Designing an Ad Click / Impression Counter
A system design interview guide to counting billions of ad impressions and clicks per day accurately enough to bill on, while still surfacing fresh numbers on a dashboard within seconds.
Counting sounds like the simplest thing a computer can do, and at small scale it is — increment a number in a database and move on. The problem becomes interesting precisely because of scale and money. An ad platform serves an enormous volume of impressions and clicks, and those counts are not a vanity metric: advertisers are billed against them and the platform's revenue is computed from them. That raises the bar from "roughly right" to "defensibly correct," while the sheer write rate makes the naive "increment a row" approach fall over almost immediately. This guide builds up a design that counts at very high volume, deduplicates so a single click is never billed twice, tolerates events that arrive late or out of order, and reconciles itself to an exact answer that you can stand behind in an invoice.
Contents
1. The Scale of Writes
The first number to establish in an interview is the write rate, because it dictates almost every later decision. A large ad platform might serve on the order of hundreds of thousands to millions of impressions per second at peak, with clicks a couple of orders of magnitude rarer but still very high in absolute terms. Each of those is a discrete event that the counting system must observe. There is no batching at the source — the events stream in continuously, all day, with diurnal peaks and occasional spikes from large campaigns.
At that rate the naive design — "on every event, run UPDATE counts SET n = n + 1 WHERE ad_id = ?" — is dead on arrival. A single row per ad becomes a contention hotspot; the database cannot sustain millions of write transactions per second; and you would be paying transactional durability costs on every single increment. The realization that drives the architecture is that you do not need to durably persist a final count on every event. You need to durably capture the raw event cheaply, and then aggregate it asynchronously. Capture and counting are separate problems with separate performance profiles.
| Quantity | Rough order | Why it matters |
|---|---|---|
| Impressions / sec | Hundreds of thousands to millions | Sets the ingestion throughput the pipeline must absorb without dropping events. |
| Clicks / sec | Thousands to tens of thousands | Rarer but the revenue-critical events; dedup matters most here. |
| Distinct ads | Millions of active creatives | The cardinality of the keyspace you aggregate over (per-ad, per-minute). |
| Daily events | Tens of billions | Drives storage sizing for raw logs and the cost case for rollups. |
2. What We Count
Before designing the plumbing, be precise about the quantities, because their definitions affect both correctness and the data model. Three things are in play, and they are not independent.
- Impressions. An ad was shown to a user. This is the high-volume denominator — the count of times a creative was rendered and surfaced. Definitions matter here (was it viewable? for how long?), and in a real system the client emits a well-defined impression event so the counter does not have to guess.
- Clicks. A user interacted with the ad. Far rarer than impressions, and the event that usually triggers billing in a cost-per-click model. Because each click can carry real money, a click event must be counted exactly once.
- Click-through rate (CTR). The ratio of clicks to impressions for a given ad over a given window. CTR is a derived quantity — you do not store it directly; you store the two counts and divide at query time. Keeping it derived avoids a third number that can drift out of sync with its inputs.
The key design consequence is that you count impressions and clicks as two separate event streams keyed the same way (per ad, per time bucket), and you compute CTR on read. That keeps the write path uniform — both are "count this event into this bucket" — and keeps the reported ratio always consistent with the counts it is built from.
3. The Hard Parts
It is worth naming the difficulties explicitly, because the architecture exists to answer each of them in turn. An interviewer is really probing whether you see past the word "count."
- Extreme write rate. Already covered — you cannot synchronously persist a final count per event, so you must decouple ingestion from aggregation.
- Deduplication. The same logical click can be reported more than once: clients retry on a flaky network, at-least-once queues redeliver, and bots or double-taps generate spurious repeats. Counting a click twice means over-billing an advertiser, which is both a correctness bug and a trust problem. Each event must be counted once.
- Late and out-of-order events. Events do not arrive in the order they happened. A mobile client that was offline may upload an impression from ten minutes ago; network paths reorder messages. A counter that closes a minute bucket the instant the clock ticks over will miss events that belong to that minute but show up afterward.
- Accuracy versus freshness. A dashboard wants numbers now; billing wants numbers that are exactly right. These goals conflict: the freshest number cannot have waited for every late event, and the exact number cannot be instantaneous. The design resolves this by serving both — a fast approximate path and a slow exact path — rather than pretending one number satisfies both.
4. Streaming Aggregation Pipeline
The backbone of the design is a streaming pipeline that separates the four concerns — capture, buffer, aggregate, serve. Each stage has one job and can be scaled independently of the others.
