Designing Collaborative Editing
A system design interview guide to building a Google-Docs-style editor where many people type into the same document at the same time and every screen ends up showing exactly the same text.
Real-time collaborative editing looks like magic the first time you see two cursors moving in the same paragraph, but underneath it is one of the cleaner distributed-systems problems you will be asked to design. The single hard requirement is convergence: no matter who typed what, in what order, or on which flaky network, every copy of the document must end up identical. That sounds obvious until you notice that two people can edit the same character position at literally the same moment, and there is no global clock that says which one happened first. This guide builds up the design from that core problem, walks through the two dominant approaches (Operational Transformation and CRDTs), covers the sync architecture that ties clients together, and then handles the practical parts an interviewer will push on: cursors, offline edits, and the tradeoffs between the approaches.
Contents
1. The Core Problem
The document is shared mutable state, and several clients hold their own copy of it. Each client edits its local copy instantly — you cannot wait for a network round trip before showing the user the letter they just typed, or the editor feels broken. That means edits happen optimistically and locally, and only afterwards travel to everyone else. The moment you allow that, you have admitted concurrency: two clients can make edits that neither has seen yet, and those edits can touch the same region of the document.
The trap is to think of an edit as "the new text." If Alice replaces the whole document with her version and Bob replaces it with his, the last write wins and one person's work silently vanishes. The fix is to represent each change as a small, position-aware operation — "insert the character X at position 5," "delete the character at position 0" — rather than a whole-document snapshot. Operations are tiny, they can be ordered and replayed, and they describe intent rather than result. But operations alone are not enough, because a position like "5" means different things on two copies that have already diverged. Resolving that mismatch is the entire subject of the next two sections.
2. Operational Transformation
