a CDN so popular files are cached near users.
7. Multi-Step Processes
Problem: a business operation spans several services and can't be wrapped in one database transaction — placing an order needs to reserve inventory, charge payment, and create a shipment, each owned by a different service with its own database. If a later step fails, the earlier ones must be undone.
The obvious instinct is a distributed transaction — a two-phase commit (2PC) across all the databases so they commit or roll back together. In practice 2PC is avoided at scale: it holds locks across services for the duration of the transaction, the central coordinator is a single point of failure, and most modern datastores and message brokers don't support it. So instead of one big atomic transaction, we break the work into a chain of small local ones and accept eventual consistency. That chain is a saga.
What is a saga?
A saga is a sequence of local transactions, one per service. Each step commits independently in its own database, and each has a paired compensating transaction that semantically undoes it — not a literal rollback (the data is already committed), but a new action that reverses the effect: refund the charge, release the reservation, cancel the shipment. The saga runs the steps forward; if step N fails, it runs the compensations for steps N−1 … 1 in reverse, leaving the system in a consistent end state without ever holding a cross-service lock.
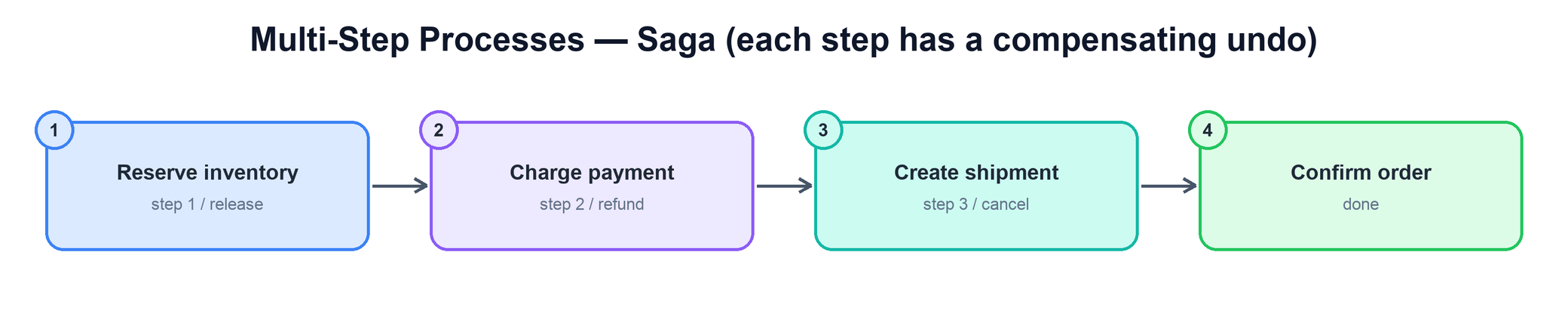
The term comes from a 1987 paper by Garcia-Molina and Salem describing how to handle "long-lived transactions" without holding locks for their entire duration — exactly the microservices problem decades early. There are two ways to coordinate the steps: orchestration and choreography.
Orchestration — a central coordinator
An orchestrator is a dedicated component that owns the workflow. It knows the full sequence, calls each service in turn (usually by sending a command and awaiting a reply), records progress in a durable saga log, and — when a step fails — issues the compensating commands in reverse. The services themselves stay dumb: they just expose "do this step" and "undo this step" operations.