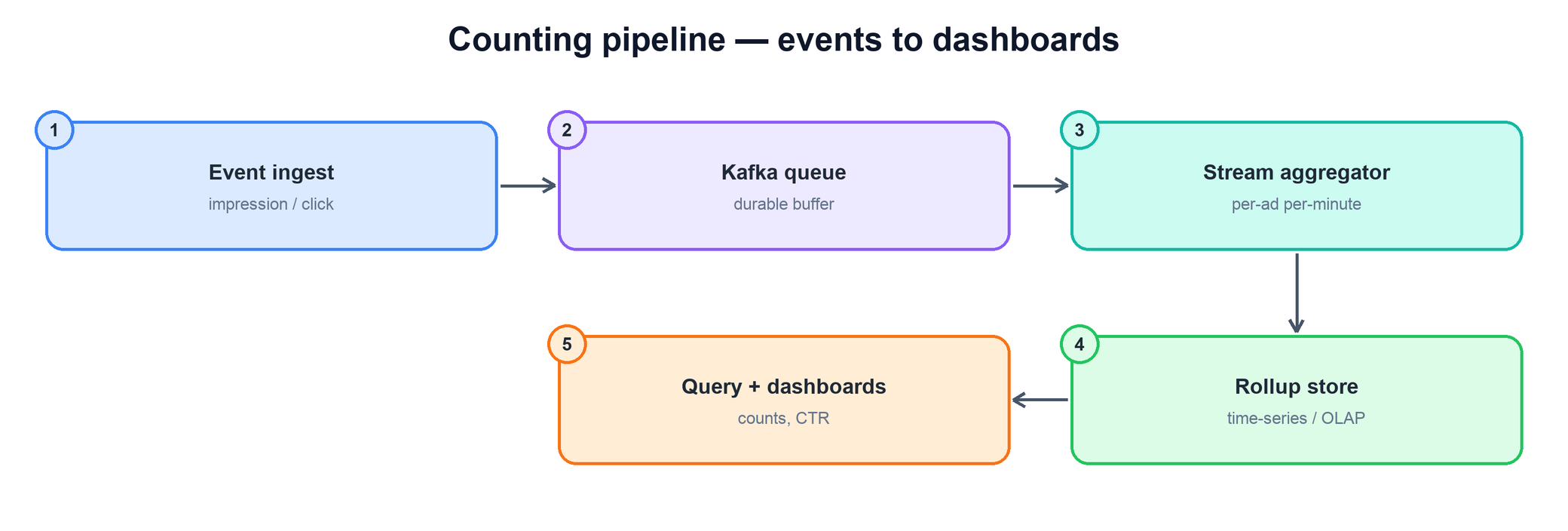
Walking the stages from left to right:
- Event ingest. Lightweight collectors receive impression and click events from clients and ad servers. Their only job is to validate and forward — they do no counting. This keeps the front edge cheap and horizontally scalable, which is what lets it absorb millions of events per second.
- Kafka queue. Events are written to a durable, partitioned log. This is the linchpin: it absorbs spikes, decouples the fast producers from the slower aggregators, and — crucially — gives you a replayable record of every raw event. Partitioning by ad id keeps all events for one ad on one partition, so a single consumer owns that ad's counts and never races another.
- Stream aggregator. A pool of consumers reads the queue and maintains running counts grouped by (ad id, minute bucket). Rather than touching a database per event, each consumer holds in-memory counters and flushes a small rollup row per ad per minute. Millions of raw events collapse into a few count rows.
- Rollup store. The flushed per-minute counts land in a store built for this shape of data — a time-series database or a columnar OLAP store — that handles append-heavy writes and fast range-and-group queries.
- Query and dashboards. Dashboards and reporting APIs read aggregated counts from the rollup store and compute CTR on the fly. They never touch the raw event stream.
function on_event(event):
validate(event) # reject malformed
kafka.produce(topic=event.type, # "impression" or "click"
key=event.ad_id, # same ad -> same partition
value=event) # durable, replayable
function aggregator_loop():
counts = {} # (ad_id, minute) -> n, in memory
for event in kafka.consume():
if seen(event.event_id): continue # dedup, see next section
bucket = floor_to_minute(event.ts)
counts[(event.ad_id, bucket)] += 1
if flush_due():
rollup_store.upsert(counts) # compact per-minute rows
counts.clear()5. Deduplication by Event ID
The single most important correctness mechanism is that every event carries a unique event id assigned at the source, and the aggregator counts an id at most once. Without this, the at-least-once nature of the queue and client retries would inflate every count.