Operational Transformation (OT) is the older and most battle-tested approach, and it is what classic Google Docs is built on. The idea is to keep editing in terms of operations against integer positions, but to transform each incoming operation so it accounts for the concurrent operations the receiver has already applied. If Bob deleted a character near the start of the document, then Alice's "insert at position 5" needs to become "insert at position 4" before Bob applies it, because his copy is now one character shorter. The transform function adjusts the indices so that both sides converge on the same final text and so that each person's original intention is preserved.
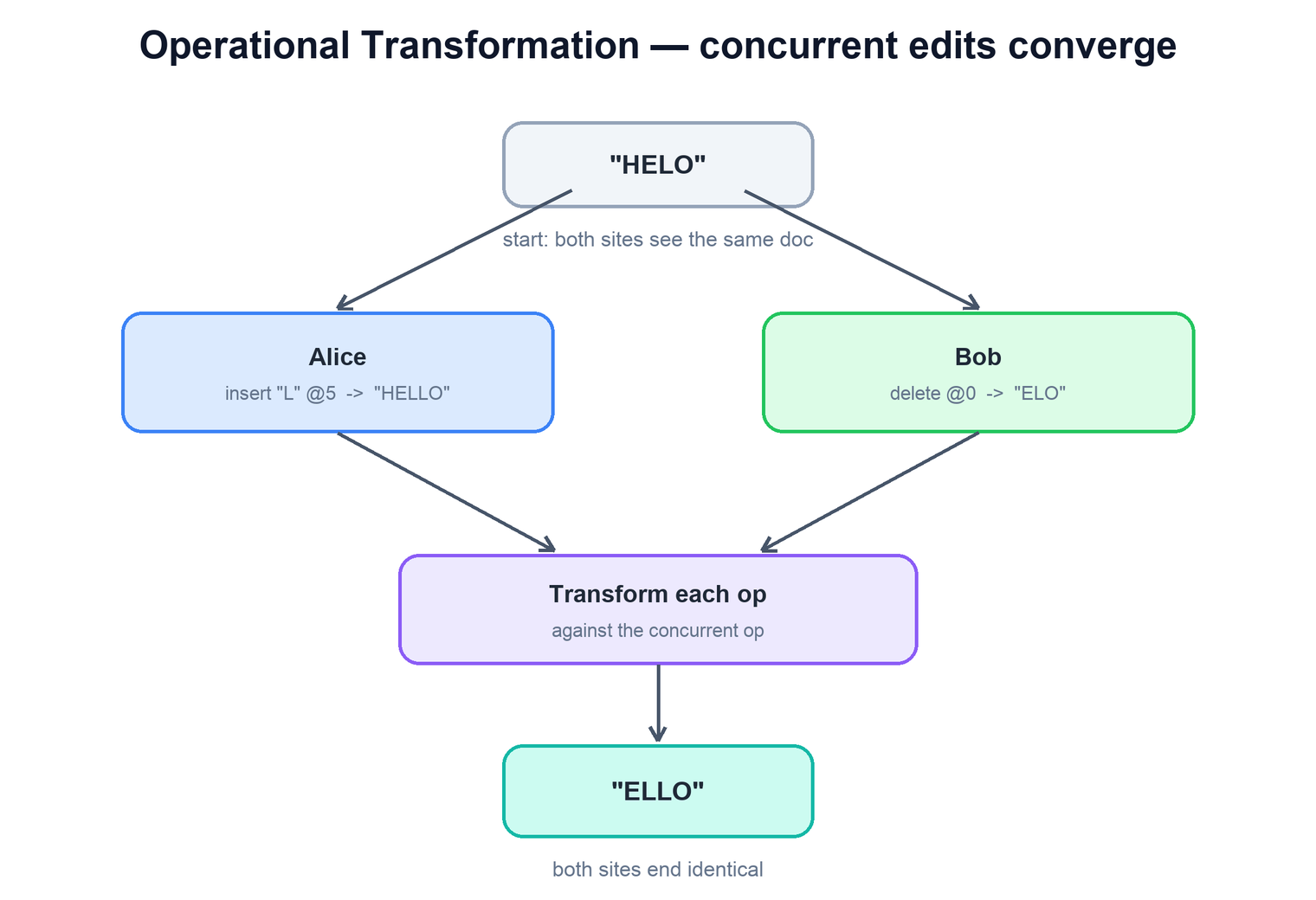
The transformation rules are deceptively subtle. There is a small matrix of cases — insert against insert, insert against delete, delete against insert, delete against delete — and each must be defined so that applying the transformed operations in any order yields the same result. Getting these rules provably correct is famously error-prone; several published OT algorithms were later found to have edge cases that failed to converge. The practical consequence is that OT almost always relies on a central server to impose a total order on operations. The server decides the canonical sequence, and clients transform their pending local operations against the server's sequence as it streams back to them. This sidesteps the hardest multi-party transformation cases by reducing every client's job to "reconcile my local edits against one authoritative stream."
# transform op A so it can apply after concurrent op B
function transform(a, b):
if a.type == INSERT and b.type == INSERT:
if b.pos < a.pos or (b.pos == a.pos and b.site < a.site):
a.pos += 1 # b inserted before a, shift right
if a.type == INSERT and b.type == DELETE:
if b.pos < a.pos:
a.pos -= 1 # b removed a char before a
# ... delete-vs-insert and delete-vs-delete cases ...
return a3. CRDTs
Conflict-free Replicated Data Types (CRDTs) attack the same problem from the other end. Instead of transforming operations at apply time, you design the data and operations so that concurrent updates commute — applying them in any order produces the same state, with no transformation step at all. For text, the trick is to stop using integer positions, which are unstable, and give every character a unique, globally ordered identifier that never changes once assigned. An insert says "place this character with id 1.5," and merging is just "take the union of all characters and sort by id." Because ids are immutable and totally ordered, two clients that have seen the same set of operations will always lay the characters out in the same order, regardless of arrival sequence.