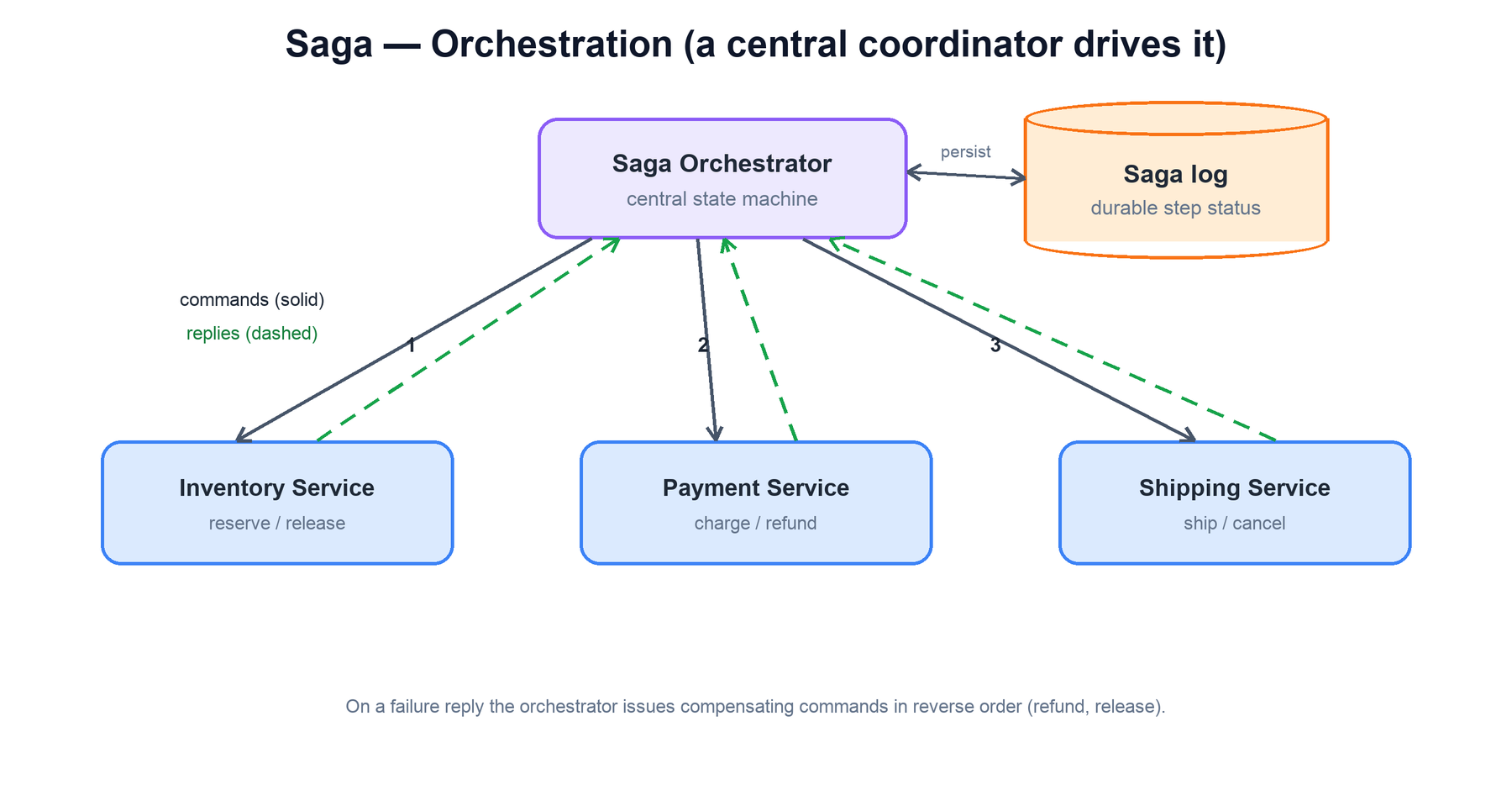
Implemented as a state machine, the orchestrator persists its position after every step so that, if it crashes, it resumes from exactly where it left off rather than restarting or double-charging:
function run_order_saga(order):
state = saga_log.start(order.id) # persisted before any step
try:
res = inventory.reserve(order) # step 1 (idempotent, keyed by order.id)
saga_log.record("reserved", res) # checkpoint after each step
pay = payment.charge(order) # step 2
saga_log.record("charged", pay)
ship = shipping.create(order) # step 3
saga_log.record("shipped", ship)
return saga_log.complete()
except StepFailed as f:
# run compensations in reverse for whatever already succeeded
if saga_log.has("charged"): payment.refund(order)
if saga_log.has("reserved"): inventory.release(order)
saga_log.fail(f)You rarely hand-roll this. A workflow engine provides the durable state, retries, timeouts, and resume-after-crash for you:
- Temporal (and its predecessor Cadence) — you write the workflow as ordinary code; the engine persists every step's result and transparently replays your function to rebuild state after a failure. Compensations are just normal code in a
catchblock. - AWS Step Functions — the workflow is a declarative JSON/YAML state machine; a managed service runs it, retries states, and invokes Lambdas or service calls per step.