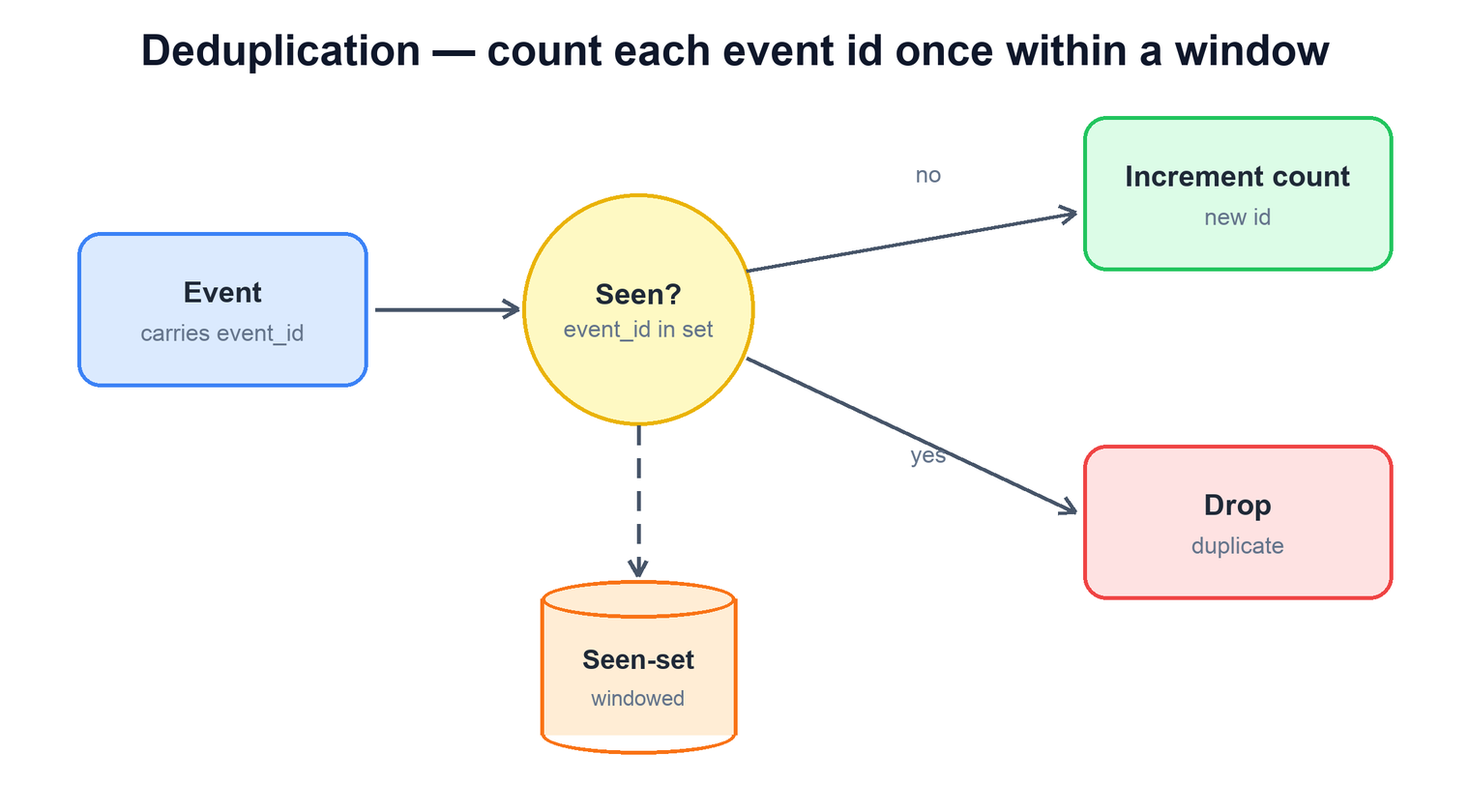
The check sits directly in front of the increment. When an event arrives, the aggregator asks whether it has seen that event id recently. If not, it counts it and adds the id to a "seen" set; if it has, it drops the event. The subtlety is the word recently: you cannot remember every id ever seen — that set would grow without bound. Instead you keep a windowed set, large enough to cover the realistic gap between the original event and any retry (minutes, not days), and let older ids expire. Duplicates that somehow arrive beyond the window are rare, and the batch reconciliation pass (below) catches them.
function should_count(event):
if seen_set.contains(event.event_id):
return False # duplicate: drop, don't bill twice
seen_set.add(event.event_id, ttl=WINDOW) # windowed; old ids expire
return True6. Rollups and Pre-Aggregation
Storing one row per raw event would be ruinous at tens of billions of events a day, and querying it for a dashboard would be hopeless. The answer is to pre-aggregate into rollups at increasing granularity, so each query reads the coarsest tier that can answer it.