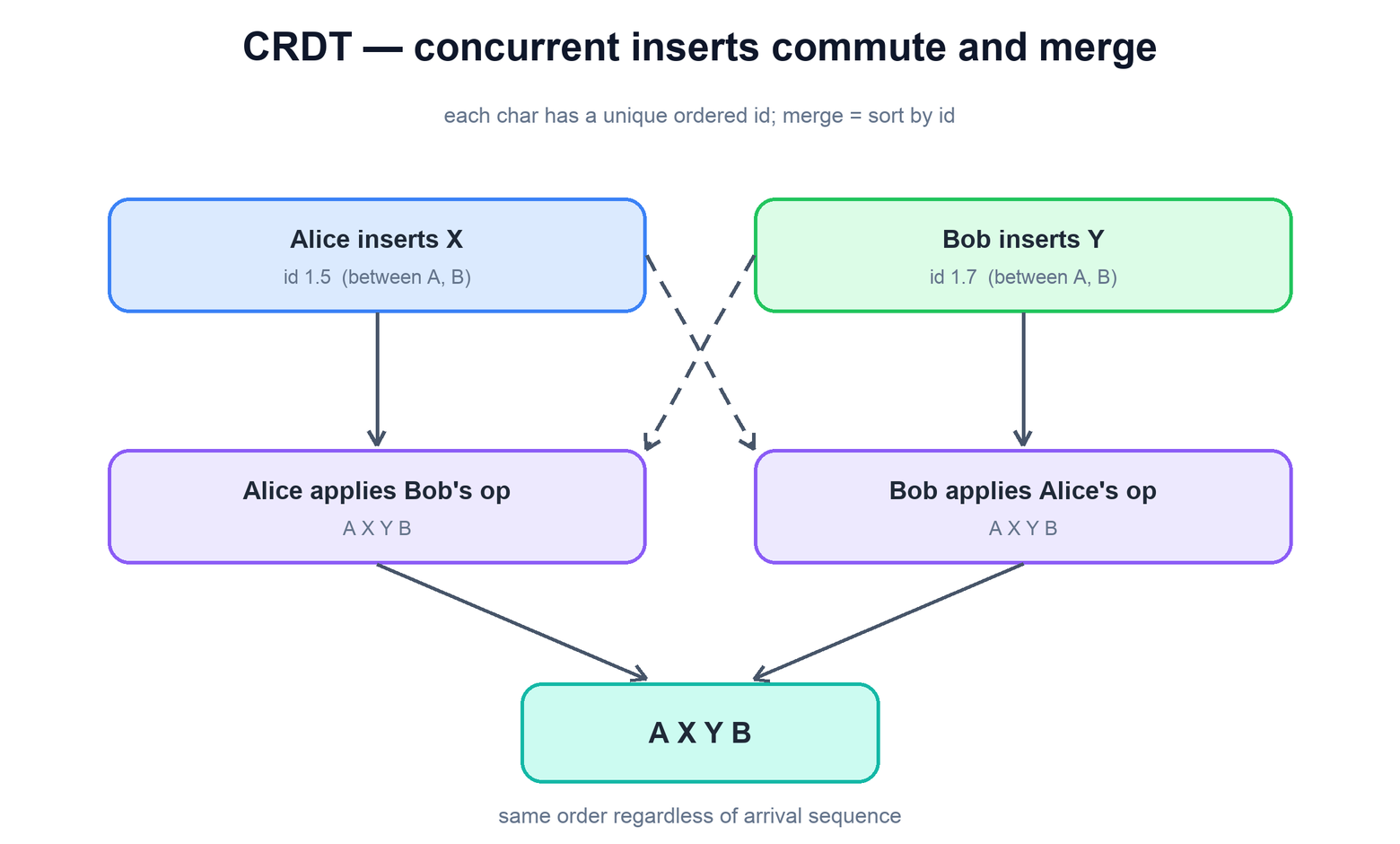
The headline benefit is that CRDTs do not require a central coordinator to be correct. Any client can merge any other client's operations directly, which makes them a natural fit for peer-to-peer and offline-heavy designs. The cost is metadata: every character carries an identifier (and usually a tombstone marker when deleted, since you cannot truly remove a character without breaking the ids that reference its neighbors). For a large, heavily edited document this overhead can dwarf the actual text, and a lot of CRDT engineering goes into compressing ids, garbage-collecting tombstones, and keeping the per-character bookkeeping small.
# CRDT insert: generate an id strictly between two neighbors
function insert_between(left_id, right_id, char):
new_id = mid(left_id, right_id) # e.g. 1.0 and 2.0 -> 1.5
chars.add({id: new_id, char: char})
function merge(remote_chars):
chars = chars UNION remote_chars # union always commutes
return sorted(chars, by=id) # same order on every replica4. Central Server vs Peer-to-Peer
Whichever convergence strategy you pick, you still have to decide how operations physically get from one client to another. The two ends of the spectrum are a central sequencing server and a true peer-to-peer mesh, and the choice interacts heavily with OT versus CRDT.
| Topology | How ops flow | Fits best with |
|---|---|---|
| Central sequencing server | Every client sends ops to one server, which assigns a global order and rebroadcasts. The server is the single source of truth. | OT, which leans on a total order; also simplifies persistence, auth, and access control. |
| Peer-to-peer | Clients exchange ops directly (or through a relay) with no authoritative ordering; each peer merges independently. | CRDTs, which converge without coordination and tolerate any arrival order. |
In practice the overwhelming majority of production systems, including Google Docs, choose a central server even when the underlying data type could go peer-to-peer. A central server is not only the natural home for OT's total ordering — it is also where you do all the boring-but-essential work: authenticating users, enforcing who is allowed to edit, persisting the document durably, and serving the current state to a client that just opened the doc. Pure peer-to-peer is elegant on paper but pushes authentication, persistence, and discovery onto the clients, which is rarely worth it for a document-editing product. The common pattern is therefore "CRDT or OT for correctness, central server for everything operational."