- Netflix Conductor and Camunda / Zeebe — workflow servers where the flow is defined as JSON or BPMN and workers poll for tasks to execute.
Choreography — services react to events
Choreography has no coordinator. Each service publishes an event when it finishes its local transaction; other services subscribe to the events relevant to them, do their step, and publish the next event. The end-to-end flow is an emergent chain of events rather than a script anyone owns.
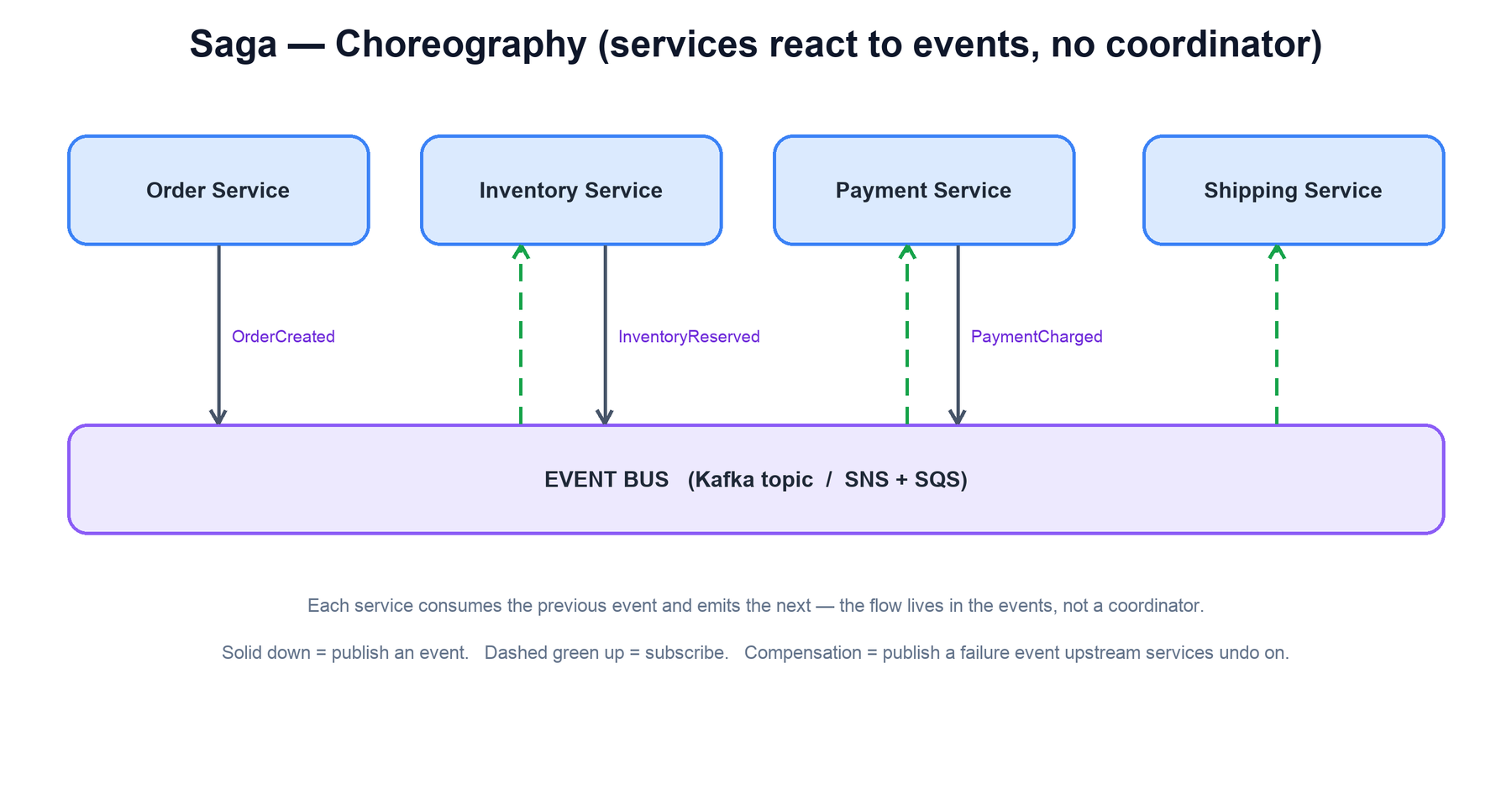
# Inventory Service — reacts to the order event, emits the next event
on event OrderCreated(order):
if reserve(order): # local transaction
publish InventoryReserved(order)
else:
publish InventoryFailed(order) # triggers no further steps
# Payment Service — reacts to the inventory event
on event InventoryReserved(order):
if charge(order):
publish PaymentCharged(order)
else:
publish PaymentFailed(order) # compensation trigger ...