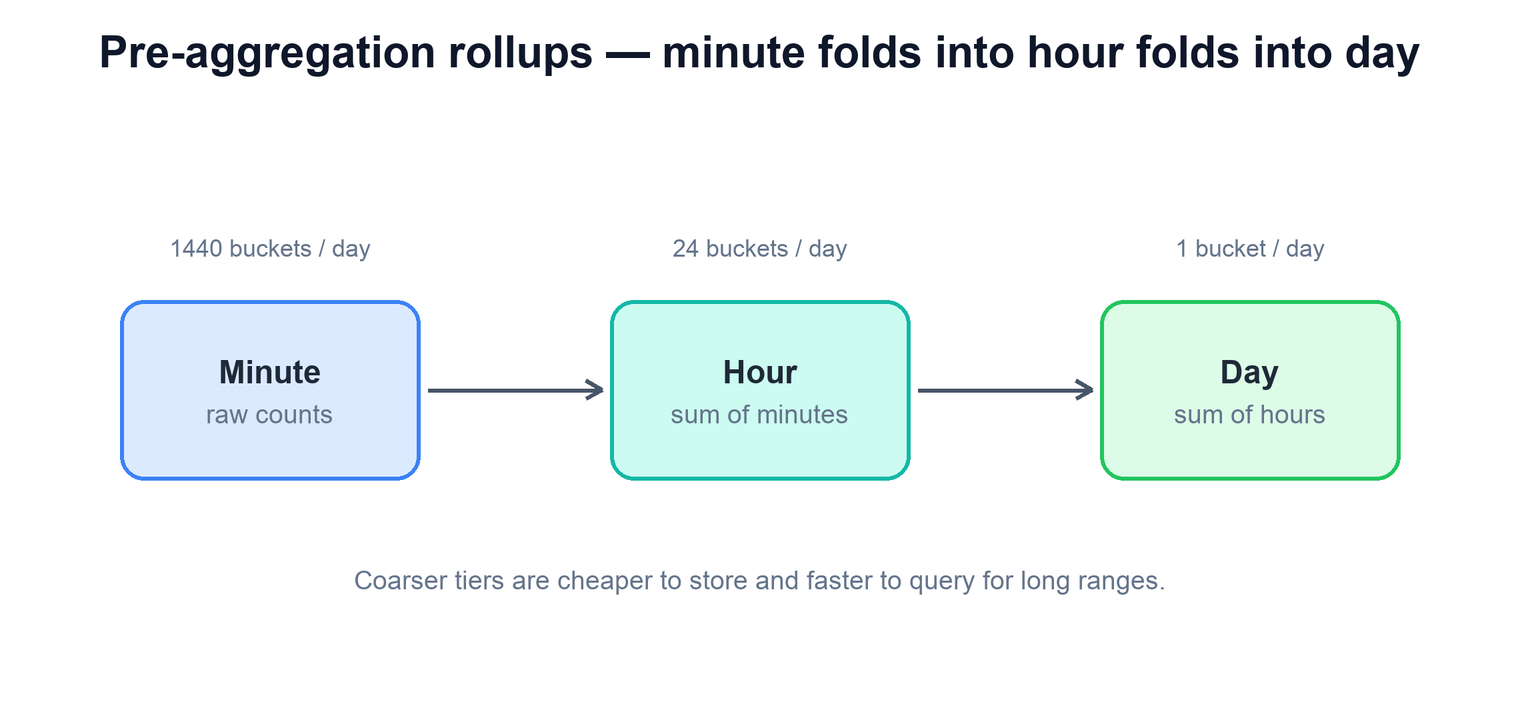
The aggregator produces the finest tier — per ad, per minute. A rollup job then folds minutes into hours and hours into days. The arithmetic is trivial because counts are additive: an hour is just the sum of its sixty minutes. The payoff is in row count and query cost. A "last 30 days" report for an ad reads thirty day-rows instead of forty-three thousand minute-rows. You keep the fine-grained minute tier only for a short recent window (where people zoom in), and let the coarse tiers carry the long history.
| Tier | Buckets per day per ad | Good for |
|---|---|---|
| Minute | 1440 | Recent, fine-grained dashboards; live monitoring of a campaign. |
| Hour | 24 | Day-level trends without minute noise; intraday reporting. |
| Day | 1 | Long-range reports, billing summaries, historical retention. |
7. Late and Out-of-Order Events
Because events arrive out of order, the aggregator cannot treat a minute bucket as final the instant the wall clock leaves that minute. The standard tool is a watermark with a grace period: a minute bucket stays open and accepting late arrivals for a while after it ends, and only then is its count flushed as provisional. An event stamped with a time inside an already-flushed bucket is not dropped; it is applied as a correction to that bucket.