5. Sync Architecture
The concrete architecture is clients talking to a sequencing server over a persistent connection (typically a WebSocket), with the server assigning a monotonically increasing sequence number to every operation and rebroadcasting it to all connected clients. A document store behind the server holds the durable op log and periodic snapshots so that a client opening the document can be brought up to the current state quickly.
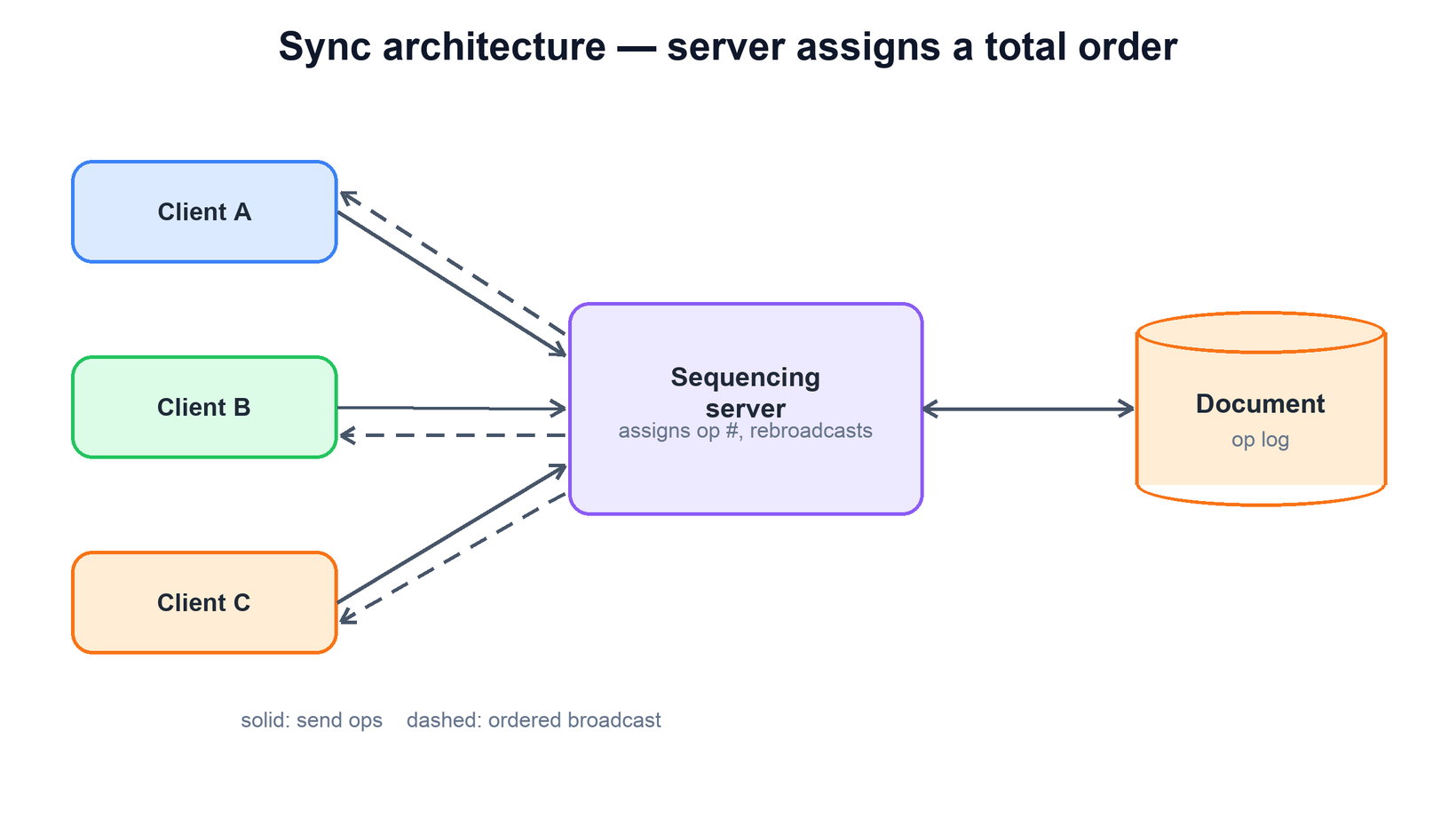
Reading the flow:
- Clients. Each applies its own edits locally and immediately, then sends them to the server as operations. It also receives the server's ordered stream and reconciles it against any of its own operations still in flight.