# Inventory compensates when it hears a downstream failure
on event PaymentFailed(order):
release(order) # undo its own earlier stepThe event bus is the backbone. Apache Kafka is the common choice — a durable, replayable log of topics services subscribe to. On AWS the equivalent is SNS + SQS (fan-out topic into per-consumer queues) or EventBridge; RabbitMQ and NATS fill the same role elsewhere. Whatever the broker, the consumers must handle redelivery, since these systems deliver at least once.
Choosing between them
| Dimension | Orchestration | Choreography |
|---|---|---|
| Where the logic lives | Centralized in the orchestrator — one place to read the whole flow. | Spread across services as event handlers — no single source of truth. |
| Coupling | Services coupled to the orchestrator, not to each other. | Loosely coupled; services only know events, not each other. |
| Observability | Easy — the saga log is the audit trail. | Harder — you reconstruct the flow by tracing events across services. |
| Failure handling | Compensation logic is explicit and ordered in one place. | Compensation is distributed; risk of event cycles and missed cases. |
| Best for | Complex flows, many steps, where visibility and control matter. | Simple, linear flows and high decoupling between teams. |
What every saga implementation must get right
- Idempotency. Both steps and compensations get retried (crashes, redelivery), so each must be safe to apply more than once — key each operation by the saga/order id (see §10).
- Atomic "commit-and-publish". A service must commit its local change and emit its event as one unit; if it commits but dies before publishing, the saga stalls. The transactional outbox pattern solves this: write the event into an