This is why every event carries its own event timestamp from the source, and the aggregator buckets by that timestamp rather than by arrival time. Arrival-time bucketing would scatter an offline client's ten-minute-old events into the wrong minute. Event-time bucketing plus a grace window keeps them in the bucket they belong to, at the cost of a short delay before a bucket's count settles.
function assign_bucket(event):
bucket = floor_to_minute(event.ts) # event time, not arrival time
if now() - bucket > GRACE + BUCKET:
rollup_store.add_correction(event.ad_id, bucket, +1) # late: fix the closed bucket
else:
open_buckets[(event.ad_id, bucket)] += 1 # still within graceThe grace period is a deliberate trade. A longer grace catches more stragglers before flushing, improving the freshly reported number, but delays when a bucket's count appears. A shorter grace makes counts appear sooner but relies more on corrections (and ultimately on reconciliation) to reach the true value. Either way, the streaming counts are explicitly provisional — which sets up the final piece.
8. Batch Reconciliation
The streaming path is fast but approximate: it can miss very late events, mishandle a rare dedup edge case across a window boundary, or carry a small error from a consumer that crashed and resumed. For numbers you will bill on, you need a path that is slow but exact. This is the classic lambda-style arrangement — a real-time layer for freshness alongside a batch layer for correctness.
Because every raw event was durably written to the queue (and archived to long-term storage), you have a complete, replayable record. A periodic batch job — say, hourly or daily — reads the full set of raw events for a closed period, deduplicates globally (no window limitation, since it sees everything at once), aggregates exactly, and writes the authoritative counts. Where the batch result disagrees with the streaming rollup, the batch value wins and the rollup is corrected.
function reconcile(period):
raw = event_archive.read(period) # every raw event for the period
uniq = dedup_by_event_id(raw) # global dedup, no window limit
exact = group_and_count(uniq, by=[ad_id, minute])
rollup_store.overwrite(period, exact) # batch is authoritative
emit_billing_counts(exact) # numbers we invoice on9. Billing-Grade Accuracy
Counts that money depends on carry obligations beyond ordinary metrics, and an interviewer will reward you for naming them. The system is not just counting; it is producing an auditable financial record.
- Exactly-once where it counts. Click counts feed invoices, so the dedup-plus-reconciliation combination must guarantee each billable event is counted once. Over-counting over-bills advertisers; under-counting under-collects revenue. Both are unacceptable, which is why the exact batch path exists rather than trusting streaming alone.
- Auditability. Because raw events are retained, any billed number can be traced back to the underlying events. When an advertiser disputes a charge, you can reconstruct the exact set of clicks that produced it. The raw log is the audit trail.
- Fraud and invalid-traffic filtering. Not every click is billable — bots, accidental double-taps, and click fraud must be filtered out before a click is counted toward billing. This filtering typically runs as part of (or just before) the reconciliation pass, where there is time to apply heavier heuristics than the real-time path can afford.
- Provisional versus final. Make the distinction explicit to consumers. Dashboards label recent counts as provisional; billing uses only finalized, reconciled counts for a closed period. Never invoice on a number that is still inside its grace window.
10. Summary
An ad click and impression counter is a stream-processing system whose every decision is shaped by two pressures that pull apart — enormous write volume and money-grade accuracy.
| Concern | Mechanism |
|---|---|
| How do we absorb millions of events per second? | Decouple capture from counting: cheap ingest, durable queue, asynchronous aggregation. |
| What do we actually count? | Impressions and clicks as two event streams keyed per ad per minute; CTR derived on read. |
| How do we count each event once? | Source-assigned event id checked against a windowed seen-set before incrementing. |
| How do we serve dashboards cheaply? | Pre-aggregated rollups, minute → hour → day, query the coarsest tier that fits. |
| How do we handle late and out-of-order events? | Bucket by event time with a watermark grace period; apply corrections to closed buckets. |
| How do we get an exact answer? | A lambda-style batch reconciliation job replays the raw log and overwrites with exact counts. |
| How do we bill safely? | Exactly-once on billable events, retained raw log for audit, invalid-traffic filtering, provisional vs final labels. |