- Sequencing server. The heart of the design. It receives operations, assigns each a global sequence number (the total order), appends them to the durable log, and rebroadcasts them. For OT it also runs the transform; for a CRDT it can simply relay, since the ids already define the order.
- Document store. Persists the operation log so nothing is lost if the server restarts, and stores periodic snapshots so a client does not have to replay millions of operations to open a long-lived document.
# server: assign a global order, persist, then fan out
function on_operation(client, op):
op.seq = next_sequence_number() # the total order
store.append(op) # durable before broadcast
for peer in connected_clients:
if peer != client:
peer.send(op) # everyone applies same order6. Cursors and Presence
A collaborative editor is not only about text — half of what makes it feel alive is seeing where other people are. Each client broadcasts its cursor position and current text selection, usually tagged with the user's name and color, so everyone can render the little labeled carets you see floating in the document.
Crucially, presence data is treated very differently from document operations. Cursor positions are ephemeral: they do not need to be persisted, they do not need exactly-once delivery, and a dropped update just means a cursor lags for a moment. So presence typically rides a separate, best-effort channel rather than the durable op log. When a remote edit shifts text around, each client also has to remap the cursor positions it is displaying, the same way operations are transformed, so that a collaborator's caret stays attached to the right place after an insert or delete upstream of it.
7. Offline Edits and Reconnection
Because clients edit optimistically against their local copy, they can keep working with no network at all — the document is fully usable offline, and edits simply queue up locally. The interesting part is reconnection. When the client comes back, it has a batch of local operations the server never saw, and the server has a batch of operations from everyone else that the client never saw. The job is to reconcile the two without losing or duplicating anything.
With OT this means the client transforms its queued operations against the stream of operations the server applied while it was away, then sends the transformed operations up. With a CRDT it is simpler: the client merges the remote operations and ships its own, and the commutativity guarantee means order does not matter. Either way the client must track which server sequence number it last saw, so on reconnect it can ask the server for "everything after N" and the server can correctly position the client's queued edits relative to the global order.
# on reconnect: catch up, then flush queued local ops
function on_reconnect():
remote = server.fetch_ops_since(last_seen_seq)
for op in remote:
apply(op) # catch up to current state
for op in pending_local_ops:
op = transform_against(op, remote) # OT: rebase local edits
server.send(op) # CRDT: just send, ids commute8. Tradeoffs
The OT-versus-CRDT decision is the one an interviewer most wants you to reason about out loud. Neither is strictly better; they trade complexity in different places.
| Dimension | Operational Transformation | CRDT |
|---|---|---|
| Core idea | Transform ops against concurrent ops at apply time. | Design ops so they commute and merge automatically. |
| Coordination | Usually needs a central server for total ordering. | Converges without a coordinator; peer-to-peer friendly. |
| Main cost | Transform functions are subtle and easy to get wrong. | Per-character id and tombstone metadata overhead. |
| Offline tolerance | Workable but needs careful rebasing on reconnect. | Excellent — merges any divergence in any order. |
| Maturity | Decades of production use (e.g. classic Docs). | Newer, increasingly popular for local-first apps. |
The short version for an interview: choose OT when you already have a reliable central server and want a compact on-the-wire format, accepting the burden of getting the transform rules right. Choose a CRDT when you want decentralization, strong offline support, or simpler reasoning about convergence, and you can afford the metadata. Many modern systems even blend the two — using a central server for ordering and persistence while leaning on CRDT-style ids to make merges trivial.
9. Summary
Collaborative editing is a replicated data structure that must converge no matter how edits interleave. The design is a few reinforcing decisions:
| Concern | Mechanism |
|---|---|
| What is the hard requirement? | Convergence — every copy of the document ends identical despite concurrent, out-of-order edits. |
| How do we represent a change? | Small position-aware operations (insert/delete) that capture intent, not whole-document snapshots. |
| How do concurrent edits reconcile (approach A)? | Operational Transformation: transform each op against concurrent ops, usually ordered by a central server. |
| How do concurrent edits reconcile (approach B)? | CRDTs: unique ordered ids make operations commute and merge with no coordinator. |
| How do ops travel between clients? | A central sequencing server assigns a total order and rebroadcasts; peer-to-peer is possible with CRDTs. |
| How do we keep nothing lost? | A document store holding a durable op log plus periodic snapshots for fast joins. |
| How do we show collaborators? | Ephemeral cursor/selection presence on a separate best-effort channel. |
| How do we handle offline work? | Edit locally, track last-seen sequence, then catch up and rebase/merge on reconnect. |
| OT or CRDT? | OT for compactness with a central server; CRDT for decentralization and offline, at a metadata cost. |