outboxtable in the same database transaction as the state change, then a separate relay (often Kafka Connect / Debezium reading the change log) publishes it reliably. - Compensations that can always succeed. An undo can't itself be rejected — you can't "un-charge" a card that's now frozen — so design compensations as new corrective actions (issue a refund) and use semantic locks (mark a record
PENDING) to keep others from acting on half-finished state. - Timeouts. A step that never replies must eventually be treated as failed and compensated, or the saga hangs forever.
8. Proximity-Based Services
Problem: "find things near me" — nearby drivers, restaurants, friends. Latitude/longitude are two independent dimensions, so a plain B-tree index can filter one but not both efficiently, and scanning every point is hopeless at scale.
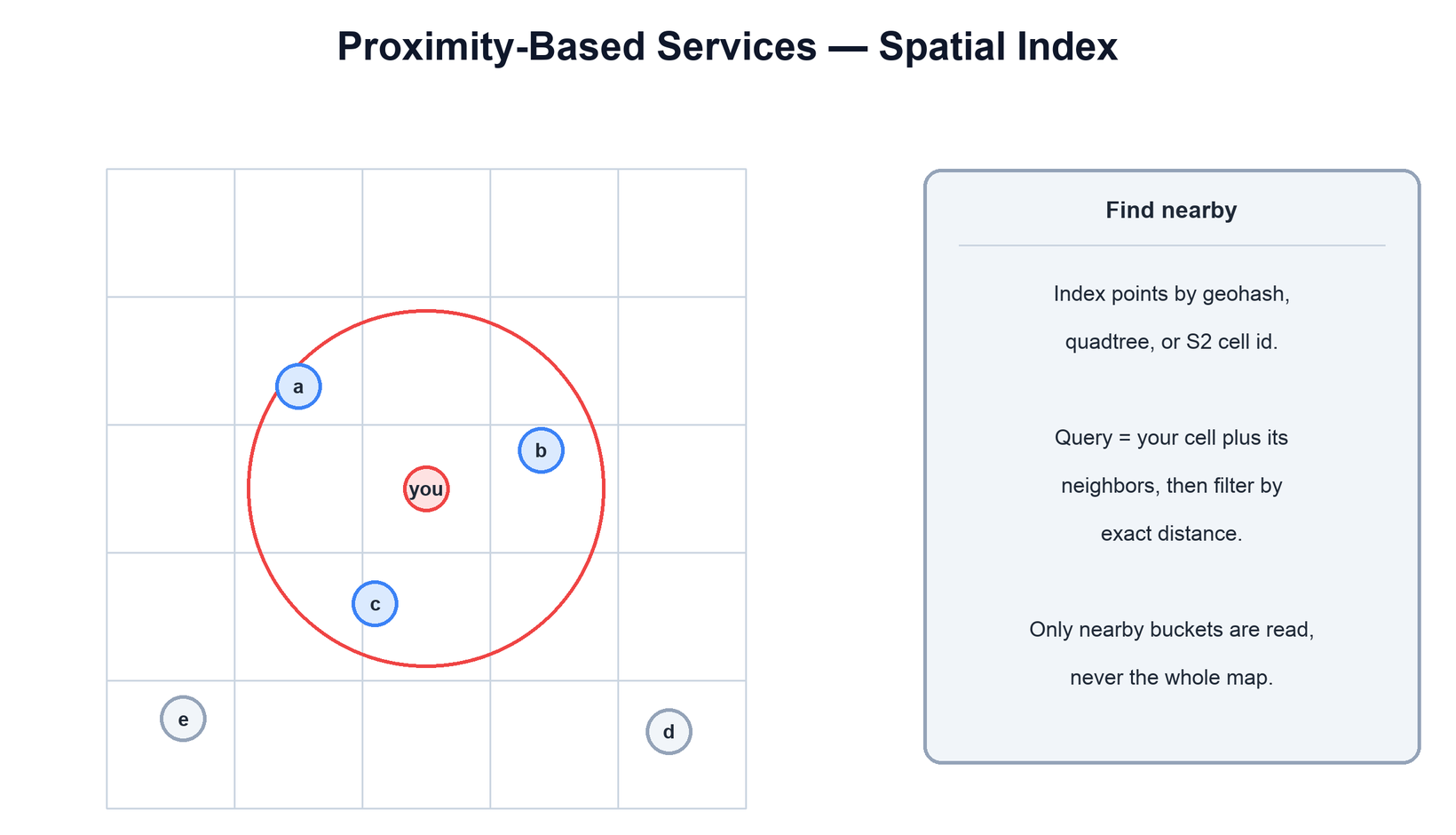
The fix is a spatial index that maps two-dimensional location to a one-dimensional, locality-preserving key, so nearby points share key prefixes and land in the same or adjacent buckets:
- Geohash. Encodes lat/lng into a short string where a shared prefix means physical proximity — easy to store and range-query in any database.
- Quadtree. Recursively subdivides space into quadrants, going deeper only where points are dense.
- S2 / H3. Production-grade cell systems (Google S2, Uber H3) that tile the globe with stable cell ids.
A query becomes: compute your cell, gather it and its neighbors, then filter those candidates by exact distance. You read a handful of buckets instead of the entire map. Many databases ship this built in (PostGIS, Elasticsearch geo_point, Redis geo commands).
9. Rate Limiting & Throttling
Problem: you must cap how often a client can call you — to protect against abuse and runaway loops, to enforce API quotas, and to keep one noisy tenant from starving everyone else. (Not in the original list, but it pairs with nearly every other pattern here.)
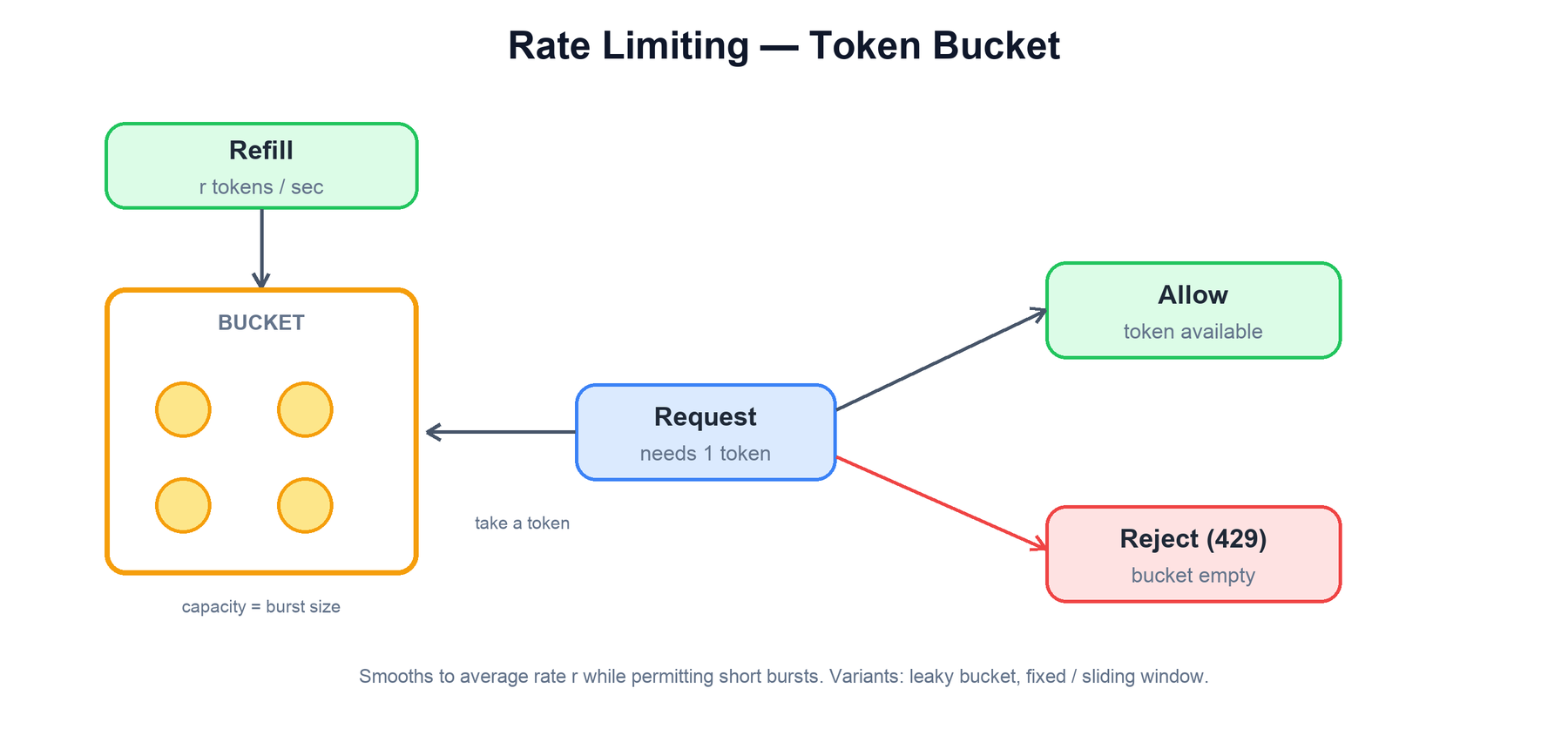
| Algorithm | How it works | Character |
|---|---|---|
| Token bucket | Tokens refill at rate r up to a capacity; each request spends one. | Smooth average rate, allows bursts up to capacity. The common default. |
| Leaky bucket | Requests queue and drain at a fixed rate. | Enforces a strictly steady output rate; smooths bursts out. |
| Fixed window | Count requests per calendar window (e.g. per minute). | Simple, but allows 2× bursts straddling a window boundary. |
| Sliding window | A rolling count over the trailing interval. | Accurate, avoids the boundary spike; a bit more state to track. |
429 Too Many Requests and a Retry-After header so well-behaved clients back off. In a distributed fleet the limiter state must be shared (e.g. counters in Redis) or each node enforces only its slice of the limit.10. Idempotency & Safe Retries
Problem: networks fail mid-request, so clients and queues retry — but retrying "charge the card" or "place the order" must not do it twice. You need an operation that has the same effect whether it runs once or many times. (Also an addition — it's the safety net under long-running tasks, queues, and sagas.)
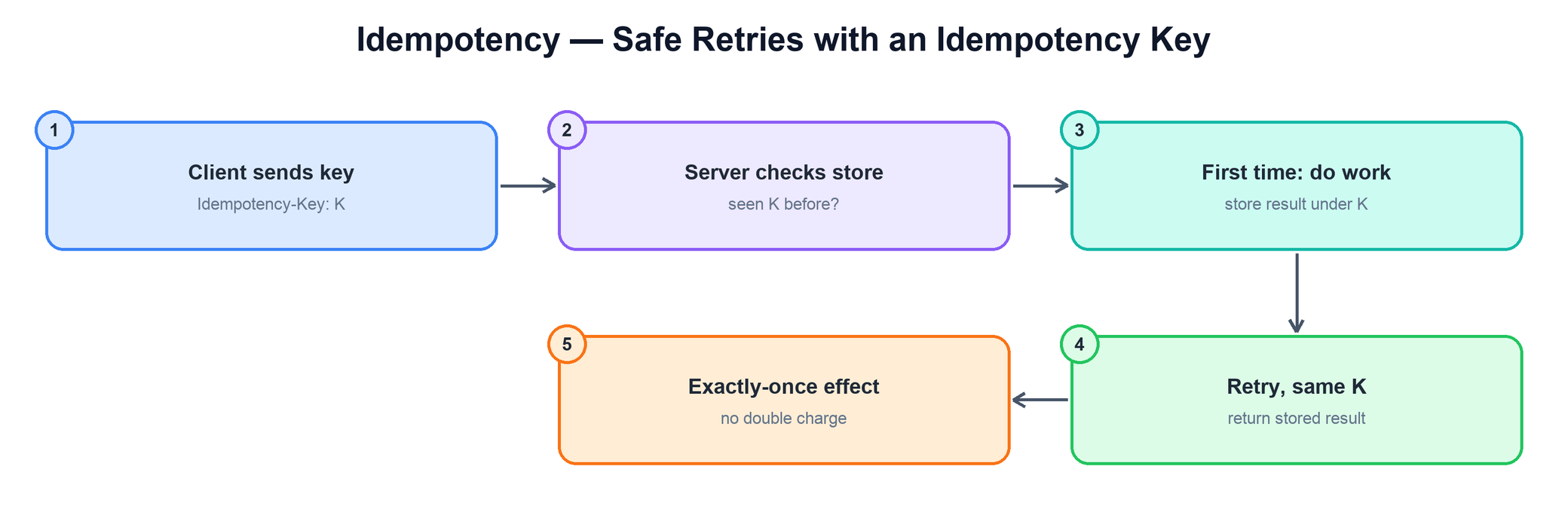
The standard mechanism is the idempotency key: the client generates a unique key per logical operation and sends it on every attempt. On first receipt the server does the work and records the outcome under that key; on any retry with the same key it returns the stored result instead of acting again.
function handle(request, key):
existing = store.get(key)
if existing != null:
return existing.result # retry: replay the saved outcome
result = do_work(request) # first time only
store.put(key, result) # atomically, so concurrent retries are safe
return result- Natural idempotency. Some operations are inherently safe to repeat —
PUTof a full resource,set x = v. Prefer designing for these. - Dedup by key. For non-idempotent effects (payments, sends), the key + result store turns at-least-once delivery into exactly-once effect.
- Everywhere there are retries. Queues, sagas, and webhooks all redeliver, so make their consumers idempotent by default.
11. Summary & Cheat Sheet
When a design question appears, name the sub-problem and reach for its pattern:
| When you need to… | Reach for |
|---|---|
| Push data to clients live | Polling → SSE → WebSockets, with pub/sub fan-out behind a connection gateway. |
| Do slow work off the request path | Queue + worker pool + status store; return 202 and track the job. |
| Stop concurrent writers clobbering each other | Atomic op or optimistic concurrency first; pessimistic / distributed lock when conflicts are common. |
| Serve far more reads than one DB can | Cache → read replicas → CDN → denormalized views, sized to your staleness budget. |
| Absorb more writes than one node can | Partition by a well-chosen shard key; batch, use LSM storage, split hot counters. |
| Move big files around | Object storage + presigned direct transfer + metadata-only DB + CDN; multipart for huge uploads. |
| Coordinate steps across services | Saga with compensating actions; orchestrate or choreograph; expect eventual consistency. |
| Answer "what's near me" | Spatial index (geohash / quadtree / S2); query nearby cells, then filter by exact distance. |
| Cap request rates | Token bucket (or leaky / sliding window); reject with 429 + Retry-After. |
| Make retries safe | Idempotency keys + a result store; design for naturally idempotent operations. |